
目次
こんにちは.高山です.
先日の記事で告知しました手話入門記事の第一回になります.
今回は,PyTorchを使って孤立手話単語認識のデータセットを操作する方法を紹介します.
データセットにはこちらの記事で紹介した,KaggleのGoogle Isolated Sign Language Recognition (以下,GISLR) で用いられたデータセットを用います.
GISLRデータセット本体は数十GBとサイズが大きいため,今回はサンプル数が多い10単語に絞ったデータセットを用います.
こちらのデータセットは予めHDF5ファイルの形式でまとめてあります.
ダウンロードはこちらのリンク先から可能です.
データが大きい (1GB弱あります) のとZIP形式で圧縮しているため,ファイルプレビューはできませんのでご了承ください.
ライセンスはCC-BY 4.0です.
また,今回解説するスクリプトはGitHub上に公開しています.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
- 2024/7/23: 第1節の構成を見直し
- 2024/2/14: データセットのロード方法を変更
1. 機械学習ワークフローとの対応関係
図1は,先日の記事で説明した機械学習モデル構築のワークフローの何処が今回の説明箇所に該当するかを示しています.
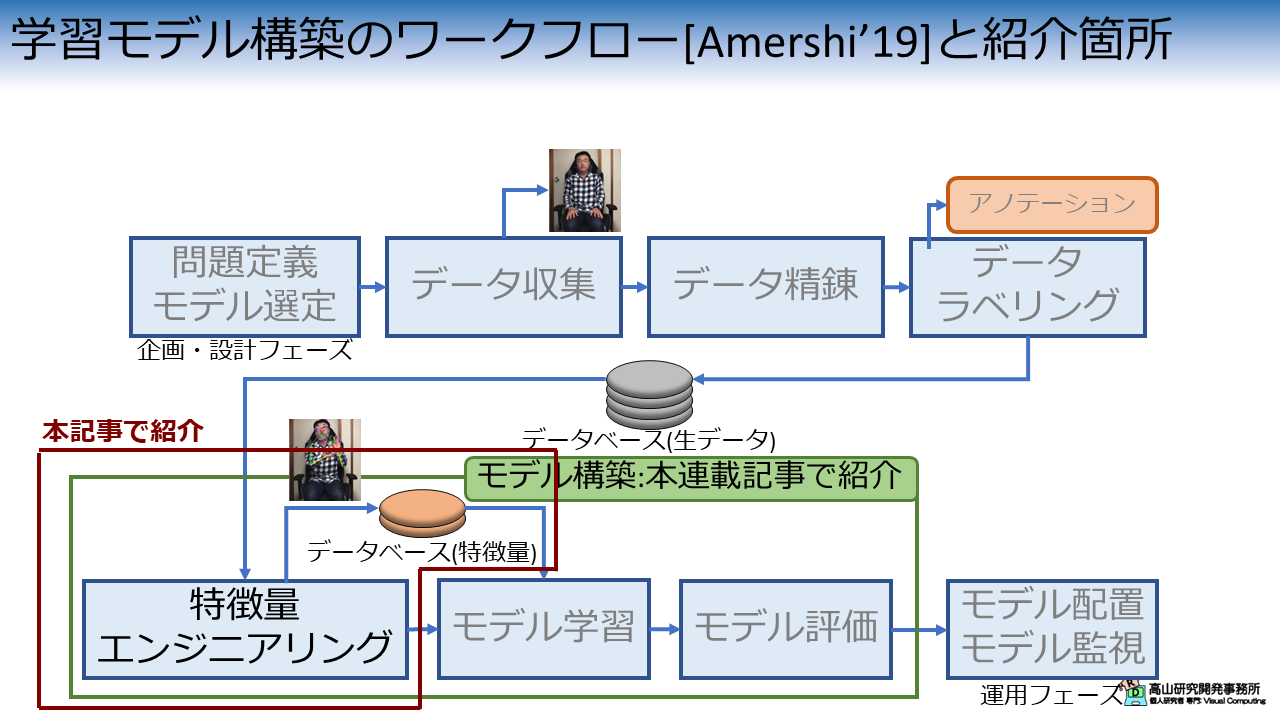
今回説明する内容は,生のデータセットから学習用データセットを作成する特徴量エンジニアリングという処理 (の一部) と,学習用データセットからデータを取り出す処理に該当します.
