こんにちは.高山です.
今回の記事は,Conformer を用いた孤立手話単語認識 (以降では実験記事と記載します) の補足になります.
以前の記事で Conformer [Gulati'20] を用いた孤立手話単語認識を紹介しました.
このときは全体の実装と実験結果を中心として説明し,Convolution module については簡単な説明でとどめていましたので,本記事で補足説明をさせていただきたいと思います.
Conformer の論文は 5 ページと短く,設計思想についてあまり細かな説明が乗っていません.
構成をいじってみたら性能が上がったりしないかな?,と思い追加で実験を行いました.
結論を先に述べますと,特に改善は見られませんでした (^^;).
もしかしたら同じような発想をする方がいらっしゃるかもしれませんので,本記事の後半に実験結果を載せておきます.
- [Gulati'20]: A. Gulati, et al., "Conformer: Convolution-augmented Transformer for Speech Recognition," Proc. of the Interspeech, available here, 2020.
更新履歴 (大きな変更のみ記載しています)
- 2024/10/04: 実験記事の修正を受けて,再度実験を行い,表現を修正しました.
- 2024/09/17: タグを更新しました
1. Conformerについておさらい
1.1 全体構成
まず最初に,Conformer [Gulati'20] のおさらいをしたいと思います.
図1に,Macaron Net [Lu'19] から Conformer への変更点を示します.
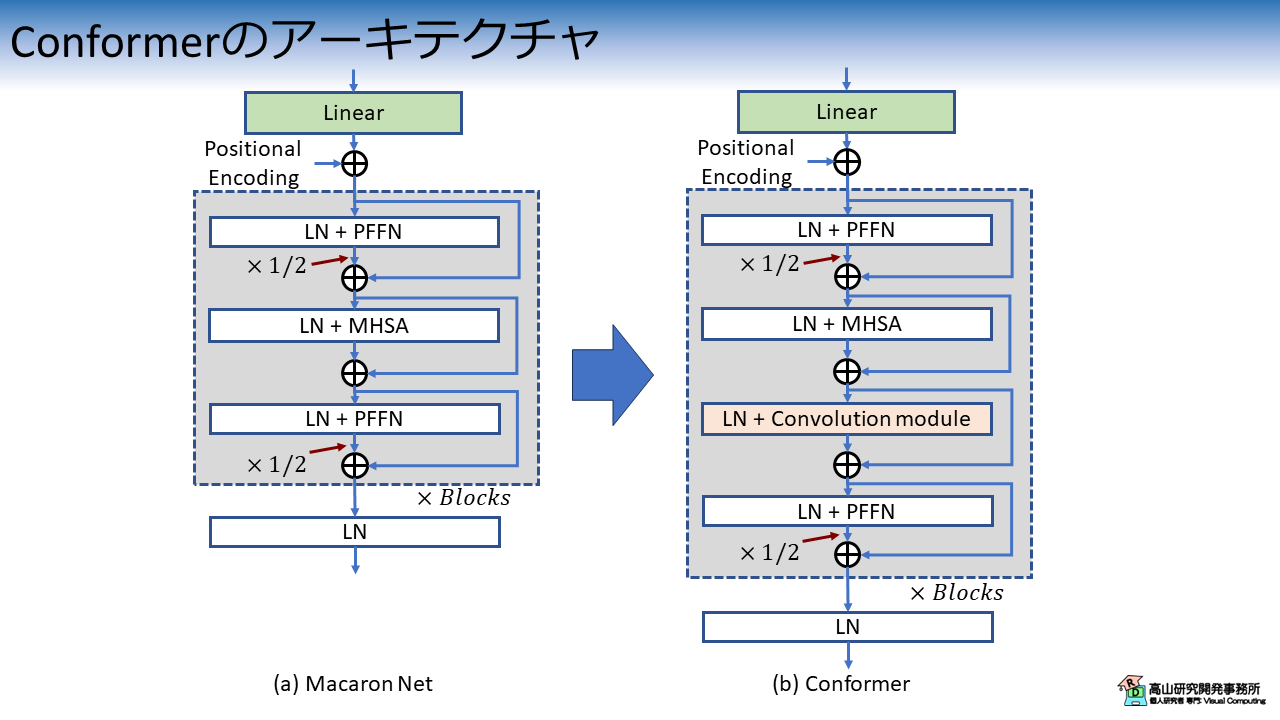
図1 の LN, PFFN, MHSA は,それぞれ Layer normalization [Ba'16],Position-wise feed forward network,および Multi-head self attention を示します.
