
目次
こんにちは.高山です.
これまで様々な手話認識に関する記事を書いてきました.
今まで書いた記事は全て孤立手話単語認識の話題で,こちらはある程度充実してきましたので,そろそろ他の種類のタスクや技術も紹介したいと思っています.
そこで今回は,Kaggle の Google American Sign Language Fingerspelling Recognition (以下,GAFS) で用いられたデータセットについてお話したいと思います.
記事の後半では,孤立手話単語認識の時と同様に,GAFSデータセットを実験用にHDF5形式にまとめる方法を説明します.
今回解説するスクリプトはGitHub上に公開しています.
Colab上で使用しているデータセットは,説明用に大部分の追跡点を削除したデータセットです.
ご自分の環境で試す場合は,オリジナルのデータセットをローカル環境で (Google Driveに入り切らないため) 使用するようにしてください.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/17: タグを更新しました
- 2024/09/08: HDF5ファイルをチャネルファースト形式で保存するように処理を修正しました.
1. GAFSコンペティションについて
Kaggleの参加記事でも紹介させていただきましたが,GAFSコンペティションでは,アメリカ手話 (American Sign Language: ASL) の中で使われる指文字を題材として,連続指文字認識の性能を競い合います.
このコンペティションでは認識モデルの学習・検証用として,下記のようなデータセットが配布されます.
- ASL指文字数: 59文字 (アルファベット,数字,記号,スペース)
- ASL話者数: 94名 (学習データセットに含まれる人数です.追加データ分,主催者側テスト分は含んでいません)
- 入力データ: MediaPipe (version 0.9.0.1) による追跡点系列
- 出力形式: 指文字で表現されている文字列を出力します.
文字列の内容は,特定のフレーズ,住所,電話番号,およびURLなどです. - 総データ数: 67208個 (学習データセットに含まれる数です.追加データ分,主催者側テスト分は含んでいません)
- ライセンスおよび注意事項: CC-BY 4.0.ただし,個人識別に用いることはできません.
- ライセンサ: Google (データ提供には Deaf Professional Arts Network, the Georgia Institute of Technology, および National Technical Institute for the Deaf が関わっています)
コンペティションは既に終了していますが,データセットの入手および,テストデータを用いたモデル評価は今でも行なえます.
ただし,モデルはTensorflow Liteの形式で提出する必要があります.
また,モデルは規定以上のレイテンシでデータを処理できないといけません.
詳細については,公式サイトをご参照ください.
2. データセットについて
2.1 入手方法
図1に示すように,今回紹介するデータセットは Kaggle 内のコンペティションページからダウンロードできます.
全体をダウンロードすると,158GB 程度のサイズ (^^;) になりますので注意してください.
また,ダウンロードには Kaggle のアカウントが必要です.
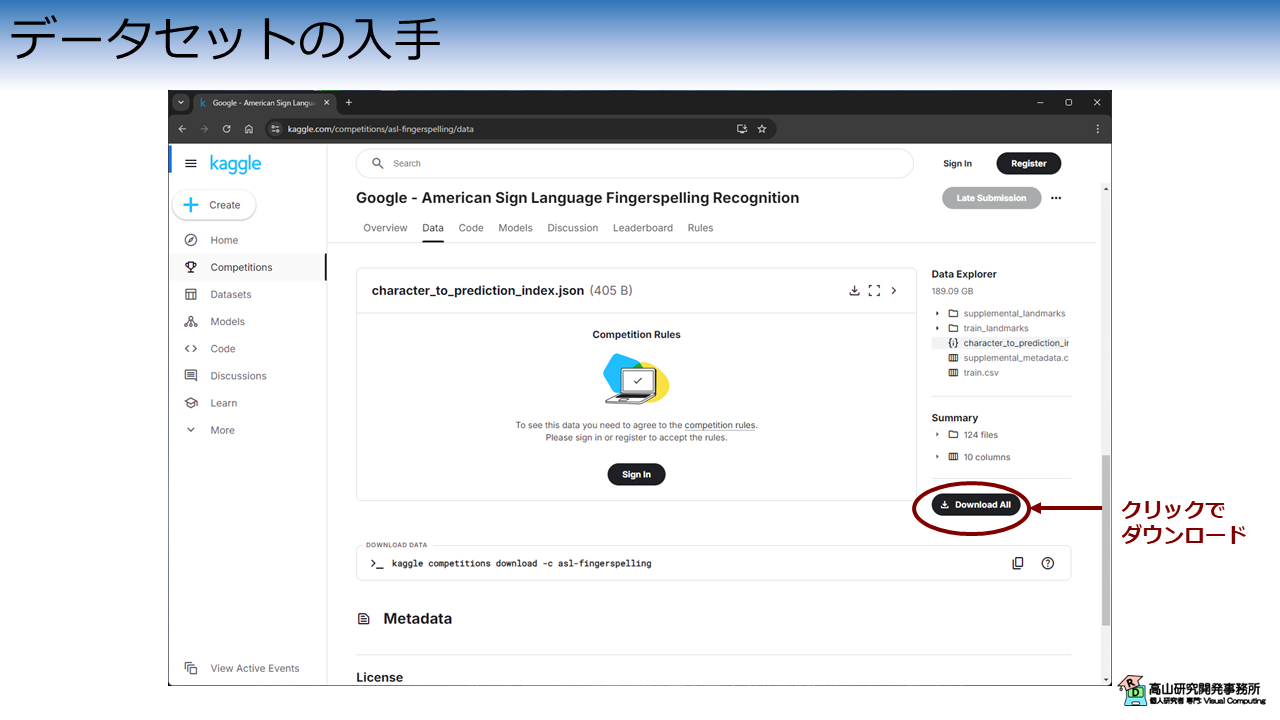
全体のダウンロードが完了すると,asl-fingerspelling.zip という ZIPファイルが取得できます.
