classInsertTokensForS2S():def__init__(self,sos_token,eos_token,error_at_exist=False):self.sos_token=sos_tokenself.eos_token=eos_tokenself.error_at_exist=error_at_existdefcheck_format(self,tokens):insert_sos=Falseiftokens[0]!=self.sos_token:insert_sos=Trueelifself.error_at_exist:message=f"The sos_token:{self.sos_token} is exist in {tokens}." \
+"Please check the format."raiseValueError(message)insert_eos=Falseiftokens[-1]!=self.eos_token:insert_eos=Trueelifself.error_at_exist:message=f"The eos_token:{self.eos_token} is exist in {tokens}." \
+"Please check the format."raiseValueError(message)returninsert_sos,insert_eosdef__call__(self,data):tokens=data["token"]dtype=tokens.dtypeinsert_sos,insert_eos=self.check_format(tokens)# Insert.new_tokens=[]ifinsert_sos:new_tokens.append(self.sos_token)new_tokens+=tokens.tolist()ifinsert_eos:new_tokens.append(self.eos_token)new_tokens=np.array(new_tokens,dtype=dtype)data["token"]=new_tokensreturndata
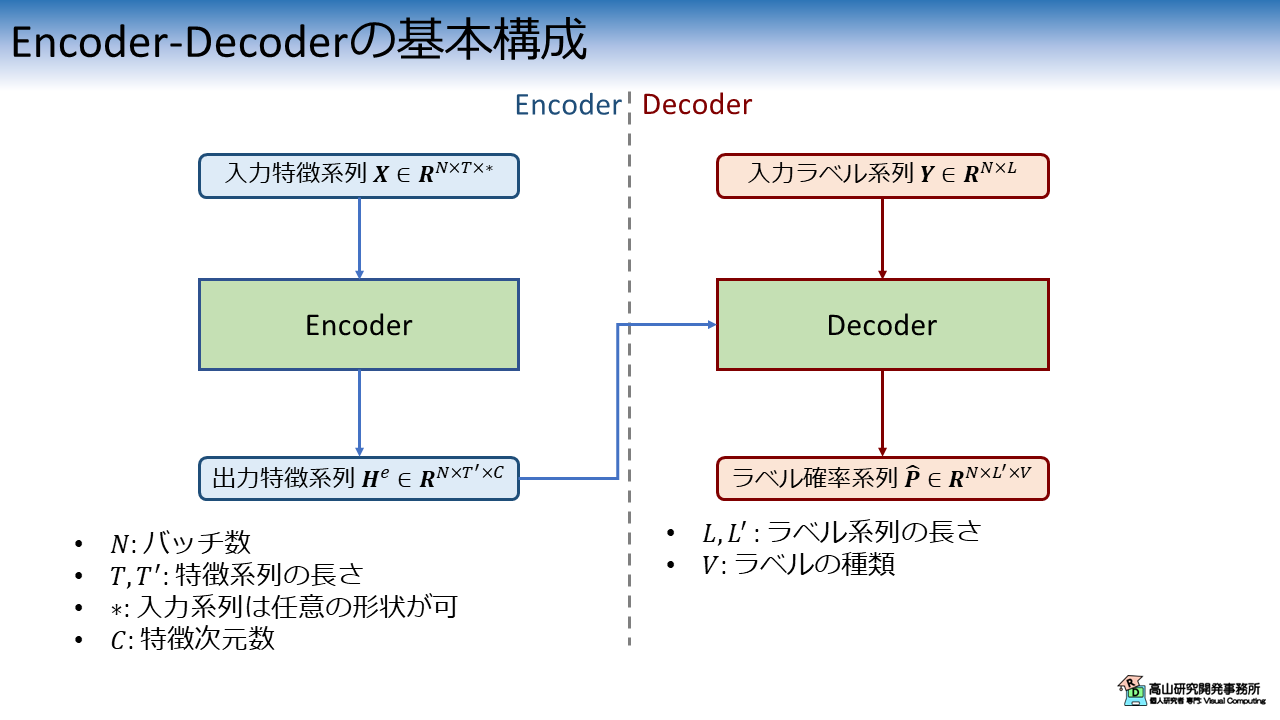
defmerge_padded_batch(batch,feature_shape,token_shape,feature_padding_val=0,token_padding_val=0):feature_batch=[sample["feature"]forsampleinbatch]token_batch=[sample["token"]forsampleinbatch]# ==========================================================# Merge feature.# ==========================================================# `[B, C, T, J]`merged_shape=[len(batch),*feature_shape]# Use maximum frame length in a batch as padded length.ifmerged_shape[2]==-1:tlen=max([feature.shape[1]forfeatureinfeature_batch])merged_shape[2]=tlenmerged_feature=merge(feature_batch,merged_shape,padding_val=feature_padding_val)# ==========================================================# Merge token.# ==========================================================# `[B, L]`merged_shape=[len(batch),*token_shape]# Use maximum token length in a batch as padded length.ifmerged_shape[1]==-1:tlen=max([token.shape[0]fortokenintoken_batch])merged_shape[1]=tlenmerged_token=merge(token_batch,merged_shape,padding_val=token_padding_val)# Generate padding mask.