図1(b) に示すように,Conformer では Macaron Net のアーキテクチャをベースとして,Convolution module を MHSA の後ろに追加します.
(実際には,Positional Encoding と活性化関数も変更していますが,本記事では触れません)
Transformer [Vaswani'17] の Multi-head self attention (MHSA) では,あるフレームの特徴抽出を行う際に全フレームの特徴を取り込みながら計算を行います.
一方 Conformer の Convolution module では,計算対象フレームと近接フレームの特徴を用いて特徴抽出を行います.
全体的な関係性と局所的な関係性 (文献[Gulati'20] では,それぞれ global context と local context と呼んでいます) のそれぞれに着目した特徴抽出を併用することで,相補的な効果が期待できます.
- [Gulati'20]: A. Gulati, et al., "Conformer: Convolution-augmented Transformer for Speech Recognition," Proc. of the Interspeech, available here, 2020.
- [Lu'19]: Y. Lu, et al., "Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View," arXiv:1906.02762, available here, 2019.
- [Ba'16]: J. Ba, et al., "Layer Normalization," arXiV: 1607.06450, available here, 2016.
1.2 Convolution module
Convolution module のブロック図を図2に示します.
なお,Dropout 層は省略しています.
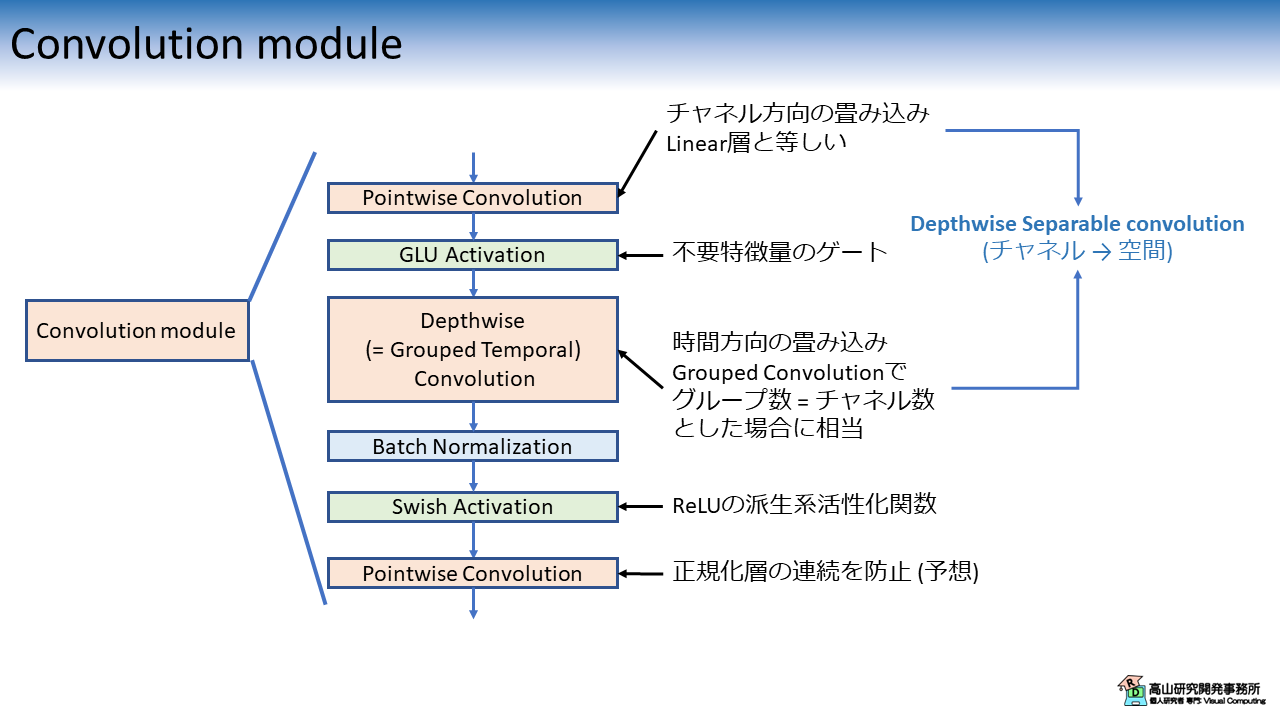
画像処理系モデルでは,Convolutionan neural network (CNN) \(\rightarrow\) 正規化層 \(\rightarrow\) 活性化関数という構成の特徴抽出ブロックがよく用いられます.