2.2 データの内容
ZIPファイルを解凍すると,下記のようなファイルが展開されます.
$ unzip asl-fingerspelling.zip -d asl-fingerspelling
$ ls asl-fingerspelling
character_to_prediction_index.json supplemental_metadata.csv train_landmarks
supplemental_landmarks train.csv
辞書ファイル
character_to_prediction_index.json は辞書ファイルで,次のように指文字名と数値の関係が定義されています.
$ cat character_to_prediction_index.json
{
" ":0,
"!":1,
"#":2,
"$":3,
...
"~":58
}
表示内容から分かるように,59種類の指文字が 0 始まりの番号で定義されています.
最初の文字はスペース (半角の空白) です (プログラムで表示する際などは注意してください).
認識モデルは追跡点を入力した際に,辞書ファイルで定義した数値を出力するように実装する必要があります.
例えば,入力が abc という文字列を表している場合,認識モデルは 32, 33, 34 という数値列を返すように作らなければなりません.
サンプル情報
train.csv は各サンプルの情報を表形式でまとめたデータで,下記のような内容になっています.
path file_id sequence_id participant_id phrase
0 train_landmarks/5414471.parquet 5414471 1816796431 217 3 creekhouse
1 train_landmarks/5414471.parquet 5414471 1816825349 107 scales/kuhaylah
2 train_landmarks/5414471.parquet 5414471 1816909464 1 1383 william lanier
3 train_landmarks/5414471.parquet 5414471 1816967051 63 988 franklin lane
4 train_landmarks/5414471.parquet 5414471 1817123330 89 6920 northeast 661st road
... ... ... ... ... ...
67203 train_landmarks/2118949241.parquet 2118949241 388192924 88 431-366-2913
67204 train_landmarks/2118949241.parquet 2118949241 388225542 154 994-392-3850
67205 train_landmarks/2118949241.parquet 2118949241 388232076 95 https://www.tianjiagenomes.com
67206 train_landmarks/2118949241.parquet 2118949241 388235284 36 90 kerwood circle
67207 train_landmarks/2118949241.parquet 2118949241 388332538 176 802 co 66b
各カラムの内容は次のとおりです.
path: 骨格追跡点データへのパスfile_id: ファイル番号sequence_id: データ番号participant_id: 指文字話者IDphrase: 何の文字列を表出しているか
追跡点データ
train_landmarks は追跡点データが格納されているディレクトリです.
ls train_landmarks
1019715464.parquet
...
654436541.parquet
各ファイルは Apatche Parquet 形式で格納されており,Python の場合は Pandas を用いてロードすることが可能です.
格納されているデータ例を下記に示します.
import pandas as pd
df = pd.read_parquet("train_landmarks/450474571.parquet")
print(df)
frame x_face_0 x_face_1 ... z_right_hand_19 z_right_hand_20
sequence_id
2138557488 0 0.663001 0.644330 ... -0.117422 -0.111925
2138557488 1 0.667972 0.643810 ... -0.114211 -0.101464
2138557488 2 0.671009 0.642717 ... NaN NaN
2138557488 3 0.668623 0.641970 ... NaN NaN
2138557488 4 0.669397 0.647073 ... NaN NaN
... ... ... ... ... ... ...