- [Amershi'19]: S. Amershi, et al., "Software Engineering for Machine Learning: A Case Study," IEEE/ACM ICSE-SEIP 2019.
2. 特徴量エンジニアリング
特徴量エンジニアリングでは,主に図2に示すような処理を行います.
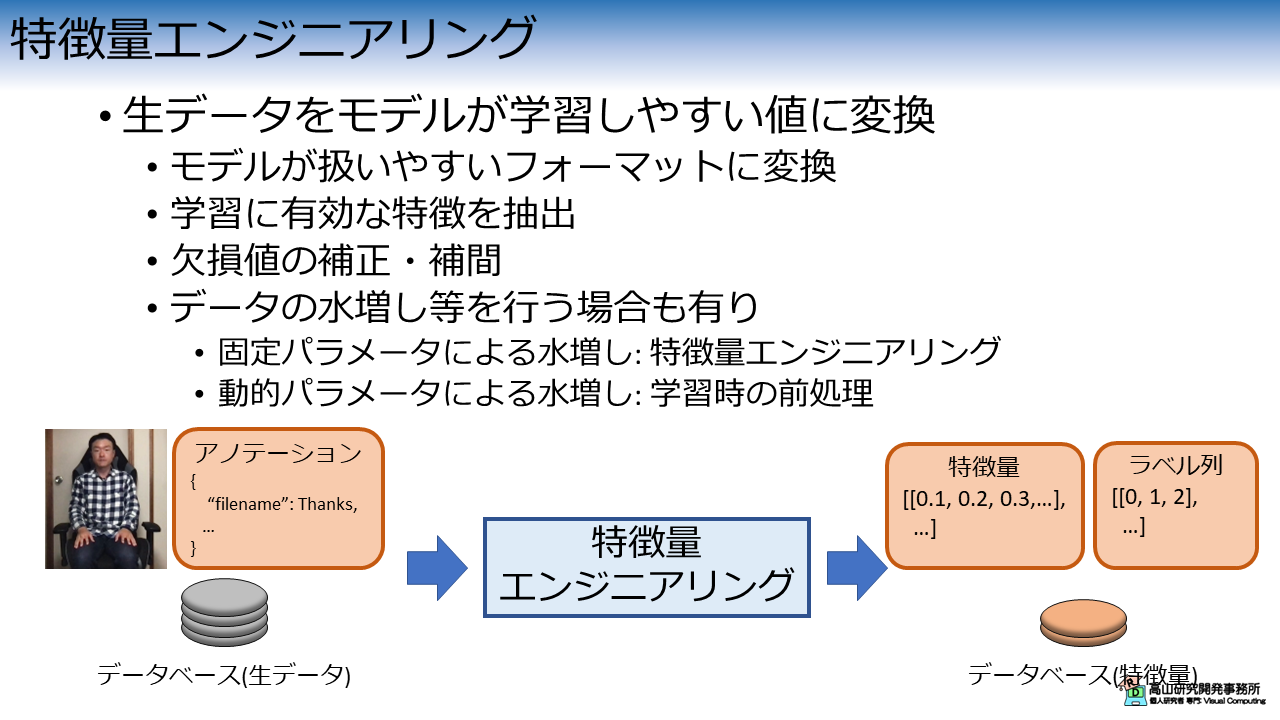
特徴量エンジニアリングでは生データを加工して,モデルが学習しやすい特徴量に変換します.
この工程は単純にモデルが扱いやすいフォーマットに変換することを指す場合もありますが,多くの場合,学習に有効な特徴を抽出するという作業が含まれます.
フォーマットに関しては,先日の記事で紹介したとおり,オリジナルのデータは学習データがCSVファイルとPerquetファイルから構成されていますが,今回使うデータセットはHDF5に再構成されています.
また,生データに欠損値がある場合はそれらの補正や補間を行ったり,データ変換を用いて人工的にデータを増やす操作を行う場合も有ります.
特に,固定パラメータによる変換処理は学習時に行うと不要な処理が増えることになりますので,特徴量エンジニアリングの中で処理するようにした方が良いです.
これらについては今回は深掘りせず,また別の記事で説明したいと思います.
