目次
こんにちは.高山です.
実践手話認識 - モデル開発編の第二回になります.
今回は Conformer [Gulati'20] を用いた孤立手話単語認識モデルを実装する方法を紹介します.
Conformer は,第一回で紹介した Macaron Net に Convolutional Neural Network (CNN) をベースとした処理ブロック (Convolution module) を追加したモデルです.
(実際は Positional encoding や活性化関数なども改良されています)
Transformer [Vaswani'17] の Multi-head self attention (MHSA) では,あるフレームの特徴抽出を行う際に全フレームの特徴を取り込みながら計算を行います.
一方 Conformer の Convolution module では,計算対象フレームと近接フレームの特徴を用いて特徴抽出を行います.
全体的な関係性と局所的な関係性 (文献[Gulati'20] では,それぞれ global context と local context と呼んでいます) のそれぞれに着目した特徴抽出を併用することで,相補的な効果を狙います.
Macaron Net [Lu'19] からスムーズに拡張できますので,今回はこちらの手法を実装して性能が向上するかどうか実験してみたいと思います.
今回解説するスクリプトはGitHub上に公開しています.
複数の実験を行っている都合で,CPUで動かした場合は結構時間がかるのでご注意ください.
- [Gulati'20]: A. Gulati, et al., "Conformer: Convolution-augmented Transformer for Speech Recognition," Proc. of the Interspeech, available here, 2020.
- [Vaswani'17]: A. Vaswani, et al., "Attention Is All You Need," Proc. of the NIPS, available here, 2017.
- [Lu'19]: Y. Lu, et al., "Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View," arXiv:1906.02762, available here, 2019.
更新履歴 (大きな変更のみ記載しています)
- 2024/10/04: Convolution ブロック先頭と Convolution module で同じ正規化層を用いる実装になっていたため,個別に設定できるように修正し,再度実験を行いました.
なお,性能は大きく変わらなかったため結論は変えていません. - 2024/09/17: タグを更新しました
1. 実験概要
図1に今回の実験内容を示します.
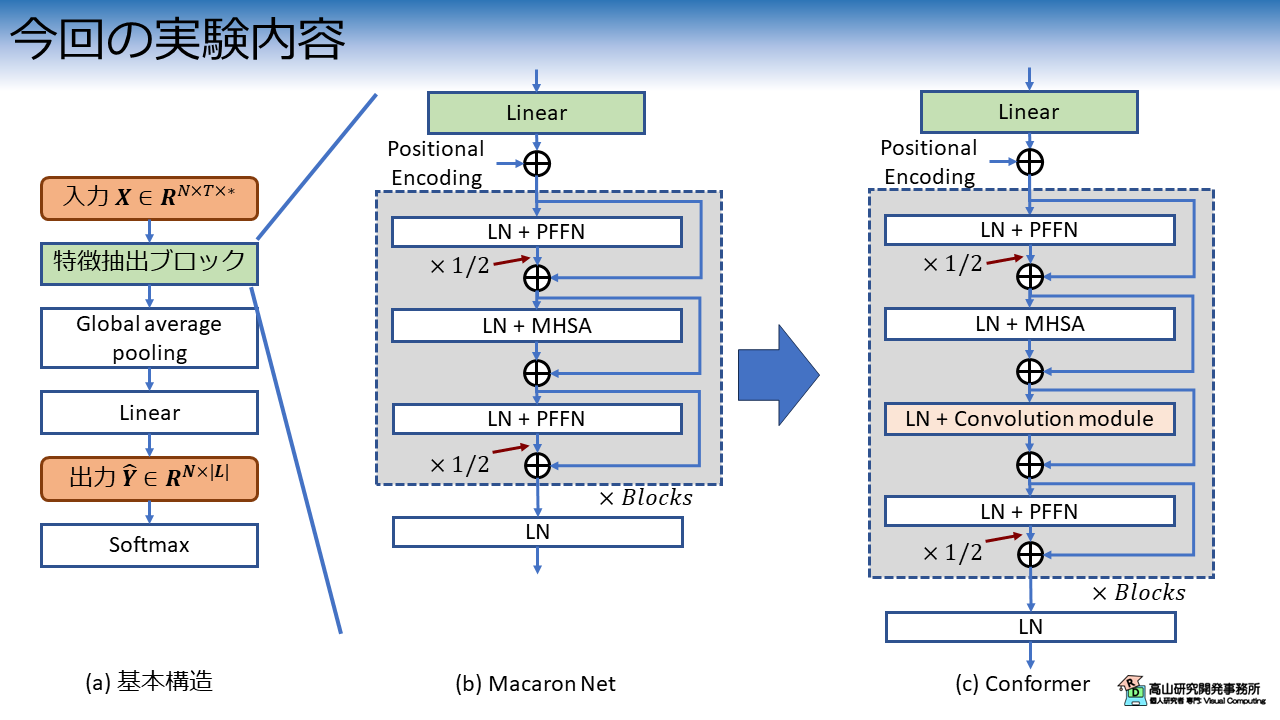
図1 の LN, PFFN, MHSA は,それぞれ Layer normalization [Ba'16] と Position-wise feed forward network, および Multi-head self attention を示します.