Convolution module も似た構成を採用していますが,下記の点で異なっています.
- 畳み込み層として,Depthwise separable convolution (DSCNN) [Cholet'17] と Gated linear unit (GLU) [Dauphin'17] の組み合わせを採用
- 処理ブロックの末尾で再度 Point-wise convolution を適用
大まかな説明は実験記事でしましたので,本記事では 1番目の点についてもう少し細かく説明しようと思います.
- [Chollet'17]: F. Chollet'17, et al., "Xception: Deep Learning with Depthwise Separable Convolutions," Proc. of the CVPR, available here, 2017.
- [Dauphin'17]: Y. N. Dauphin,17, et al., "Language modeling with gated convolutional networks," Proc. of the ICML, available here, 2017.
Depthwise separable convolution によるパラメータ削減
標準の CNN では,特徴次元の変更と時空間のフィルタ処理を同時に行います.
CNN の処理には次式で示す学習パラメータが必要になります.
ここで,\(C_{in}, C_{out}, K\) は,それぞれ入力の特徴次元数,出力の特徴次元数,および CNN のカーネルサイズを示します.
なお,バイアス項の学習パラメータ数と各パラメータのバイト数はここでは無視しています.
一方DSCNN では,特徴次元の変更と (チャネル毎の) 時空間フィルタ処理を,それぞれ Pointwise convolution (PCNN) と Depthwise convolution (DCNN) を用いて順番に行います.
PCNN は特徴次元の変更だけを行います.
この処理はカーネルサイズ \(K=1\) の CNN (または Linear層) を用いて行います.
PCNN の処理に必要な学習パラメータ数を次式に示します.
DCNN では,入力の各特徴次元に対して1個ずつカーネルを用意して,時空間フィルタリングだけを行います.
DCNN の処理に必要な学習パラメータ数を次式に示します.
ここから,DSCNN の学習パラメータ数は次式のように表せます.
例えば,\(C_{in} = 32, C_{out} = 64, K = 9\) であった場合,CNN と DSCNN に必要な学習パラメータ数は下記のようになります.
\(2366\) \(/\) \(18432\) \(\fallingdotseq\) \(0.128\) なので,DSCNN に必要な学習パラメータ数は CNN の\(12.8 \%\) 程度になります (\(C_{out}\) と \(K\) に依存します).
DSCNN を用いることで学習パラメータが削減できることが分かります.
なお,DSCNN は学習パラメータは削減できるのですが,高速化にはあまり結びつかないことが指摘されています [Ma'18].
Gated linear unit による効率的な特徴抽出
Convolution module の DSCNN は GLU 層 [Dauphin'17] が間に挿入されている点が特徴的です.
GLU は (LSTM などのように) ゲート機構を用いて不要な特徴量を抑制する働きをします.
GLU の処理構成を図3に示します.
