目次
こんにちは.高山です.
以前の記事でMediaPipeの全身追跡機能を,指文字動画に対して適用した例を紹介しました.
今回はその際に使用したプログラムについて解説したいと思います.
なお,高山は普段自前PCに入れたLinux環境で検証をしていますが,今回は解説のためにGoogle Colaboratoryを使用しています.
今回解説するスクリプトはGitHub上に公開しています.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/17: タイトルとタグを更新しました
1. モジュールのインストールとロード
第1節ではモジュールのインストールとロードを行っています.
1.1 MediaPipeのインストール
初期状態のColab環境にはMediaPipeがインストールされていません.
そこでまず最初に,Colab環境にMediaPipeをインストールします.
Colab環境では,先頭に"!"付けるとその行はShellコマンドとみなされます.
下のコードでは,Pythonのパッケージ管理ツール pip を呼び出してMediaPipeのバージョン"0.10.0"をインストールしています.
!pip3 install mediapipe==0.10.0
1.2 利用モジュールのインポート
次のコードでは使用するモジュールをインポートしています.
この操作によって,各モジュールに実装されている機能を利用できるようになります.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
【コード解説】
- 標準モジュール
- copy: 変数,オブジェクトのコピー機能
- os: ファイルの作成,削除などOSが提供する機能
- 画像処理・機械学習向けモジュール
- cv: 画像処理ライブラリOpenCVのPython版
- numpy: 行列演算ライブラリ
- holistic: MediaPipeの全身追跡機能
- 描画処理向けモジュール
- FACEMESH_CONTOURS: MediaPipe向け顔追跡点の接続関係を定義したデータ
- HAND_CONNECTIONS: MediaPipe向け手追跡点の接続関係を定義したデータ
- POSE_CONNECTIONS: MediaPipe向け身体追跡点の接続関係を定義したデータ
- HTML: 生データをロードしてHTML形式に変換する機能.今回は動画を描画するために使用
- b64encode: データをbase64形式に変換する機能.
base64はデータをアルファベット,数字,記号の64文字で表すデータ形式
- io: データやファイルに対する入出力機能.標準モジュールだが今回は動画を読み込むために使用
2. 動画データのロードと確認
第2節では,テスト用の動画ファイルをダウンロードしています.
2.1 動画ファイルのダウンロード
今回使用した動画ファイルは,GitHub上に公開しています.
!wget https://github.com/takayama-rado/trado_samples/raw/main/test_data/finger_far0.mp4
ls コマンドで動画がダウンロードされているか確認します.
!ls
finger_far0.mp4 sample_data
2.2 動画を描画して確認
次のスクリプトはColab上で動画を描画する機能を実装しています.
1 2 3 4 5 6 7 8 | |
【コード解説】
- 引数
- video_path: 入力動画のパス
- video_width: 動画表示領域の幅
- video_height: 動画表示領域の高さ
- 2行目: 動画ファイルをオープン
- 3-4行目: 生データを一旦base64形式に変換し,さらにASCII文字列に変換
- 5-7行目: HTMLのvideoタグを表す文字列を定義
- 8行目: dataをHTML形式に変換して返す
次のコードでダウンロードした動画をColab上に表示しています.
show_video() の返り値がHTMLオブジェクトのため(videoタグ),埋め込み動画が表示されます.
show_video("./finger_far0.mp4")
3. 追跡処理
第3節では,追跡処理を行っています.
この処理では,動画を入力して追跡点配列を出力します.
処理の構成図を図1に示します.
最初にMediaPipeのHolisticクラスを生成し (インスタンス化),動画ファイルを開きます.
次に,開いた動画ファイルから1フレーム分の画像データを読み込みます.
読み込みが成功した場合は,画像データに対して追跡処理を行い,座標値のスケーリング後にデータを成形します.
ここでは,追跡点が \([P, T, J, C]\) 形状になるように成形しています.
\(P, T, J, C\) は,それぞれ人物番号,フレーム番号,追跡点番号,特徴量インデクスを示します.
全身追跡機能は1名だけしか追跡できないので \(P\) 次元は不要なのですが,他の追跡機能と互換性を持たせるためにこのような設計にしてあります.
上の処理を全フレームに対して行い,読み込むフレームがなくなったら追跡点データを保存して処理を終了します.
では,コードの解説をしていきます.
追跡のメイン処理に先立って,メイン処理から呼び出される関数群を実装します.
3.1 追跡点の抽出
次のコードは,MediaPipeで抽出した追跡点群をNumpy配列に変換しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
【コード解説】
- 引数
- result: 追跡結果データ
- 3-6行目: 部位毎に追跡点を格納する配列を $[P, T, J, C]$ 形状で初期化.
後の処理における取り扱いを考えて,追跡に失敗した場合はゼロ埋めされるように初期化しています.
- 7-11行目: 身体追跡点を格納
身体追跡点は追跡結果データに `pose_landmarks.landmarks` として格納されています.
- 15-16行目: 座標値に基づいて2値信頼度を返す関数を実装.