第一回で紹介した Macaron Net をベースとして,Convolution module を追加して認識性能を比較します.
その他の変更した点,変更しなかった点は下記のとおりです.
- 活性化関数: Conformer は ReLU [Fukushima'69] から Swish [Ramachandran'17] へ変更.
(ReLU ってネオコグニトロン (CNN の原型) で有名な福島先生が最初だったのですね.不勉強で知りませんでした...) - 位置エンコーディング: 文献[Gulati'20] では 相対位置エンコーディング[Dai'19] を用いているが,Transformer の手法のままにする.
位置エンコーディングを変更しなかった理由は,単に実装が大変そうだったからです(^^;).
同時に変更すると話が混み合うという理由もありますが...
- [Ba'16]: J. Ba, et al., "Layer Normalization," arXiV: 1607.06450, available here, 2016.
- [Fukushima'69]: K. Fukushima, "Visual Feature Extraction by a Multilayered Network of Analog Threshold Elements," IEEE. Trans. Syst. Man. Cybern., Vol.5, Issue 4, pp.322-333, 1969.
- [Ramachandran'17]: P. Ramachandran, et al., "Searching for Activation Functions," Proc of the ICLR Workshop, available here, 2018.
- [Dai'19]: Z. Dai, et al., "Transformer-XL: Attentive Language Models beyond a Fixed-Length Context," Proc of the ACL, available here, 2019.
2. Convolution module
Convolution module のブロック図を図2に示します.
なお,Dropout 層は省略しています.
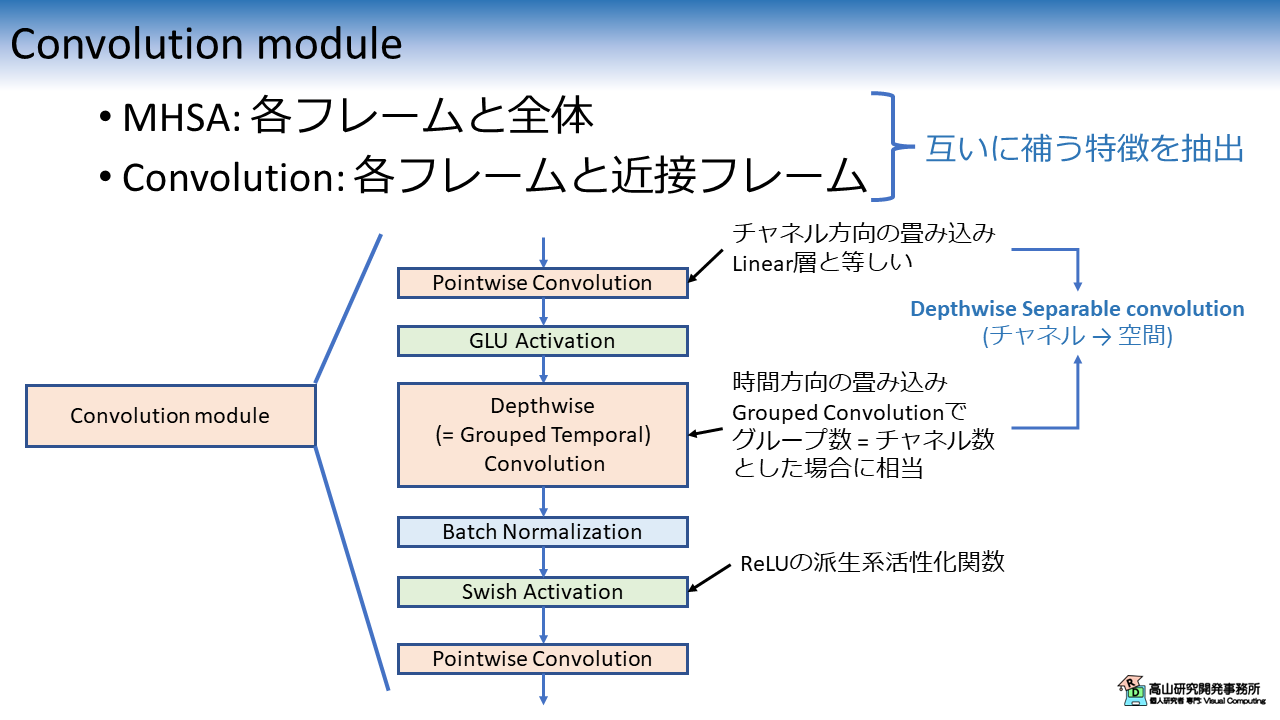
基本的には,CNN \(\rightarrow\) 正規化層 \(\rightarrow\) 活性化関数,という画像処理系モデルでよく見る構造ですが,いくつかの点で異なります.