# Pad: 0, Signal: 1# The frames which all channels and landmarks are equals to padding value# should be padded.feature_pad_mask=merged_feature==feature_padding_valfeature_pad_mask=torch.all(feature_pad_mask,dim=1)feature_pad_mask=torch.all(feature_pad_mask,dim=-1)feature_pad_mask=torch.logical_not(feature_pad_mask)token_pad_mask=torch.logical_not(merged_token==token_padding_val)retval={"feature":merged_feature,"token":merged_token,"feature_pad_mask":feature_pad_mask,"token_pad_mask":token_pad_mask}returnretval
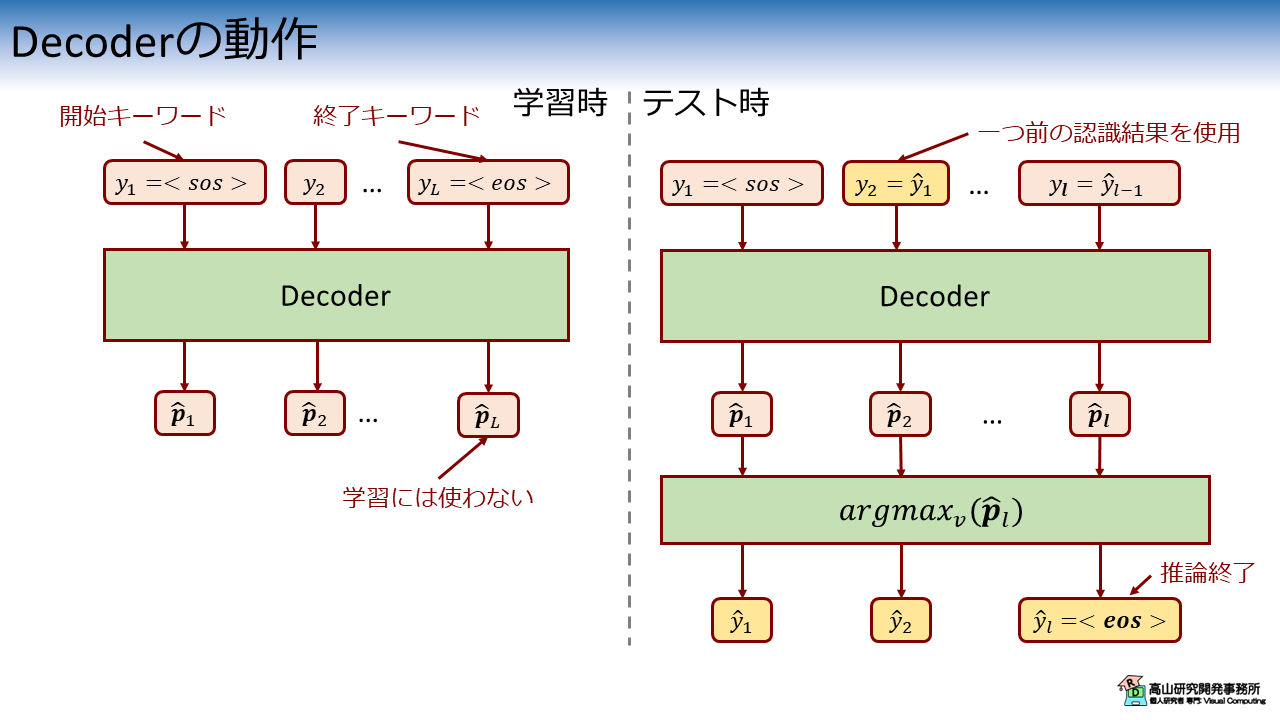
defcheck_tokens_format(tokens,tokens_pad_mask,start_id,end_id):# Check token's format.end_indices0=np.arange(len(tokens))end_indices1=tokens_pad_mask.sum(dim=-1).detach().cpu().numpy()-1message="The start and/or end ids are not included in tokens. " \
f"Please check data format. start_id:{start_id}, " \
f"end_id:{end_id}, enc_indices:{end_indices1}, tokens:{tokens}"ref_tokens=tokens.detach().cpu().numpy()assert(ref_tokens[:,0]==start_id).all(),messageassert(ref_tokens[end_indices0,end_indices1]==end_id).all(),message
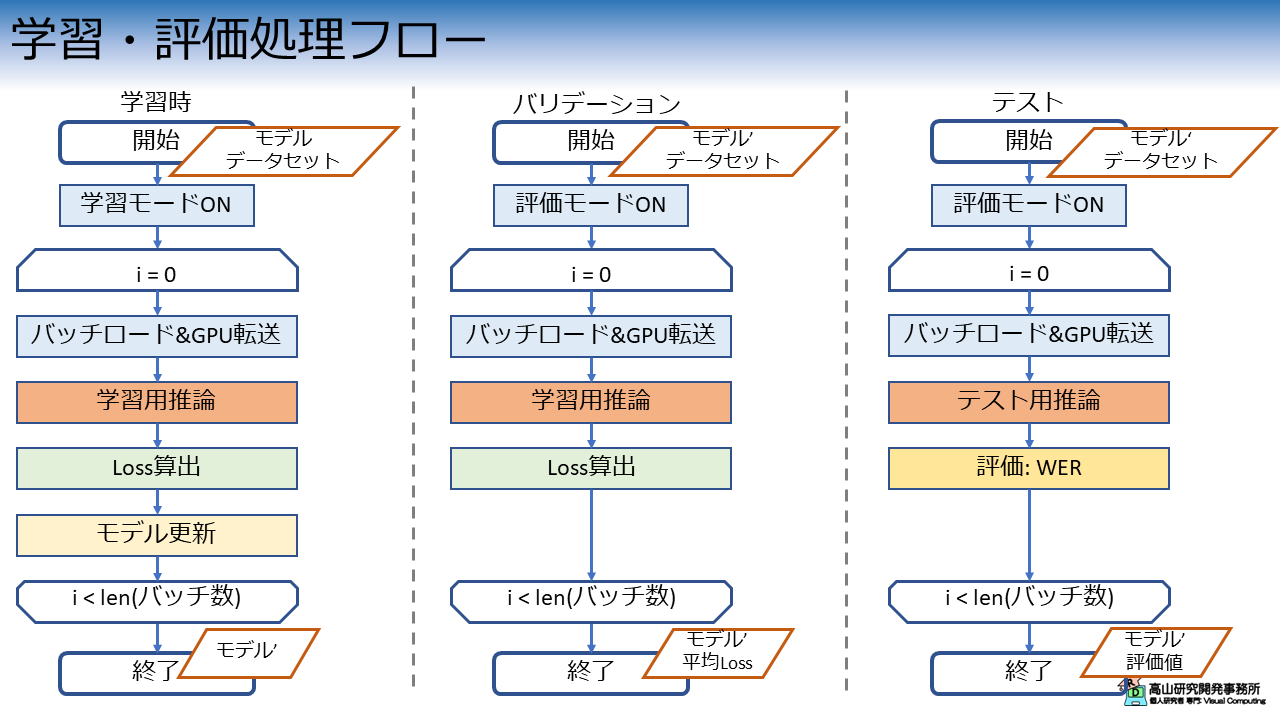
deftrain_loop_csir_s2s(dataloader,model,loss_fn,optimizer,device,start_id,end_id,return_pred_times=False):num_batches=len(dataloader)train_loss=0size=len(dataloader.dataset)# Collect prediction time.pred_times=[]# Switch to training mode.model.train()# Main loop.print("Start training.")start=time.perf_counter()forbatch_idx,batch_sampleinenumerate(dataloader):feature=batch_sample["feature"]feature_pad_mask=batch_sample["feature_pad_mask"]tokens=batch_sample["token"]tokens_pad_mask=batch_sample["token_pad_mask"]check_tokens_format(tokens,tokens_pad_mask,start_id,end_id)feature=feature.to(device)feature_pad_mask=feature_pad_mask.to(device)tokens=tokens.to(device)tokens_pad_mask=tokens_pad_mask.to(device)frames=feature.shape[-2]# Predict.pred_start=time.perf_counter()preds=forward(model,feature,tokens,feature_pad_mask,tokens_pad_mask)pred_end=time.perf_counter()pred_times.append([frames,pred_end-pred_start])# Compute loss.