3. 学習データへのアクセス
さて,学習用データベースが用意できたとして,実際の学習を行うためには,データベースにアクセスする機能を実装する必要があります.
データベースアクセス処理に必要な機能を図3に示します.
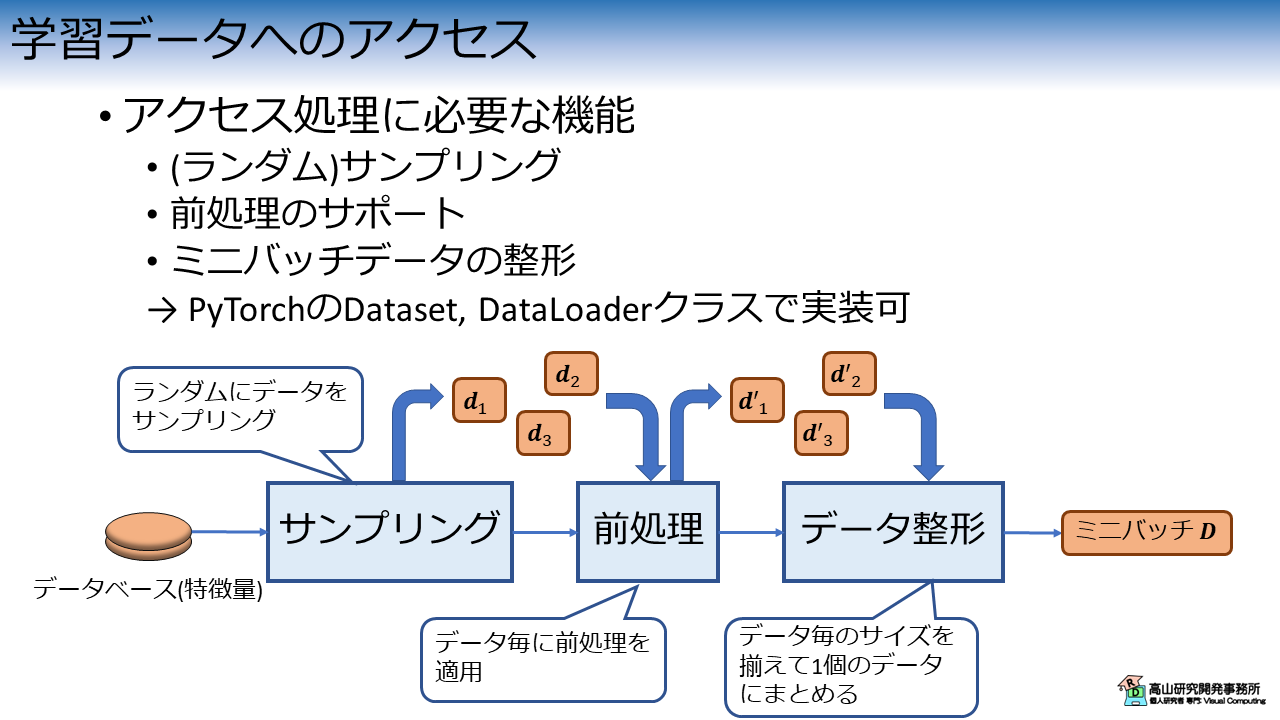
データベースのアクセス処理として必要な機能としては,
- (ランダム) サンプリング機能: データベースから任意個数のデータをロード.
データの並び方が学習結果へ影響を及ぼすのを防ぐためにランダムにサンプリングすることが多いです - 前処理のサポート: 補正・補間や動的なパラメータによるデータ変換など
- ミニバッチデータの整形: サンプリングしたデータを一個の多次元データにまとめる
PyTorchでは,これらの処理を効率的に実装するためのテンプレートクラスがDataset, DataLoaderクラスとして用意されています.
今回はこれらのクラスを利用して実装していきます.
4. 前準備
4.1 モジュールのロード
主要な処理の実装に先立って,まず最初に下記のコードでモジュールをロードします.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
【コード解説】
- 標準モジュール
- functools: 関数オブジェクトを操作するためのライブラリ.
今回はDataLoaderクラスに渡すパディング関数に対して設定値をセットするために使用します.
- pathlib.Path: オブジェクト指向のファイルシステム機能.
主にファイルアクセスに使います.osモジュールを使っても同様の処理は可能です.