Depthwise Separable convolution の採用
Convolution module では,標準 CNN の代わりに活性化関数付きの Depthwise Separable convolution (DSCNN) [Chollet'17] を用います.
標準の CNN では,特徴次元の変更と時空間のフィルタ処理を同時に行います.
一方 DSCNN では,特徴次元の変更と (チャネル毎の) 時空間フィルタ処理を,それぞれ Pointwise convolution (PCNN) と Depthwise convolution (DCNN) を用いて順番に行います.
この設計により CNN の処理ブロックに必要な学習パラメータ数を減らすことができます.
また,PCNN と DCNN の間に Gated linear unit (GLU) 活性化関数 [Dauphin'17] を挟むことで,認識に不要な特徴を抑制しながら特徴抽出を行っています.
余談ですが,PCNN と DCNN はそれぞれ下記の処理と等価な処理になります.
- PCNN: Linear 層
- DCNN: Grouped convolution において,\(\text{[Group数]} = \text{[チャネル数]}\) とした場合
個人的には分かりにくいと感じており,別名を付ける必要はなかったのでは (特にDCNN) ,と思っています.
ブロックの末尾で再度 Point-wise convolution を適用
ブロック末尾の PCNN については文献[Gulati'20] でほぼ言及がありません.
ただし,ブロック末尾の PCNN を削除すると Batch Normalization \(\rightarrow\) (次のブロックの) Layer Normalziation と正規化処理が連続してしまいます.
そのため正規化処理が連続するのを防ぐ目的で入れているのでは,と思っています.
- [Chollet'17]: F. Chollet'17, et al., "Xception: Deep Learning with Depthwise Separable Convolutions," Proc. of the CVPR, available here, 2017.