# Preds do not include <start>, so skip that of tokens.loss=0ifisinstance(loss_fn,nn.CrossEntropyLoss):fort_indexinrange(1,tokens.shape[-1]):pred=preds[:,t_index-1,:]token=tokens[:,t_index]loss+=loss_fn(pred,token)loss/=tokens.shape[-1]# LabelSmoothingCrossEntropyLosselse:# `[N, T, C] -> [N, C, T]`preds=preds.permute([0,2,1])# Remove prediction after the last token.ifpreds.shape[-1]==tokens.shape[-1]:preds=preds[:,:,:-1]loss=loss_fn(preds,tokens[:,1:])# Back propagation.optimizer.zero_grad()loss.backward()optimizer.step()train_loss+=loss.item()# Print current loss per 100 steps.ifbatch_idx%100==0:loss=loss.item()steps=batch_idx*len(feature)print(f"loss:{loss:>7f} [{steps:>5d}/{size:>5d}]")print(f"Done. Time:{time.perf_counter()-start}")# Average loss.train_loss/=num_batchesprint("Training performance: \n",f"Avg loss:{train_loss:>8f}\n")pred_times=np.array(pred_times)retval=(train_loss,pred_times)ifreturn_pred_timeselsetrain_lossreturnretval
defval_loop_csir_s2s(dataloader,model,loss_fn,device,start_id,end_id,return_pred_times=False):num_batches=len(dataloader)val_loss=0# Collect prediction time.pred_times=[]# Switch to evaluation mode.model.eval()# Main loop.print("Start validation.")start=time.perf_counter()withtorch.no_grad():forbatch_idx,batch_sampleinenumerate(dataloader):feature=batch_sample["feature"]feature_pad_mask=batch_sample["feature_pad_mask"]tokens=batch_sample["token"]tokens_pad_mask=batch_sample["token_pad_mask"]check_tokens_format(tokens,tokens_pad_mask,start_id,end_id)feature=feature.to(device)feature_pad_mask=feature_pad_mask.to(device)tokens=tokens.to(device)tokens_pad_mask=tokens_pad_mask.to(device)frames=feature.shape[-2]# Predict.pred_start=time.perf_counter()preds=forward(model,feature,tokens,feature_pad_mask,tokens_pad_mask)pred_end=time.perf_counter()pred_times.append([frames,pred_end-pred_start])# Compute loss.