2147465106 231 0.652571 0.639059 ... -0.119032 -0.097088
2147465106 232 0.659162 0.641239 ... -0.023387 -0.012794
2147465106 233 0.663675 0.649184 ... -0.070979 -0.060423
2147465106 234 0.662469 0.648533 ... -0.096455 -0.080358
2147465106 235 0.660208 0.641396 ... -0.133947 -0.112528
上に示すように,データは表形式で格納されており内容は次のとおりです.
index (sequence_id): データ番号.上の例で示されるとおり,1個のファイルに複数のデータがまとめられています.frame: 追跡点系列のフレーム番号.評価で用いられるコードを見る限りでは,このカラムの情報は使われていないようです.[x/y/z]_[type]_[landmark_index]: 追跡点の座標値.顔の x座標,左手の x座標,身体の x座標,右手の x座標,顔の y座標,...,右手の z座標の順で並んでいます.
孤立手話単語のデータセット (第2.2項-追跡点データをご参照ください) からフォーマットが変更されています.
統一したフォーマットに変換する方法は第4節で紹介します.
可視化例
図2に,データセットに含まれる指文字フレーズ の可視化例を示します.
図2(a)は,ロードした追跡点の可視化例です.
"536 verlin avenue" というフレーズを表出しています (最後にフレーズとは関係ない動作が含まれています).
見やすくするために一部の追跡点だけ描画しています.
また,本データセットには元動画が含まれていないので,参考までに高山の指文字動画を図2(b)に示します.
(見様見真似で行っているだけですので,注意してください.avenue の v が u になってしまっていますね...)
追加データ
supplemental_metadata.csv と supplemental_landmarks には利用可能な追加データが含まれています.
これらはフォーマットは同じですが,データ構成 (フレーズの内容など) に偏りがあります.
3. 統計情報
本節では,データセット全体の統計情報を解析したいと思います.
3.1 欠損データ
図2(a)から分かるように,追跡点データには追跡に失敗したフレームや部位 (以降,欠損データ) が含まれています.
ここでは,欠損データが含まれるサンプルと,どの部位の欠損データが多いかを解析してみます.
図3はデータセット内に欠損データが含まれるサンプルがどれだけあるかを示しています.
縦軸は全サンプルに対する欠損が含まれるサンプルの割合を示し,横軸は欠損が含まれる部位を示します.
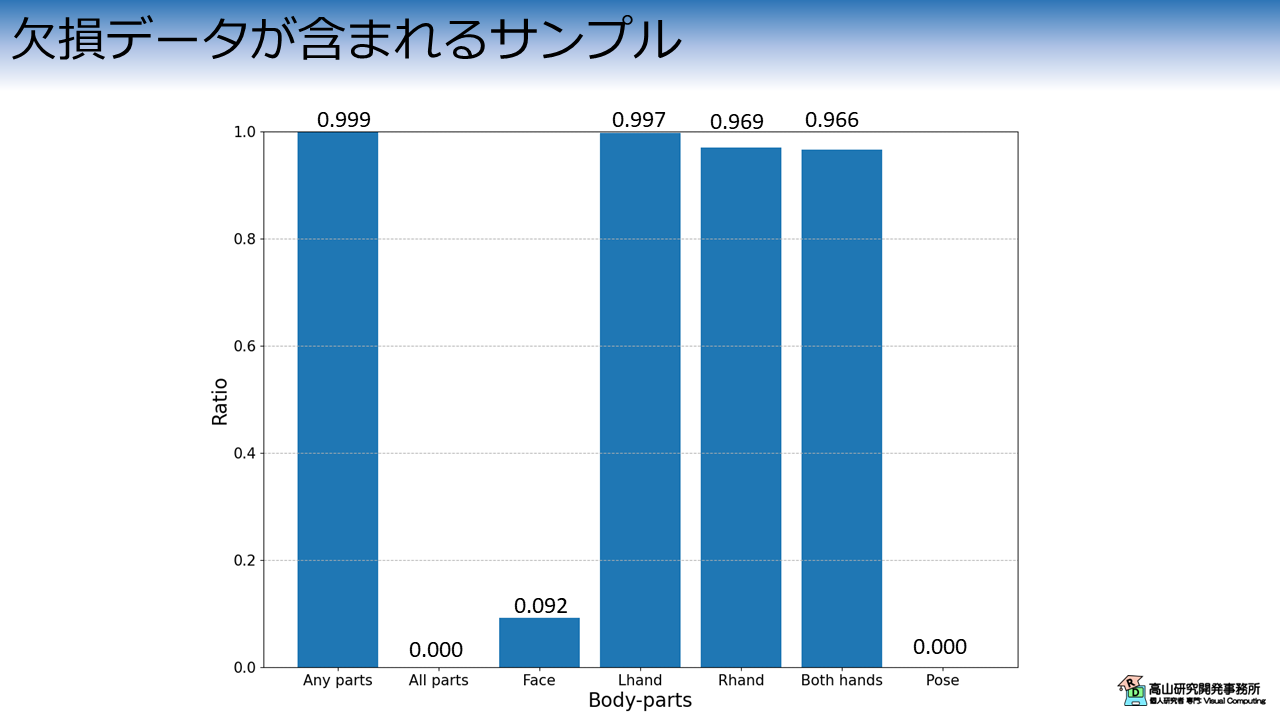
Any parts に示されるように,ほとんどのサンプルで何かしらの欠損データが含まれていることが分かります.