- [Dauphin'17]: Y. N. Dauphin,17, et al., "Language modeling with gated convolutional networks," Proc. of the ICML, available here, 2017.
3. 実験結果
次節以降では,実装の紹介をしていきます.
コード紹介記事の方針として記事単体で全処理が分かるように書いており,少し長いので結果を先にお見せしたいと思います.
なお,今回の実験から学習を安定させるために,ラベルスムージングと各種のデータ拡張処理を導入しています.
これらの処理については「手話認識入門」の記事で解説しているので,よろしければご一読ください.
3.1 頻度の多い10単語を学習させた結果
図3は,アーキテクチャ毎のValidation Lossと認識率の推移を示しています.
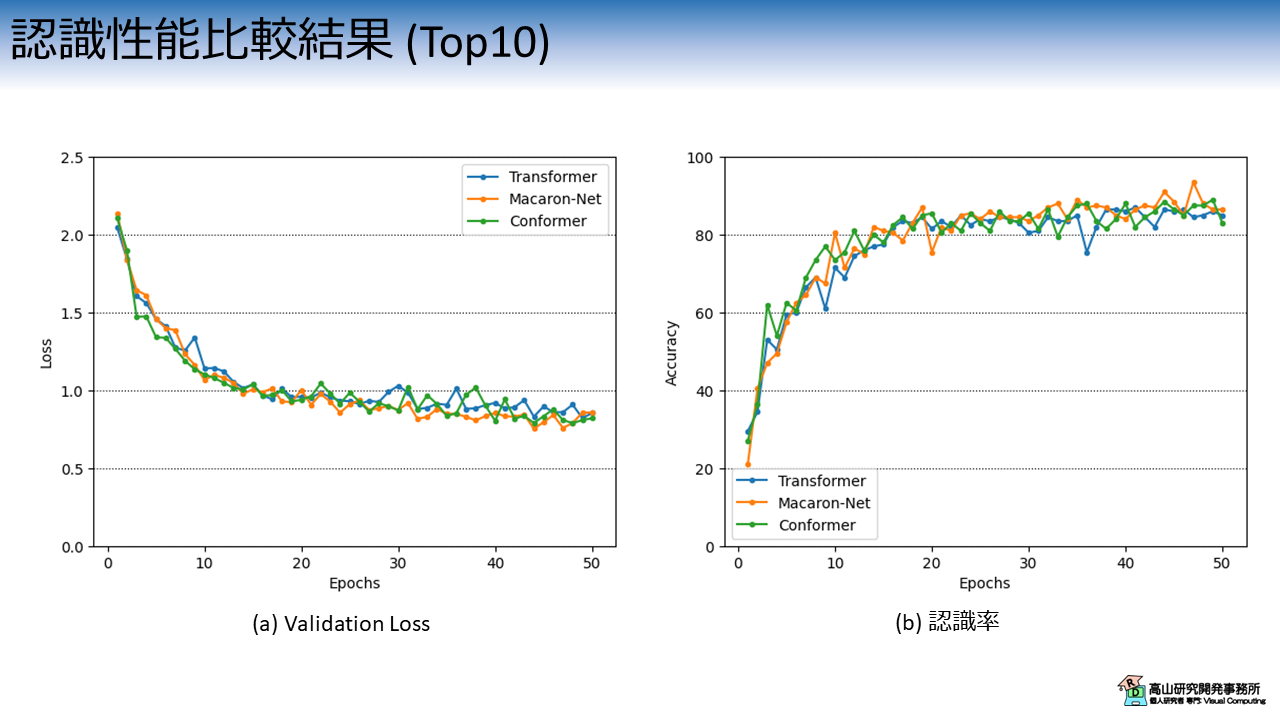
横軸は学習・評価ループの繰り返し数 (Epoch) を示します.
縦軸はそれぞれの評価指標を示します.
各線の色と実験条件の関係は次のとおりです.
- 青線 (Transformer): Pre-LN構成のTransformer
- 橙線 (Macaron-Net): Macaron Net-L
- 緑線 (Conformer): Conformer (カーネルサイズ 3)
前処理の追加によって全体的に性能が上がっているのは良いですが...,正直あまり性能差は感じられませんね...(^^;)
10単語を用いた実験は性能が飽和し始めているのかもしれません.
3.2 250単語を学習させた結果
全データ (250単語) を学習させた場合の挙動を図4に示します.
なお,こちらの実験はメモリや処理時間の都合でColab上では実行が難しいので,ローカル環境で行いました.
データの分割方法やパラメータは10単語のときと同じです.
ただし,学習エポック数は100,バッチ数は256に設定しています.
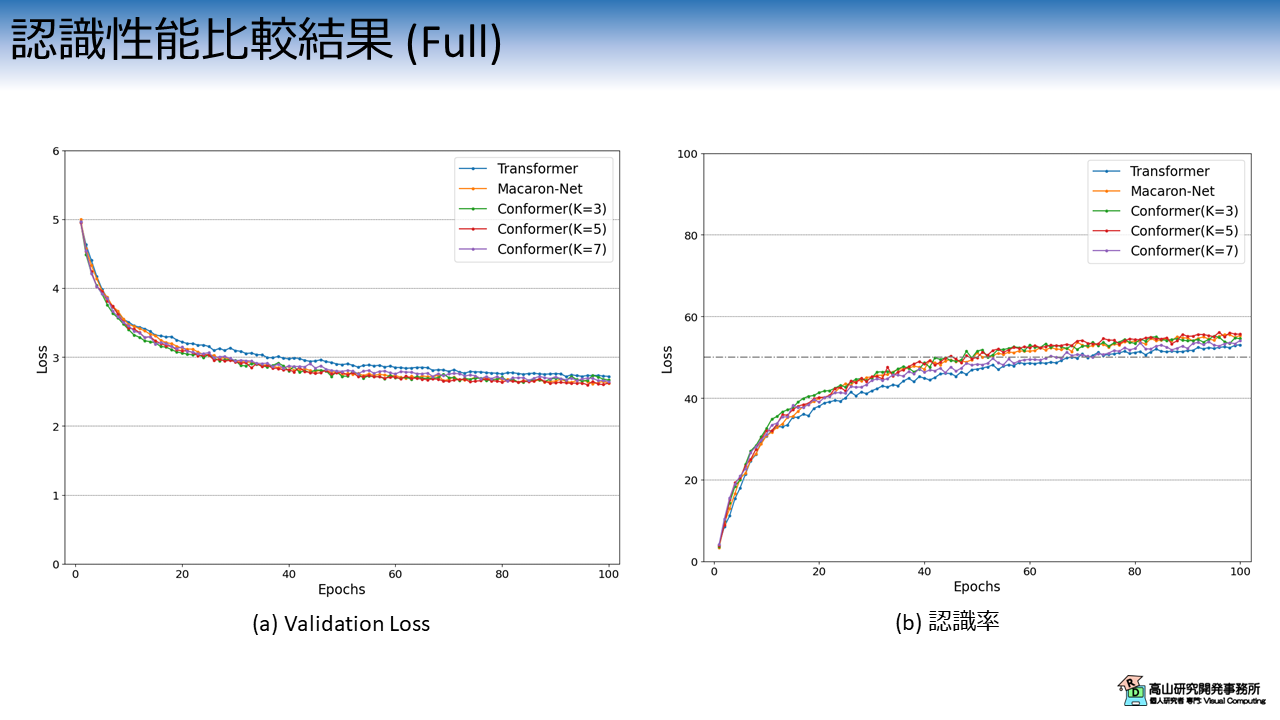
各線の色と実験条件の関係は次のとおりです.