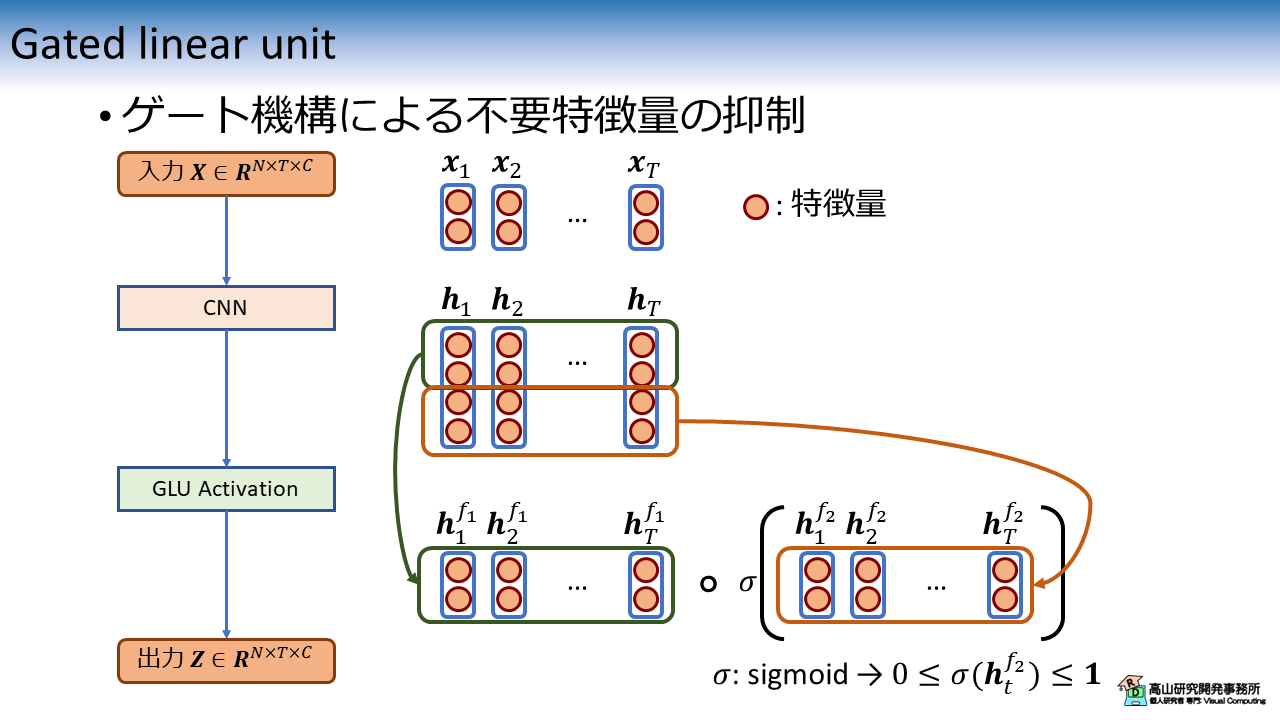
基本的に,GLU は CNN や Linear 層などの特徴次元が変わる層の後ろに配置します.
図3 の例では,CNN を用いて入力 \(\boldsymbol{X} \in R^{N \times T \times C}\) を \(\boldsymbol{H} \in R^{N \times T \times 2C}\) に変換しています.
\(\boldsymbol{H}\) では特徴次元数が \(2C\) に増えている点に注意してください.
GLU では入力の特徴次元を半分に分け,下記のような処理を行います.
\(\boldsymbol{H^{f_1}}, \boldsymbol{H^{f_2}}\) は特徴次元に沿って半分に分割された特徴量です.
\(\sigma(\cdot)\) は Sigmoid 関数を示し,\(\circ\) は要素毎の掛け算を示します.
\(\sigma(\boldsymbol{H^{f_2}})\) の各要素は \([0, 1]\) の値となるため,不要な特徴量には低い重みが与えられ出力が抑制されます.