All parts はフレーム全体が欠損していることを示しています.
今回のデータセットでは欠損フレームは見つかりませんでした.
他の縦棒は各部位の欠損を示しており,特に手の追跡が失敗するケースが多いことが分かります.
また,手が顔に重なるケースなどで,顔の追跡に失敗するケースもあるようです.
上記から分かるとおり,本データセットには欠損データが多数含まれているため,認識モデルには欠損データに対する各種の対処法を実装する必要があります.
3.2 入力系列長
次に,サンプルの入力系列長を解析してみます.
図4はデータセットの系列長分布を示しています.
縦軸は頻度を示しており,横軸は系列長のデータ区間 (ビンと言います) を示しています.
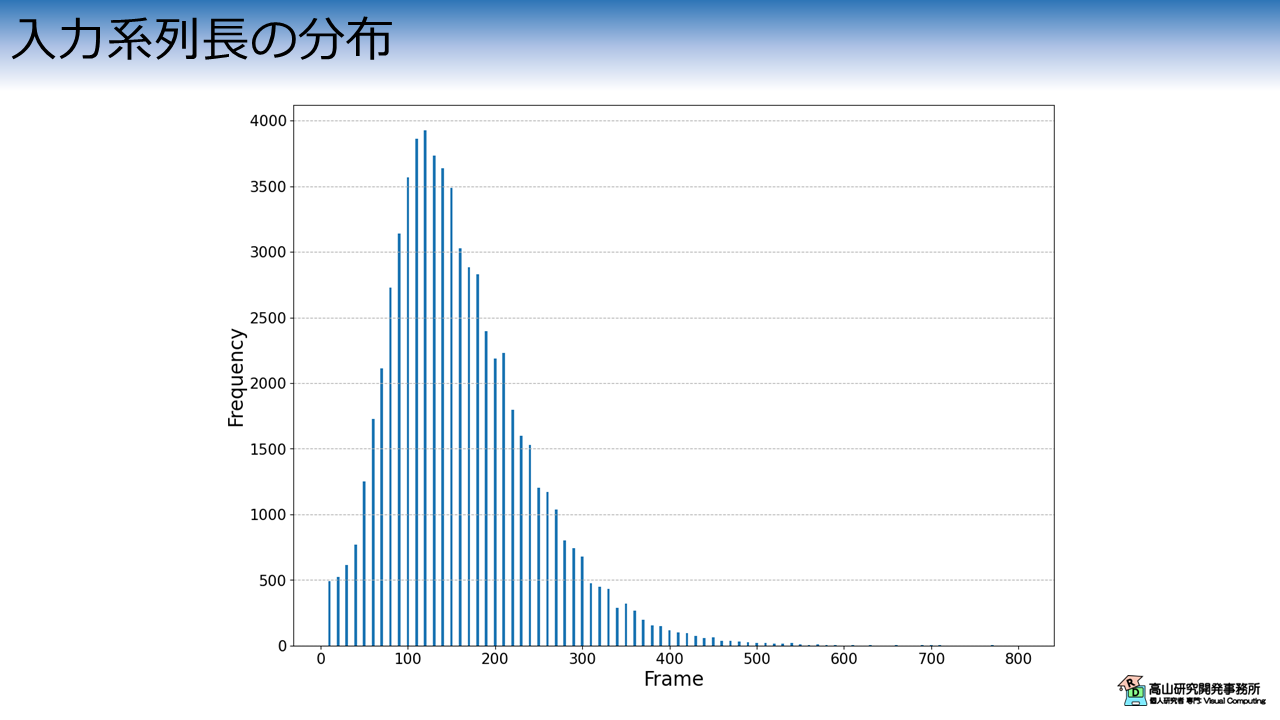
100から200フレーム程度 (3-7 秒程度) で動作が完了するサンプルが最も多くなっています.
一方,10 フレーム以下のサンプルや,800 フレーム (27秒程度) かかっているサンプルも含まれています (見えづらいですが,数サンプル程度あります).
このような極端な長さのサンプルは,撮影に失敗しているデータである可能性が高いです.
また,長いサンプルに合わせて学習を行うと,メモリを多く消費したり学習時間が長くなってしまったりします.
メモリ容量や処理速度が問題になる場合は,前処理でデータをカットしたり,系列長を変えたりなどの工夫をする必要が出てきます.
3.3 出力フレーズ長の分布
次に,サンプルの出力フレーズ長を解析してみます.
図5はデータセットのフレーズ長分布を示しています.