高山の好みでこちらのモジュールを使っています(^^;).
- typing: 関数などに型アノテーションを行う機能.
ここでは型を忘れやすい関数に付けていますが,本来は全てアノテーションをした方が良いでしょう(^^;).
- 3rdパーティモジュール
- h5py: HDF5ファイルを取り扱うモジュール
- numpy: 行列演算ライブラリ
- torch: ニューラルネットワークライブラリ
- torchvision: PyTorchと親和性が高い画像処理ライブラリ.
今回はDatasetクラスに与える前処理をパッケージするために用います.
4.2 データセットのダウンロードとデータの確認
次に,データセットをダウンロードします.
まずは,前準備としてGoogle Colabにデータセットをアップロードします.
以前までは,gdown を用いてダウンロードしていたのですが,このやり方ですと多数の方がアクセスした際にトラブルになるようなので (多数のご利用ありがとうございます!),セットアップの方法を少し変えました.
まず最初に,データセットの格納先からデータをダウンロードし,ご自分のGoogle driveへアップロードしてください.
次のコードでGoogle driveをColabへマウントします.
Google Driveのマウント方法については,補足記事にも記載してあります.
1 2 3 | |
ドライブ内のファイルをColabへコピーします.
パスはアップロード先を設定する必要があります.
# Copy to local.
!cp [path_to_dataset]/gislr_dataset_top10.zip gislr_top10.zip
データセットはZIP形式になっているので unzip コマンドで解凍します.
!unzip gislr_top10.zip
Archive: gislr_top10.zip
creating: dataset_top10/
inflating: dataset_top10/16069.hdf5
...
inflating: dataset_top10/sign_to_prediction_index_map.json
成功すると dataset_top10 以下にデータが解凍されます.
HDF5ファイルはデータ本体で,手話者毎にファイルが別れています.
JSONファイルは辞書ファイルで,TXTファイルは本データセットのライセンスです.
!ls dataset_top10
16069.hdf5 25571.hdf5 29302.hdf5 36257.hdf5 49445.hdf5 62590.hdf5
18796.hdf5 26734.hdf5 30680.hdf5 37055.hdf5 53618.hdf5 LICENSE.txt
2044.hdf5 27610.hdf5 32319.hdf5 37779.hdf5 55372.hdf5 sign_to_prediction_index_map.json
22343.hdf5 28656.hdf5 34503.hdf5 4718.hdf5 61333.hdf5
単語辞書には単語名と数値の関係が10単語分定義されています.
!cat dataset_top10/sign_to_prediction_index_map.json
{
"listen": 0,
"look": 1,
"shhh": 2,
"donkey": 3,
"mouse": 4,
"duck": 5,
"uncle": 6,
"hear": 7,
"pretend": 8,
"cow": 9
}
ライセンスはオリジナルと同様に,CC-BY 4.0 としています.
!cat dataset_top10/LICENSE.txt
The dataset provided by Natsuki Takayama (Takayama Research and Development Office) is licensed under CC-BY 4.0.
Author: Copyright 2024 Natsuki Takayama
Title: GISLR Top 10 dataset
Original licenser: Deaf Professional Arts Network and the Georgia Institute of Technology
Modification
- Extract 10 most frequent words.
- Packaged into HDF5 format.
次のコードでサンプルを確認します.
サンプルは辞書型のようにキーバリュー形式で保存されており,下記のように階層化されています.
- サンプルID (トップ階層のKey)
|- feature: 入力特徴量で `[C(=3), T, J(=543)]` 形状.C,T,Jは,それぞれ特徴次元,フレーム数,追跡点数です.
|- token: 単語ラベル値で `[1]` 形状.0から9の数値です.
1 2 3 4 5 6 7 8 9 | |
['1109479272', '11121526', ..., '976754415']
<KeysViewHDF5 ['feature', 'token']>
(3, 23, 543)
[1]
5. データアクセス処理の実装
ここから先はデータアクセス処理について説明していきます.
実装の構成について説明します.
今回は図4に示すDataset,DataLoader,および簡単な前処理クラスを実装します.