文献[Gulati'20] にそこまで明示的に書いてあるわけではないですが,DSCNN と GLU の組み合わせで特徴抽出の軽量化と効率化を同時に達成するような設計になっているようです.
よくできていますね (^^).
- [Ma'18]: N. Ma, et al., "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design," Proc. of the ECCV, available here, 2018.
- [Dauphin'17]: Y. N. Dauphin,17, et al., "Language modeling with gated convolutional networks," Proc. of the ICML, available here, 2017.
- [Gulati'20]: A. Gulati, et al., "Conformer: Convolution-augmented Transformer for Speech Recognition," Proc. of the Interspeech, available here, 2020.
2. 追加実験
2.1 実験内容
第1.2 項で見てきたように Conformer の Convolution module はシンプルでよく考えられた設計だと思うのですが,いくつか気になる点があります.
- ブロック末尾の PCNN は必要なのか
- DSCNN は PCNN \(\rightarrow\) DCNN の順で処理を適用しているが,DCNN \(\rightarrow\) PCNN では駄目なのか
- DSCNN の代わりに CNN を用いたら性能は上がるのか
まず1番目の点についてですが,ブロック末尾の PCNN については文献[Gulati'20] でほぼ言及が有りません.
図2に注記したように,正規化層の連続を防ぐ意図で入れていると予想していますが,どの程度の効果があるのかは示されていません.
次に2番目の点については,Conformer で用いている DSCNN [Chollet'17] は PCNN \(\rightarrow\) DCNN の順で適用されています.
文献[Chollet'17] ではオリジナルの DSCNN として文献[Sifre'14] を参照していますが,こちらでは DCNN \(\rightarrow\) PCNN の順で処理が適用されています.