縦軸は頻度を示しており,横軸はフレーズに含まれる文字数を示しています.
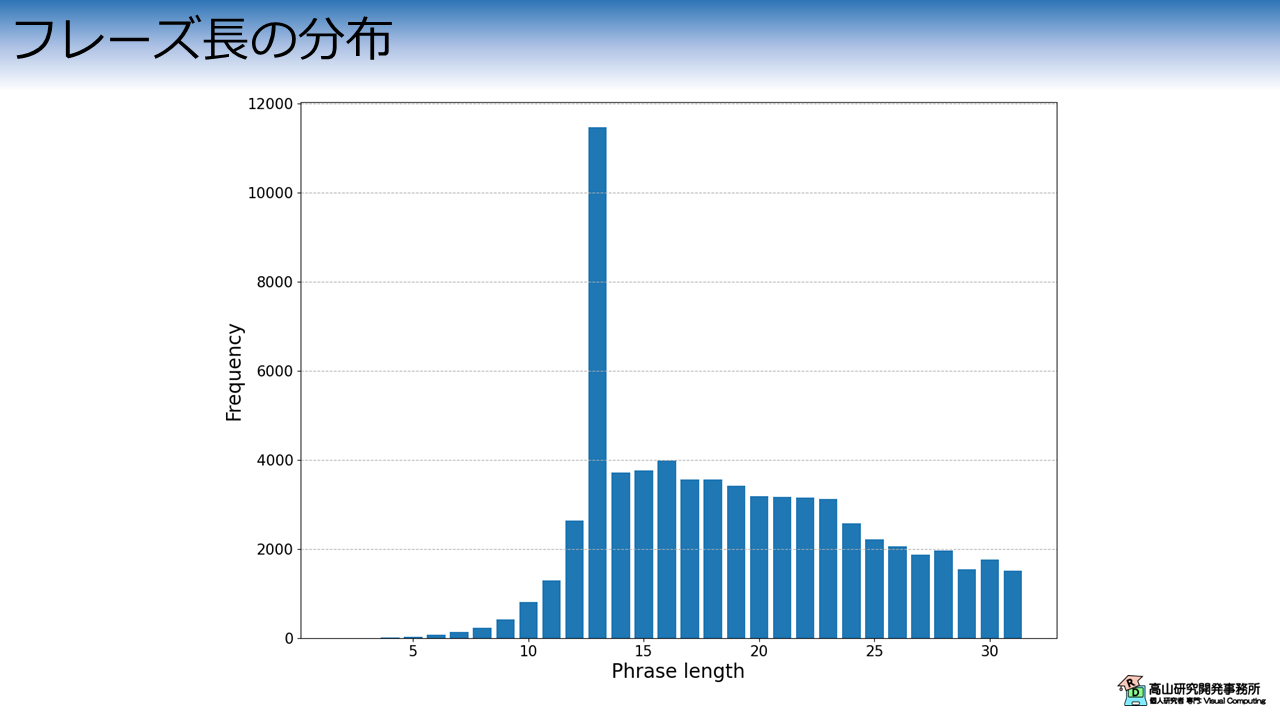
13文字のフレーズが最も多く,最長は31文字のフレーズです.
10文字以下のフレーズも小数ながら含まれています.
3.4 文字の出現頻度
最後に,各指文字の出現頻度を解析します.
図6は指文字の出現頻度分布を示しています.
縦軸は頻度を示しており,横軸は指文字を示しています.