- 青線 (Transformer): Pre-LN構成のTransformer
- 橙線 (Macaron-Net): Macaron Net-Lと同条件
- 緑線 (Conformer (K=3)): Conformer (カーネルサイズ 3)
- 赤線 (Conformer (K=5)): Conformer (カーネルサイズ 5)
- 紫線 (Conformer (K=7)): Conformer (カーネルサイズ 7)
Conformer に関してはカーネルサイズを変更した評価も行っています.
今回の実験では,カーネルサイズが 5 の Conformer が最も良い性能となりました.
ただし劇的に良くなるというわけではなく,設定次第では性能が悪くなる (例えば紫線) こともあるようです.
前処理を入れた効果だと思いますが,いずれのモデルも100 エポック時点で性能が収束していないようですね.
学習を続ければ認識率 60 % 弱くらいまでは性能を伸ばせるかもしれません.
なお,今回の実験では話を簡単にするために,実験条件以外のパラメータは固定にし,乱数の制御もしていません.
必ずしも同様の結果になるわけではないので,ご了承ください.
4. 前準備
4.1 データセットのダウンロード
ここからは実装方法の説明をしていきます.
まずは,前準備としてGoogle Colabにデータセットをアップロードします.
ここの工程はこれまでの記事と同じですので,既に行ったことのある方は第4.3項まで飛ばしていただいて構いません.
まず最初に,データセットの格納先からデータをダウンロードし,ご自分のGoogle driveへアップロードしてください.
次のコードでGoogle driveをColabへマウントします.
Google Driveのマウント方法については,補足記事にも記載してあります.
1 2 3 | |
ドライブ内のファイルをColabへコピーします.
パスはアップロード先を設定する必要があります.
# Copy to local.
!cp [path_to_dataset]/gislr_dataset_top10.zip gislr_top10.zip
データセットはZIP形式になっているので unzip コマンドで解凍します.
!unzip gislr_top10.zip
Archive: gislr_top10.zip
creating: dataset_top10/
inflating: dataset_top10/16069.hdf5
...
inflating: dataset_top10/sign_to_prediction_index_map.json
成功すると dataset_top10 以下にデータが解凍されます.
HDF5ファイルはデータ本体で,手話者毎にファイルが別れています.
JSONファイルは辞書ファイルで,TXTファイルは本データセットのライセンスです.
!ls dataset_top10
16069.hdf5 25571.hdf5 29302.hdf5 36257.hdf5 49445.hdf5 62590.hdf5
18796.hdf5 26734.hdf5 30680.hdf5 37055.hdf5 53618.hdf5 LICENSE.txt
2044.hdf5 27610.hdf5 32319.hdf5 37779.hdf5 55372.hdf5 sign_to_prediction_index_map.json
22343.hdf5 28656.hdf5 34503.hdf5 4718.hdf5 61333.hdf5
単語辞書には単語名と数値の関係が10単語分定義されています.
!cat dataset_top10/sign_to_prediction_index_map.json
{
"listen": 0,
"look": 1,
"shhh": 2,
"donkey": 3,
"mouse": 4,
"duck": 5,
"uncle": 6,
"hear": 7,
"pretend": 8,
"cow": 9
}
ライセンスはオリジナルと同様に,CC-BY 4.0 としています.
!cat dataset_top10/LICENSE.txt
The dataset provided by Natsuki Takayama (Takayama Research and Development Office) is licensed under CC-BY 4.0.
Author: Copyright 2024 Natsuki Takayama
Title: GISLR Top 10 dataset
Original licenser: Deaf Professional Arts Network and the Georgia Institute of Technology
Modification
- Extract 10 most frequent words.