これらの順番の差は処理に影響するのかが気になりました.
最後に3番目の点については,Conformer は音声認識の分野で提案しているためか軽量な CNN を用いることが前提になっているようです.
そのため,同じ方向性の手法 [Wu'19] との比較はしてますが,標準 CNN との比較はしていないようです.
実験記事 で使用していた手話データは,音声認識のデータに比べて系列長は短いです.
そのため,標準 CNN の利用が許容される場合はどの程度の性能になるのかが気になりました.
以上の点を検証するため,図4に示す代替構成で実験を行いました.
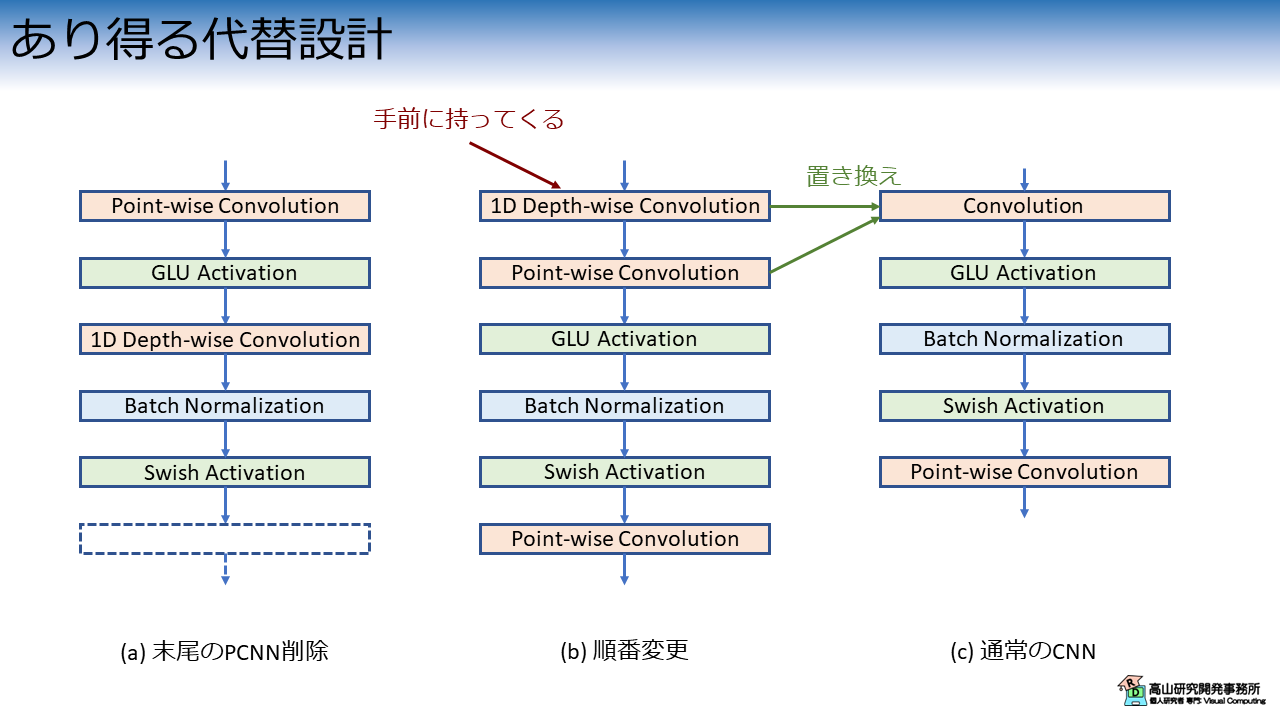
各構成と上で述べた疑問点の対応関係は下記のとおりです.
- 図4(a) - 疑問点1: 末尾の PCNN を削除した構成
- 図4(b) - 疑問点2: DCNN を PCNN の前に配置
- 図4(c) - 疑問点3: DSCNN を CNN に交換
各構成の認識性能は次項で確認していきます.
- [Sifre'14]: L. Sifre, "Rigid-Motion Scattering For Image Classification," Ph.D. Thesis of Ecole Polytechnique, CMAP, Chapter 6, available here, 2014
- [Wu'19]: F. Wu., et al., "Pay Less Attention with Lightweight and Dynamic Convolutions," Proc. of the ICLR, available here, 2019.
2.2 実験結果
図5は,Convolution module の構成毎のValidation Lossと認識率の推移を示しています.
今回の実験は実験記事と同じ設定 (第3.2項をご参照ください) で行っています.
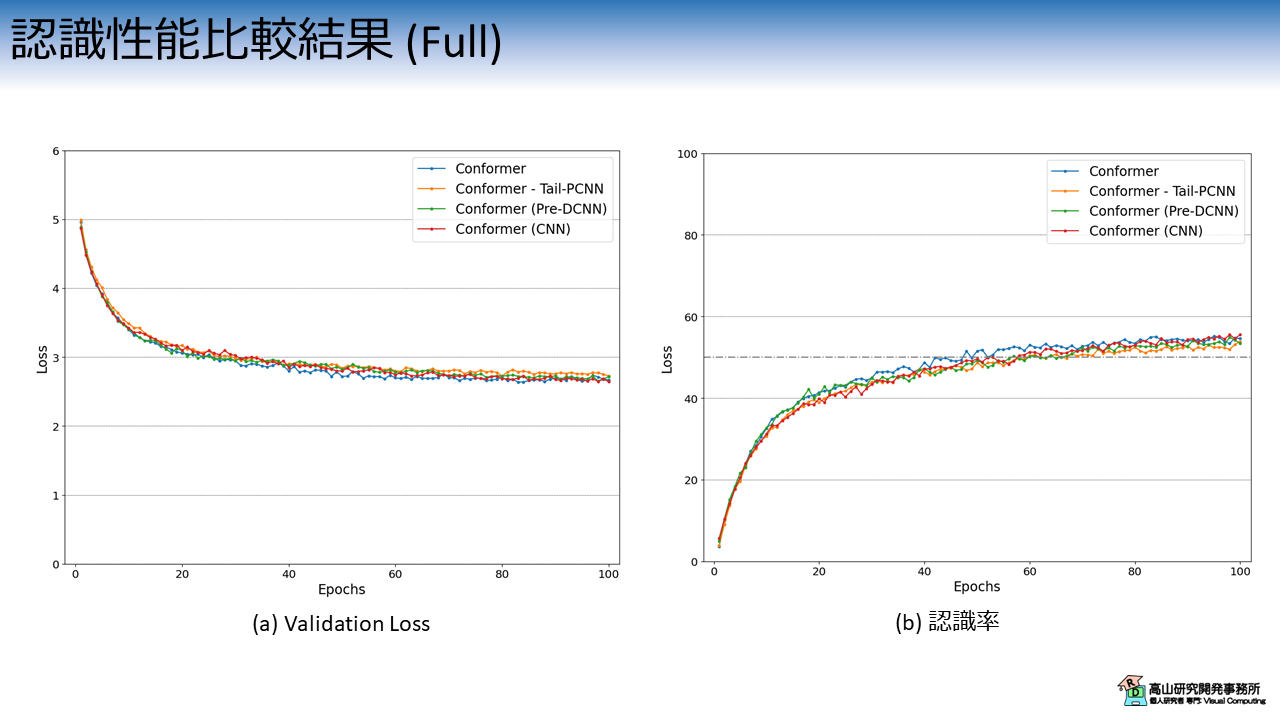
各線の色と実験条件の関係は次のとおりです.
- 青線 (Conformer): Conformer (K=3)と同条件
- 橙線 (Conformer - Tail-PCNN): 末尾の PCNN を削除 (図4(a)の構成)
- 緑線 (Conformer (Pre-DCNN)): DCNN を PCNN の前に配置 (図4(b)の構成)
- 赤線 (Conformer (CNN)): DSCNN を CNN に交換 (図4(c)の構成)