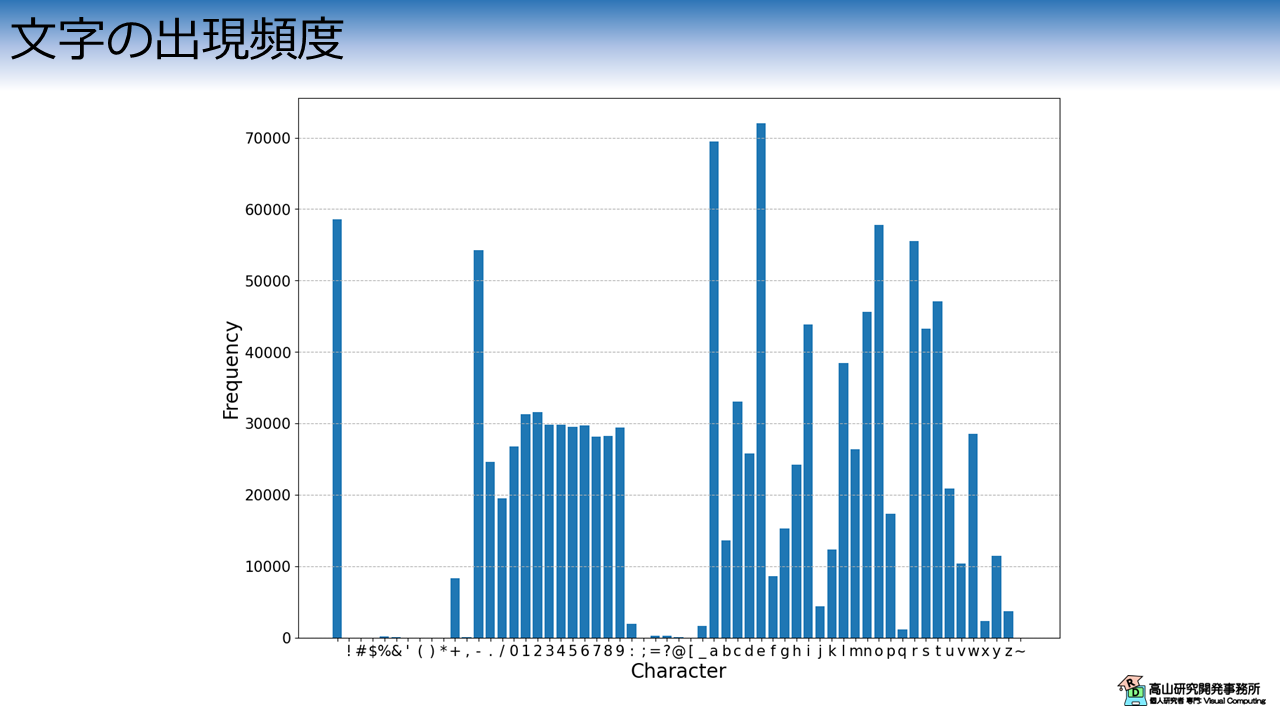
数値,アルファベット,および特定の記号の出現頻度が多く,かなりバラツキがあることが分かります.
孤立手話単語の場合と異なり,連続指文字認識や連続手話単語認識,および手話翻訳では出力クラスの頻度を均一にすることは難しいです.
コンペティションでは,高頻度のクラスに注力することで好成績を狙うことも戦略上有りえますが,実製品の開発では対処法を検討する必要があります.
4. 実験用データセットの作成方法
ここから先は,実験用データセットの作成方法を説明します.
本記事で説明した各種の統計量の算出コードも記載しています.
4.1 データセットのダウンロード
まずは,前準備として Google Colab にテスト用のデータセットをアップロードします.
まず最初に,データセットの格納先からデータをダウンロードし,ご自分の Google drive へアップロードしてください.
次のコードで Google drive を Colab へマウントします.
Google Drive のマウント方法については,補足記事にも記載してあります.
1 2 3 | |
ドライブ内のファイルを Colab へコピーします.
パスはアップロード先を設定する必要があります.
# Copy to local.
!cp drive/MyDrive/Datasets/gafs_dataset_orig.zip gafs_orig.zip
データセットは ZIP形式になっているので unzip コマンドで解凍します.
!unzip -o gafs_orig.zip
Archive: gafs_orig.zip
creating: inputs/
creating: inputs/google_fs/
...
inflating: inputs/google_fs/train_landmarks/450474571.parquet
成功すると inputs/google_fs 以下にデータが解凍されます.
!ls inputs/google_fs
character_to_prediction_index.json supplemental_metadata.csv train_landmarks
supplemental_landmarks train.csv
データの内容については,第2.2項で説明したとおりです.
!cat inputs/google_fs/character_to_prediction_index.json
{
" ":0,
"!":1,
...
"~":58
}
!cat inputs/google_fs/train.csv | head
path,file_id,sequence_id,participant_id,phrase
train_landmarks/5414471.parquet,5414471,1816796431,217,3 creekhouse
...
冒頭で説明したとおり,説明用のデータですので大部分の追跡点は含まれていません.
!ls inputs/google_fs/train_landmarks
450474571.parquet
4.2 データのロードとフォーマットチェック
まずはデータをロードして,フォーマットをチェックしていきます.
基本的には第3節で説明した内容の実行コードになります.
モジュールのインポート
下記のコードでモジュールをインポートします.
1 2 3 4 5 6 7 8 9 10 11 | |
【コード解説】
- 標準モジュール
- os: OS依存の機能を操作するライブラリ.ファイルの読み書きをするために使用します.
- json: JSONファイル制御ライブラリ.辞書ファイルのロードに使用します.
- shutil: 高水準のファイル操作ライブラリ.
- time: 時刻データの操作ライブラリ.処理時間を計測するために使用します.
- 3rdパーティモジュール
- numpy: 行列演算ライブラリ.
- h5py: HDF5ファイル操作ライブラリ.データベースの読み書きに使用します.
- pandas: 表形式データ操作ライブラリ.
- matplotlib: グラフ描画ライブラリ.