- Packaged into HDF5 format.
次のコードでサンプルを確認します.
サンプルは辞書型のようにキーバリュー形式で保存されており,下記のように階層化されています.
- サンプルID (トップ階層のKey)
|- feature: 入力特徴量で `[C(=3), T, J(=543)]` 形状.C,T,Jは,それぞれ特徴次元,フレーム数,追跡点数です.
|- token: 単語ラベル値で `[1]` 形状.0から9の数値です.
1 2 3 4 5 6 7 8 9 | |
['1109479272', '11121526', ..., '976754415']
<KeysViewHDF5 ['feature', 'token']>
(3, 23, 543)
[1]
4.2 モジュールのダウンロード
次に,過去の記事で実装したコードをダウンロードします.
本項は前回までに紹介した内容と同じですので,飛ばしていただいても構いません.
コードはGithubのsrc/modules_gislrにアップしてあります (今後の記事で使用するコードも含まれています).
まず,下記のコマンドでレポジトリをダウンロードします.
!wget https://github.com/takayama-rado/trado_samples/archive/refs/tags/v0.2.1.zip -O master.zip
--2024-08-26 12:12:17-- https://github.com/takayama-rado/trado_samples/archive/refs/tags/v0.2.1.zip
...
2024-08-26 12:12:24 (12.5 MB/s) - ‘master.zip’ saved [80003316]
ダウンロードしたリポジトリを解凍します.
!unzip -o master.zip -d master
Archive: master.zip
23fc135cb7417554dafb2eea052df0791ac3e1fd
creating: master/trado_samples-0.2.1/
inflating: master/trado_samples-0.2.1/.gitignore
...
モジュールのディレクトリをカレントディレクトリに移動します.
!mv master/trado_samples-0.2.1/src/modules_gislr .
他のファイルは不要なので削除します.
!rm -rf master master.zip gislr_top10.zip
!ls
dataset_top10 drive modules_gislr sample_data
4.3 モジュールのロード
主要な処理の実装に先立って,下記のコードでモジュールをロードします.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | |
【コード解説】
- 標準モジュール
- copy: データコピーライブラリ.Macaron Netブロック内でEncoder層をコピーするために使用します.
- json: JSONファイル制御ライブラリ.辞書ファイルのロードに使用します.
- os: システム処理ライブラリ
- sys: Pythonインタプリタの制御ライブラリ.
今回はローカルモジュールに対してパスを通すために使用します.
- functools: 関数オブジェクトを操作するためのライブラリ.
今回はDataLoaderクラスに渡すパディング関数に対して設定値をセットするために使用します.
- inspect.signature: オブジェクトの情報取得ライブラリ.
- pathlib.Path: オブジェクト指向のファイルシステム機能.
主にファイルアクセスに使います.osモジュールを使っても同様の処理は可能です.
高山の好みでこちらのモジュールを使っています(^^;).
- 3rdパーティモジュール
- numpy: 行列演算ライブラリ
- torch: ニューラルネットワークライブラリ
- torchvision: PyTorchと親和性が高い画像処理ライブラリ.
今回はDatasetクラスに与える前処理をパッケージするために用います.
- ローカルモジュール: sys.pathにパスを追加することでロード可能
- dataset: データセット操作用モジュール
- defines: 各部位の追跡点,追跡点間の接続関係,およびそれらへのアクセス処理を
定義したモジュール
- layers: ニューラルネットワークのモデルやレイヤモジュール
- transforms: 入出力変換処理モジュール
- train_functions: 学習・評価処理モジュール
- utils: 汎用処理関数モジュール
5. 認識モデルの実装
5.1 Convolution module
ここから先は,認識モデルを実装していきます.
まず最初に,下記のコードで Convolution module を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | |
【コード解説】
- 引数
- dim_model: 入力特徴量の次元数
- kernel_size: CNN層のカーネルサイズ.
奇数を指定する必要があります.
- norm_type: 正規化層の種別を指定 [batch/layer]
- activation: 活性化関数の種別を指定 [relu/gelu/swish/silu/mish]
- padding_mode: CNN層のパディング方法を指定 [zeros/reflect/replicate/circular]
- causal: True の場合,Causal convolution を適用します.
この手法では未来の情報を含まないように畳み込みを行います.
リアルタイム処理など,現在のフレームよりも過去の情報しか得られない場合の
利用を想定しています.
- 9-48行目: 初期化処理.
- 18-21行目: Causal convolution の場合は畳み込み範囲が過去フレーム側にずれる
ので,パディング長を調整する必要があります.
- 23-48行目: 基本的には各層をインスタンス化するだけです.