手および顔の追跡点には身体追跡点の `visibility` に相当する変数がありません.
互換性をもたせるために,座標値をもとに `visibility` を返す関数を実装しています.
- 18-32行目: 手および顔の追跡点を格納
追跡結果の仕様については公式ドキュメントをご参照ください.
リンク先の中央付近,"Output"の項に結果データの仕様が記載されています.
3.2 追跡点のスケーリング (投影)
次のコードは,追跡点の座標値を画像サイズにスケーリングしています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
【コード解説】
- 引数
- kpts: `[P, T, J, C]` 形状の追跡点配列
- width: スケーリングするウィンドウ幅
- height: スケーリングするウィンドウ高さ
- inplace: `True` の場合,入力 `kpts` を上書きする
- limit_to_window: `True` の場合,画像外にはみ出した値を画像境界線上に留める
- 6-9行目: `inplace=True` の場合は,入力 `kpts` を上書きするように `temp` を初期化
- 10行目: `width` と `height` の大きい方の値で,`z` 軸のウィンドウサイズを定義
- 11-16行目: ウィンドウサイズで座標値をスケーリング.
MediaPipeの座標値は画像サイズを $[0, 1]$ の範囲で正規化した値です.
そのため,ウィンドウサイズをかけるだけでスケーリングができます.
- 17-23行目: `limit_to_window=True` の場合は,画像外にはみ出した値を画像境界線上に留める
- 24-26行目: 返り値の作成
3.3 追跡メイン処理
ここから先は,追跡のメイン処理を実装しています.
まず最初に,MediaPipeのHolisticクラスをインスタンス化します.
Holisticクラスの初期化変数については,以前の記事または公式ドキュメントをご参照ください.
1 2 3 4 5 6 7 8 9 10 11 | |
次に,メインループを実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
【コード解説】
- 1-2行目: 入出力パスの設定
- 5-6行目: 動画ファイルオープン
- 7行目: 追跡点配列格納用変数の初期化
- 8-29行目: メインループ
- 9-11行目: 画像フレーム読み込み.読み込みができない場合はループを抜ける
- 14行目: Holisticクラスを用いて画像から追跡点を生成
- 15行目: 追跡点の抽出と成形
- 16-21行目: 追跡点のスケーリング
- 23-27行目: 過去の追跡点配列と現フレームの追跡点を結合
- 31-34行目: 追跡点を保存
最後に,下記のコードで保存された追跡点をロードして表示しています.
np.load(output)
4. 結果の描画
第4節では,追跡点の描画処理を行っています.
この処理では,動画と追跡点配列を入力します.
入力動画は背景を描画するために使い,フレーム毎に追跡点位置を示す円と,追跡点間の接続関係を示す直線を上書き描画します.
最終的に,描画結果は動画ファイルとして出力されます.
処理の構成図を図2に示します.
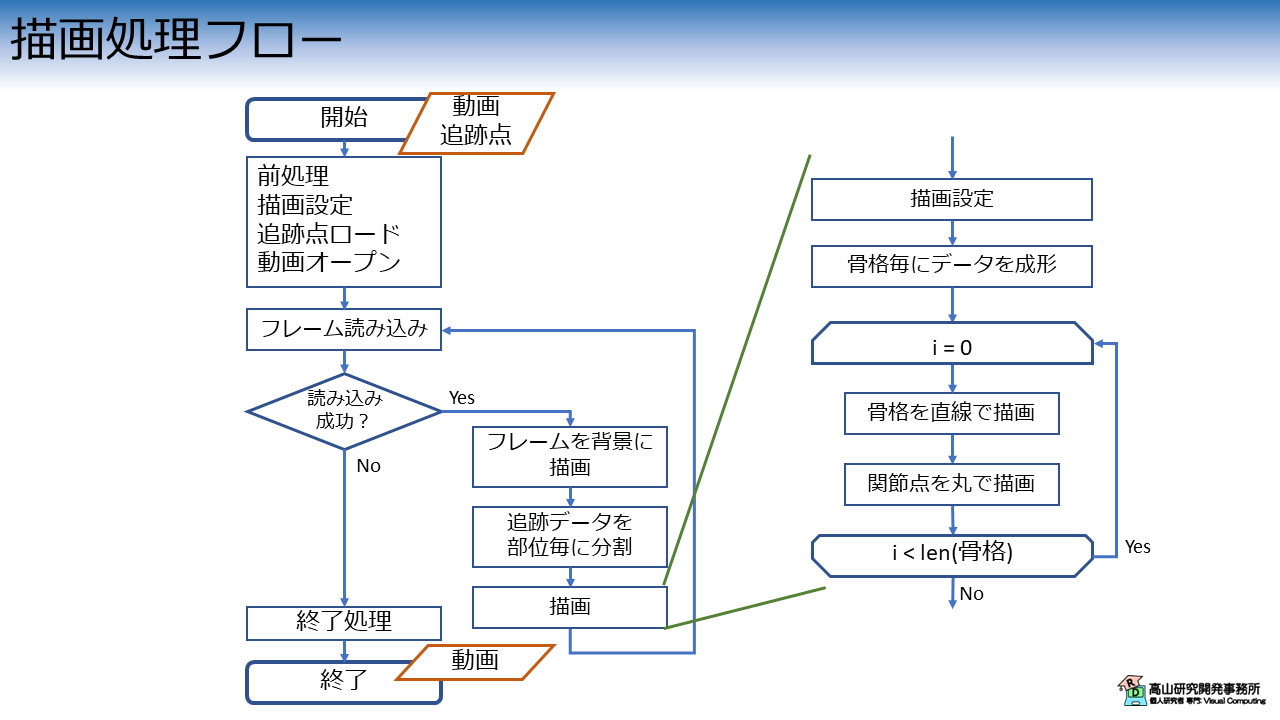
最初に,前処理としてファイルのロード,動画のオープン,およびウィンドウサイズや描画位置の調整を行います.