データセットのロードと基本情報の確認
下記のコードでデータセットをロードします.
データは pandas.DataFrame 型になっており,print() で表示すると第2.2項で説明した内容 (サンプル情報の段落をご参照ください) が表示されます.
1 2 3 4 | |
path file_id sequence_id participant_id phrase
0 train_landmarks/5414471.parquet 5414471 1816796431 217 3 creekhouse
1 train_landmarks/5414471.parquet 5414471 1816825349 107 scales/kuhaylah
2 train_landmarks/5414471.parquet 5414471 1816909464 1 1383 william lanier
3 train_landmarks/5414471.parquet 5414471 1816967051 63 988 franklin lane
4 train_landmarks/5414471.parquet 5414471 1817123330 89 6920 northeast 661st road
... ... ... ... ... ...
67203 train_landmarks/2118949241.parquet 2118949241 388192924 88 431-366-2913
67204 train_landmarks/2118949241.parquet 2118949241 388225542 154 994-392-3850
67205 train_landmarks/2118949241.parquet 2118949241 388232076 95 https://www.tianjiagenomes.com
67206 train_landmarks/2118949241.parquet 2118949241 388235284 36 90 kerwood circle
67207 train_landmarks/2118949241.parquet 2118949241 388332538 176 802 co 66b
下記に示すとおり,94 人分のデータが含まれています.
1 2 3 4 | |
[ 0 1 2 4 6 9 10 13 15 18 20 21 24 25 27 33 36 38
40 43 53 56 59 63 68 70 71 72 73 74 76 80 81 88 89 92
93 95 102 105 107 109 112 113 115 117 121 122 125 128 135 136 138 141
143 145 147 151 153 154 157 158 159 160 161 168 169 171 176 178 181 186
187 188 192 196 202 203 216 217 219 223 225 227 230 231 233 236 239 241
242 246 251 254]
94
下記に示すとおり,データ数は \(67208\) 個で 約\(70\%\) のデータは固有の指文字フレーズになっています.
1 2 3 4 5 6 7 8 | |
The number of total phrases:67208
Ther number of unique phrases:46478
Ratio of unique phrases:0.6915545768360909
Ratio of duplicate phrases:0.30844542316390905
出力フレーズ長分布の描画
第3.3項で説明した,出力フレーズ長の分布は下記の処理で描画しています.
まず,次のコードでフレーズ長を収集します.
1 2 3 | |
31
次のコードで,フレーズ長のヒストグラムを描画します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
25 26 27 28 29 30 31]
[ 1 0 5 27 66 136 225 421 815 1295 2634 11460
3716 3760 3977 3563 3558 3423 3184 3171 3149 3115 2579 2212
2061 1878 1966 1540 1767 1504]
ヒストグラムの棒を,区間の左側境界,右側境界のどちらに合わせて描画するかは毎回悩みます.
今回は区間が 1 刻みなので右側境界に合わせて描画しています.
(plt.bar(borders[:-1]+1) として,30 <= x <= 31 が31 の箇所に表示されるように処理しています).
文字の出現頻度の描画
第3.4項で説明した,出力フレーズ長の分布は下記の処理で描画しています.
まず,次のコードで辞書を読み込み,各文字の出現頻度を数えています.
1 2 3 4 5 6 7 8 9 10 11 | |
[' ', '!', ... '~']
{' ': 58569, '!': 3, ... '~': 21}
次のコードで,文字出現頻度のヒストグラムを描画します.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
x軸の目盛りは,plt.xticks(x, label_x) で置き換えています.
追跡点データのロードと確認
第2.2項で説明した (追跡点データの段落をご参照ください),追跡点データのフォーマットは下記のコードで確認します.
処理の都合で,統計情報は実験用データセットを作成した後に確認します.
次のコードで追跡点データをロードします.
データは pandas.DataFrame 型になっていますので,print() でフォーマットを確認することができます.
1 2 3 | |
frame x_face_0 x_face_1 ... z_right_hand_19 z_right_hand_20
sequence_id
2138557488 0 0.663001 0.644330 ... -0.117422 -0.111925
2138557488 1 0.667972 0.643810 ... -0.114211 -0.101464
2138557488 2 0.671009 0.642717 ... NaN NaN
2138557488 3 0.668623 0.641970 ... NaN NaN
2138557488 4 0.669397 0.647073 ... NaN NaN
... ... ... ... ... ... ...
2147465106 231 0.652571 0.639059 ... -0.119032 -0.097088
2147465106 232 0.659162 0.641239 ... -0.023387 -0.012794
2147465106 233 0.663675 0.649184 ... -0.070979 -0.060423
2147465106 234 0.662469 0.648533 ... -0.096455 -0.080358
2147465106 235 0.660208 0.641396 ... -0.133947 -0.112528
下記に示すとおり,1 個 ファイルに複数のデータが含まれていることが分かります.