なお,時空間方向のカーネルサイズは全て\(5\) としています.
今回の実験では,途中の推移は多少の差があるものの,最終的には同程度の性能に収まっており差が確認できませんでした.
DSCNN は CNN の軽量化板という立ち位置ですので,CNN と同程度の性能が出ているのは良い結果と言えます.
一方,DSCNN の構成を変更しても明確な差は確認できませんでした.
なお,今回の実験は実装を修正して再実験をしています.
前回の実験時は,下記のような結果が得られていました.
【以前の説明】
まず青線と緑線の比較から,末尾の PCNN を削除した構成では認識性能が悪くなっていました.
正規化層が連続するのはよろしくないと思いますので,末尾の PCNN にはやはり一定の効果があるようです.
次に青線と赤線の比較から,DSCNN の処理順を変更した場合では認識性能が悪くなっていました.
DCNN を適用すると近隣フレームへ特徴量が伝搬することになります.
PCNN と GLU で特徴量の性能を上げてから DCNN で伝搬した方が良い結果になるということかもしれません.
最後に青線と赤線を比較すると,最初は DSCNN を用いた構成の性能が上回っておりエポック100 程度で CNN を用いた構成の性能が追いつくという結果になりました.
DSCNN は CNN の軽量化板という立ち位置ですので最終的に CNN の性能が上回るのは予想どおりです.
同程度の性能が維持できている点を考えると,やはり Conformer の Convolution module はよくできた構成だなと感じます.
上記のように説明していたのですが,今回は同様の結果が再現できなかったことを踏まえると,DSCNN の細かな構成は性能に影響しないか,あったとしても少ないということが言えそうです.
今回は Conformer の Convolution module について補足説明をしましたが,如何でしたでしょうか?
色々と実験をしてみて性能が上がらなかったのは残念でしたが,改めて Conformer はよくできているなと思いました.
今回の記事を書くにあたって久しぶりに CNN や畳み込みについて確認し直しました.
普段から当たり前のように使っていて身につけた気になっていましたが,細かな点は理解が曖昧だなと感じています.
いずれきちんと整理して記事にしたいと思います.
今回紹介した話が,これから手話認識や深層学習を勉強してみようとお考えの方に何か参考になれば幸いです.