`pointwise_conv1` の出力次元数が入力の倍になっている点や,
`depthwise_conv` の `groups` が入力次元数と同じになっている点に注意して
ください.
- 53-70行目: 推論処理.
59-60行目: Causal convolution の場合は,パディング長を大きくした分余計な信号
が含まれるので除去しています.
5.2 Conformer encoder layer
次に下記のコードで,encoder層を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 | |
【コード解説】
- 引数
- dim_model: 入力特徴量の次元数
- num_heads: MHAのヘッド数
- dim_ffw: PFFNの内部特徴次元数
- dropout: Dropout層の欠落率
- activation: 活性化関数の種別を指定 [relu/gelu/swish/silu/mish]
- norm_type_sattn: MHSAブロックの正規化層種別を指定 [batch/layer]
- norm_type_conv: Convolution ブロック手前の正規化層種別を指定 [batch/layer]
- norm_type_ffw: PFFNブロックの正規化層種別を指定 [batch/layer]
- norm_eps: 正規化層内で0除算を避けるための定数
- add_bias: Trueの場合,線形変換層と正規化層にバイアス項を適用.
ただし,LN層がバイアス項に対応していない場合 (古いPyTorch) は無視します.
- conv_kernel_size: Convolution module のカーネルサイズ
- conv_activation: Convolution module の活性化関数
- conv_norm_type: Convolution module の正規化層種別
- conv_paddin_mode: Convolution module のパディング設定
- conv_causal: True の場合,Convolution module で Causal convolution を適用
- conv_layout: Convolution module をMHSA の前後どちらに配置するか [pre/post]
- 19-73行目: 初期化処理.各層を順にインスタンス化しています.
- 75-115行目: MHSA の前に Convolution module を配置した場合の処理
- 117-157行目: MHSA の後ろに Convolution module を配置した場合の処理
- 159-175行目: 推論処理.
- 164-169行目: MHSA用のマスキング配列を作成
- 171-175行目: Convolution module の配置に従って推論処理を実行
5.3 認識モデル
次のコードで,認識モデル全体を実装します.
基本的には Macaron Net と同様 (第4.4項をご参照ください) です.
ただし,Convolution module 用の引数が加わっています.
また,45-60行目で ConformerEncoderLayer を呼び出している点に注意してください.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 | |
5.4 動作チェック
認識モデルの実装ができましたので,動作確認をしていきます.
次のコードでデータセットからHDF5ファイルとJSONファイルのパスを読み込みます.
1 2 3 4 5 6 7 8 | |
dataset_top10/sign_to_prediction_index_map.json
[PosixPath('dataset_top10/2044.hdf5'), PosixPath('dataset_top10/32319.hdf5'), PosixPath('dataset_top10/18796.hdf5'), PosixPath('dataset_top10/36257.hdf5'), PosixPath('dataset_top10/62590.hdf5'), PosixPath('dataset_top10/16069.hdf5'), PosixPath('dataset_top10/29302.hdf5'), PosixPath('dataset_top10/34503.hdf5'), PosixPath('dataset_top10/37055.hdf5'), PosixPath('dataset_top10/37779.hdf5'), PosixPath('dataset_top10/27610.hdf5'), PosixPath('dataset_top10/53618.hdf5'), PosixPath('dataset_top10/49445.hdf5'), PosixPath('dataset_top10/30680.hdf5'), PosixPath('dataset_top10/22343.hdf5'), PosixPath('dataset_top10/55372.hdf5'), PosixPath('dataset_top10/26734.hdf5'), PosixPath('dataset_top10/28656.hdf5'), PosixPath('dataset_top10/61333.hdf5'), PosixPath('dataset_top10/4718.hdf5'), PosixPath('dataset_top10/25571.hdf5')]
次のコードで辞書ファイルをロードして,認識対象の単語数を格納します.
1 2 3 4 5 | |
次のコードで前処理を定義します.
今回は「手話認識入門」で紹介した,各種のデータ拡張を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | |
47-61行目の実装構成が今まで異なる点に注意してください.
まず,追跡点の正規化処理 (trans_norm) を 固定の前処理 (pre_transforms) から動的な前処理へ移動しています.
データ拡張の順番は色々と考えられますが今回は,画像空間系のデータ拡張 \(\rightarrow\) 追跡点の正規化 \(\rightarrow\) 時間系のデータ拡張の順で実行するようにしています.
次のコードで,前処理を適用したHDF5DatasetとDataLoaderをインスタンス化し,データを取り出します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
torch.Size([2, 2, 6, 130])
次のコードでモデルをインスタンス化して,動作チェックをします.