# Preds do not include <start>, so skip that of tokens.loss=0ifisinstance(loss_fn,nn.CrossEntropyLoss):fort_indexinrange(1,tokens.shape[-1]):pred=preds[:,t_index-1,:]token=tokens[:,t_index]loss+=loss_fn(pred,token)loss/=tokens.shape[-1]# LabelSmoothingCrossEntropyLosselse:# `[N, T, C] -> [N, C, T]`preds=preds.permute([0,2,1])# Remove prediction after the last token.ifpreds.shape[-1]==tokens.shape[-1]:preds=preds[:,:,:-1]loss=loss_fn(preds,tokens[:,1:])val_loss+=loss.item()print(f"Done. Time:{time.perf_counter()-start}")# Average loss.val_loss/=num_batchesprint("Validation performance: \n",f"Avg loss:{val_loss:>8f}\n")pred_times=np.array(pred_times)retval=(val_loss,pred_times)ifreturn_pred_timeselseval_lossreturnretval
deftest_loop_csir_s2s(dataloader,model,device,start_id,end_id,return_pred_times=False,max_seqlen=62):size=len(dataloader.dataset)total_wer=0# Collect prediction time.pred_times=[]# Switch to evaluation mode.model.eval()# Main loop.print("Start test.")start=time.perf_counter()withtorch.no_grad():forbatch_idx,batch_sampleinenumerate(dataloader):feature=batch_sample["feature"]tokens=batch_sample["token"]tokens_pad_mask=batch_sample["token_pad_mask"]check_tokens_format(tokens,tokens_pad_mask,start_id,end_id)feature=feature.to(device)tokens=tokens.to(device)tokens_pad_mask=tokens_pad_mask.to(device)frames=feature.shape[-2]# Predict.pred_start=time.perf_counter()pred_ids=inference(model,feature,start_id,end_id,max_seqlen=max_seqlen)pred_end=time.perf_counter()pred_times.append([frames,pred_end-pred_start])# Compute WER.# <sos> and <eos> should be removed because they may boost performance.# print(tokens)# print(pred_ids)tokens=tokens[0,1:-1]# pred_ids = pred_ids[0, 1:-1]pred_ids=[pidforpidinpred_ids[0]ifpidnotin[start_id,end_id]]ref_length=len(tokens)wer=edit_distance(tokens,pred_ids)wer/=ref_lengthtotal_wer+=werprint(f"Done. Time:{time.perf_counter()-start}")# Average WER.awer=total_wer/size*100print("Test performance: \n",f"Avg WER:{awer:>0.1f}%\n")pred_times=np.array(pred_times)retval=(awer,pred_times)ifreturn_pred_timeselseawerreturnretval