次に,開いた動画と追跡点から1フレーム分のデータを取り出します.
画像データを背景としてウィンドウに描画し,その後に追跡点を描画します.
この処理を全フレーム分行い,読み込むデータがなくなったら動画を保存して処理を完了します.
では,コードの解説をしていきます.
描画のメイン処理に先立って,メイン処理から呼び出される関数を実装します.
4.1 追跡点の描画
次のコードは,描画ウィンドウに対して追跡点を描画しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
【コード解説】
- 引数
- draw: 描画領域.背景は既に描画済みの想定です.
- landmarks: 追跡点配列
- connections: 追跡点間の接続関係.
接続関係は `[[0, 1], [1, 2], ...]` のように追跡点インデクスのペアの配列になっています.
- pt_color: 追跡点の描画色 (BGR)形式
- line_color: 追跡点間の描画色 (BGR)形式
- pt_size: 追跡点の描画サイズ
- line_size: 追跡点間の描画サイズ
- do_remove_error: `True` の場合,追跡に失敗している点は無視する
- 5-7行目: 追跡点間の接続関係と,対応関係になっている2点を抽出
追跡点の描画には $(x, y)$ 座標だけを用います.
- 8-12行目: 追跡に失敗した点をスキップ
`Nan` や座標値が `0` になっている場合は描画をスキップします.
- 13-17行目: 追跡点の接続関係を直線で描画し,追跡点を円で描画
4.2 描画メイン処理
ここから先は,描画のメイン処理を実装しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 | |
【コード解説】
- 1-2行目: 入力ファイルパスを設定
動画ファイルは追跡処理の出力パスをそのまま使用します.
- 3-13行目: 追跡点ファイルと動画ファイルをロード
動画ファイルのオープンに成功した場合は,読み込み位置を先頭フレームに設定し,画像幅と画像高さを読み込みます.
- 15-25行目: 追跡点座標の最大値と最小値を算出
この値はウィンドウサイズと描画位置の調整に用います.
また,先の追跡処理でスケーリングをしていない場合は,19-21行目で再度スケーリングを行います.
- 27-41行目: ウィンドウサイズと描画位置の調整
この処理によって追跡点座標が負の値や画面外の値になっている場合でも描画できるようになります.
- 43-49行目: 出力用の動画ファイルをオープン
オープンに失敗した場合は例外を投げて中断します.
- 52-78行目: メインループ
- 52行目: 時間次元に沿ってループ処理を行うために,追跡点配列の第1次元と第2次元を入れ替え
- 54-63行目: 画像フレームを読み込み,背景を描画
入力動画をオープンしていない場合は白背景を設定します.
- 65行目: 人物毎に追跡点を描画
全身追跡モードは複数名の追跡に未対応なためここでのループは不要なのですが,他の追跡処理と互換性をもたせるためにこのような処理になっています.
- 66-77行目: 部位毎に追跡点を描画
追跡点の接続関係は部位毎に定義されているため,一旦追跡点を部位毎に分割して,それぞれ異なる色で描画しています.
- 78行目: 描画フレームを動画ファイルに書き出し
- 79-81行目: 動画の保存および終了処理
最後に,描画結果を表示して確認をします.
OpenCVを使って作成した動画ファイルはColab環境上では上手く表示できなかったため,FFMPEGを使用して変換を行います.
!ffmpeg -i finger_far0_track.mp4 -vcodec vp9 -y finger_far0_track.webm
その後,次のコードで動画ファイルの描画を行います.
show_video("./finger_far0_track.webm")
今回はMediaPipeの全身追跡機能を使ったプログラムの解説を行いましたが,如何でしょうか?
各種の設定ごとの分岐や,一部のエラー処理もそのまま入れているため少し冗長だったかもしれません.
追跡点を認識などの各種応用に使う場合は,実際の追跡結果を可視化して処理を設計していくことが非常に重要です.
今回紹介した話が,これから追跡機能を使おうとお考えの方に何か参考になれば幸いです.