追跡点抽出の結果,入力追跡点数は130で,各追跡点はXY座標値を持っていますので,入力次元数は260になります.
出力次元数は単語数なので10になります.
また,Conformer層の入力次元数は64に設定し,PFFN内部の拡張次元数は256に設定しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | |
ConformerEnISLR(
(linear): Linear(in_features=260, out_features=64, bias=True)
(activation): ReLU()
(pooling): Identity()
(tr_encoder): TransformerEncoder(
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x ConformerEncoderLayer(
(norm_ffw1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw1): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(norm_sattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_conv): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(conv): ConformerConvBlock(
(pointwise_conv1): Conv1d(64, 128, kernel_size=(1,), stride=(1,))
(depthwise_conv): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,), groups=64)
(norm): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): SiLU()
(pointwise_conv2): Conv1d(64, 64, kernel_size=(1,), stride=(1,))
)
(norm_ffw2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw2): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(norm_tail): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(head): GPoolRecognitionHead(
(head): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([2, 10])
(2, 2, 6, 6) (2, 2, 6, 6)
6. 学習と評価
6.1 共通設定
では,実際に学習・評価を行います.
まずは,実験全体で共通して用いる設定値を次のコードで実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Using 2 cores for data loading.
Using cpu for computation.
次のコードで学習・バリデーション・評価処理それぞれのためのDataLoaderクラスを作成します.
1 2 3 4 5 6 7 8 9 10 11 | |
6.2 学習・評価の実行
次のコードでモデルをインスタンス化します.
26行目に示すように,今回はラベルスムージングを有効にしています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
ConformerEnISLR(
(linear): Linear(in_features=260, out_features=64, bias=True)
(activation): ReLU()
(pooling): Identity()
(tr_encoder): TransformerEncoder(
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x ConformerEncoderLayer(
(norm_ffw1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw1): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(norm_sattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_conv): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(conv): ConformerConvBlock(
(pointwise_conv1): Conv1d(64, 128, kernel_size=(1,), stride=(1,))
(depthwise_conv): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,), groups=64)
(norm): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation): SiLU()
(pointwise_conv2): Conv1d(64, 64, kernel_size=(1,), stride=(1,))
)
(norm_ffw2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw2): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(norm_tail): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(head): GPoolRecognitionHead(
(head): Linear(in_features=64, out_features=10, bias=True)
)
)
次のコードで学習・評価処理を行います.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Start training.
--------------------------------------------------------------------------------
Epoch 1
Start training.
loss:3.273161 [ 0/ 3881]
loss:2.059182 [ 3200/ 3881]
Done. Time:14.180027858999978
Training performance:
Avg loss:2.262616
Start validation.
Done. Time:0.4012885429999926
Validation performance:
Avg loss:2.050803
Start evaluation.
Done. Time:1.8339956169999994
Test performance:
Accuracy:23.0%
--------------------------------------------------------------------------------
...
--------------------------------------------------------------------------------
Epoch 50
Start training.
loss:0.912557 [ 0/ 3881]
loss:0.912740 [ 3200/ 3881]
Done. Time:11.34276360900003
Training performance:
Avg loss:0.890870
Start validation.
Done. Time:0.3840015629999698
Validation performance:
Avg loss:0.893136
Start evaluation.
Done. Time:1.776775124999972
Test performance:
Accuracy:87.0%
Minimum validation loss:0.8154004386493138 at 49 epoch.
Maximum accuracy:89.0 at 49 epoch.
以後,同様の処理をアーキテクチャ毎に繰り返します.
コード構成は同じですので,ここでは説明を割愛させていただきます.
また,この後グラフ等の描画も行っておりますが,本記事の主要点ではないため説明を割愛させていただきます.
今回は Conformer を用いた孤立手話単語認識モデルを紹介しましたが,如何でしたでしょうか?
Conformer は音声認識分野で発表された手法で,実装もそこまで難しくないことから一時結構流行っていた印象です.
(Google 社が発表したという点が大きいかもしれませんが)
音声認識は,(i) 時系列を扱う,(ii) 入力が複雑な特徴を持つ,(iii) 連続的な特徴量 → 離散的な特徴量 (テキスト) への変換を行う,など手話認識と共通している点が多いです.
そこから,手話認識では音声認識の手法を取り込んで改良を施すというアプローチが取られる傾向があります.
手話認識モデルの改良に悩んだ場合は,音声認識分野を参考にしてみると良いかもしれません.
今回紹介した話が,これから手話認識や深層学習を勉強してみようとお考えの方に何か参考になれば幸いです.