1 2 3 4 | |
Index(['frame', 'x_face_0', 'x_face_1', 'x_face_2', 'x_face_3', 'x_face_4',
'x_face_5', 'x_face_6', 'x_face_7', 'x_face_8',
...
'z_right_hand_11', 'z_right_hand_12', 'z_right_hand_13',
'z_right_hand_14', 'z_right_hand_15', 'z_right_hand_16',
'z_right_hand_17', 'z_right_hand_18', 'z_right_hand_19',
'z_right_hand_20'],
dtype='object', length=1630)
287
4.2 実験用データへの変換
本項では HDF5 形式の実験用データに変換する処理を説明します.
追跡点のロード処理
まず最初に,追跡点のロード処理を実装します.
Parquet 形式のデータは,カラム名を指定することで指定データだけを任意のカラム順で読み込むことができます.
ここでは孤立手話単語認識で用いたフォーマットと互換性を保ちたいので,下記のコードでカラム名を定義します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
['x_face_0', 'y_face_0', 'z_face_0', ... 'x_right_hand_20', 'y_right_hand_20', 'z_right_hand_20']]
追跡点ごとに \((x, y, z)\) 座標がまとまるように順番を入れ替えています.
また,frame カラムは使用しないので削除しています.
次のコードで追跡点のロード関数を実装します.
1 2 3 4 5 | |
pd.read_parquet() の columns 引数に先ほど定義したカラム名を渡している点に注意してください.
3-4行目の処理は sequence_id と追跡点データを紐づけています.
変換メイン処理
次のコードで変換のメイン処理を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
【コード解説】
- 1-3行目: 出力先ディレクトリ作成
- 5行目: 追跡点ファイル一覧を取得
- 6-32行目: 追跡点ファイル毎に変換処理
- 12行目: 追跡点データ読み込み
- 14-30行目: 追跡点データ毎に変換
- 15-20行目: 関連情報をロードしてフレーズを数値列に変換
- 21-23行目: 追跡点データを成形
- 24-26行目: 出力ファイルオープン.ファイルが存在する場合は追記モードで開きます.
- 28-30行目: データ書き込み
- 31-32行目: 処理時間出力
Processed train_landmarks/450474571.parquet in 4.616932380999998 seconds.
次のコードで辞書ファイルをコピーします.
# Copy dictionary.
shutil.copy(dict_file, os.path.join(outdir, "character_to_prediction_index.json"))
dataset_fs/character_to_prediction_index.json
次のコマンドで結果を確認します.
!ls -alhs dataset_fs
total 289M
4.0K drwxr-xr-x 2 root root 4.0K Sep 7 14:49 .
4.0K drwxr-xr-x 1 root root 4.0K Sep 7 14:49 ..
776K -rw-r--r-- 1 root root 775K Sep 7 14:49 0.hdf5
...
4.0K -rw-rw-rw- 1 root root 405 Sep 7 14:49 character_to_prediction_index.json
ここでは 1 ファイルだけなので容量は少ないですが,全データを処理すると66G バイト程度になります.
4.3 追跡点の統計情報の解析
順番が前後してしまいましたが,第3.1項と第3.2項で説明した,追跡点の統計情報解析処理を示します.
まず,次のコードで追跡点の欠落データの数え上げと,系列長の収集を行います.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | |
基本的には,地道にループを回して数えているだけです.
次のコードで部位ごとの欠損データの割合を描画しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
{'total': 287, 'any': 287, 'all': 0, 'face': 27, 'lhand': 286, 'pose': 0, 'rhand': 270, 'bhand': 269}
[1.0, 0.0, 0.09407665505226481, 0.9965156794425087, 0.9407665505226481, 0.9372822299651568, 0.0]
次のコードで入力系列長分布を描画します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
ここではヒストグラム区間の左側境界上に棒が立つように描画しています.
(plt.bar(borders[:-1]) として,0 <= x < 10 が 0 の箇所に表示されるように処理しています).
今回は Kaggle の指文字認識コンペティションで用いられた GAFS データセットについて紹介しましたが,如何でしたでしょうか?
これだけのサイズの連続指文字認識用データが商用可能ライセンスで出たのはインパクトがでかいですね.
ただ,指文字メインだと実用的なアプリケーションを企画する方が大変かもしれませんが...
また,このデータセットは指文字認識が対象ですが,考え方やフォーマットは連続手話単語認識や手話翻訳に応用可能です.
商用利用可能な連続手話単語認識や手話翻訳データセットは (高山の知る限り) 未だありませんが,研究開発の足がかりとしては十分利用できるのではないでしょうか.
今回紹介した話が,これから手話認識を勉強してみようとお考えの方に何か参考になれば幸いです.