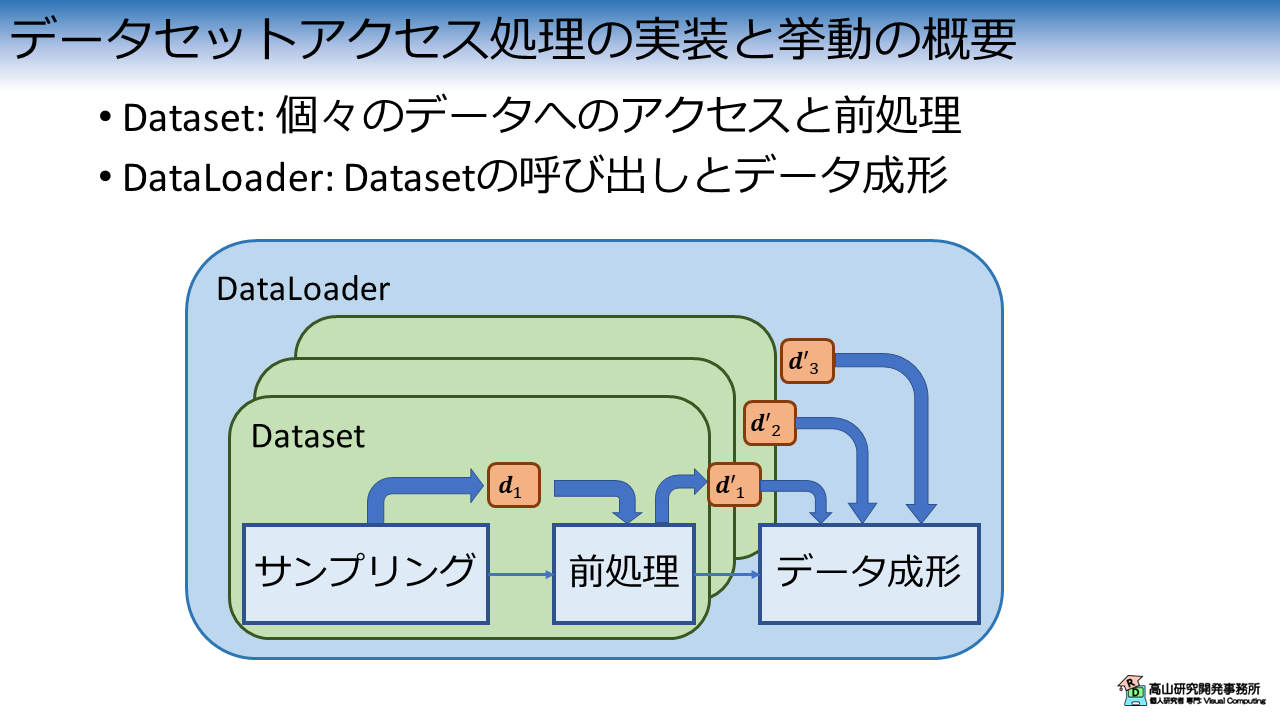
PyTorchでは個々のデータへのアクセスと前処理をDatasetクラスに実装します.
DataLoaderはDatasetの呼び出しとデータ成形を担当します.
クラスの初期化時にDatasetとデータ成形関数を引数として渡すことで全体の処理が実行できるようになります.
最終的には,学習処理からDataLoaderクラスを呼び出すことでバッチデータをロードすることができます.
なお,通常はDatasetクラスには動的な前処理を実装して,固定パラメータの前処理は学習データ作成時に (特徴量エンジニアリングの工程として) 行うことが多いです.
説明の関係上,毎回異なる学習用データセットを用意するのは煩わしいので,今回は固定パラメータによる前処理もDatasetクラス上で行えるように実装します.
5.1 前処理クラス
まず最初に,Datasetクラスから呼び出す前処理クラスを実装します.
前処理クラスでは補正・補間やデータ拡張など様々な処理を実装することが多いですが,ここでは極簡単なnumpy型の配列をTorch.Tensor型に変換する処理を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
【コード解説】
- 7-8行目: このクラスはtorchvision.transform.Composeクラスから呼び出されることを想定しています.
Composeクラスは__call__()メソッドを介して各クラスを呼び出すので
(正確には,インスタンスオブジェクトを直接呼び出すので),
__call__()メソッドに処理を実装しています.
- 10-25行目: ループで辞書データの要素を取り出して,numpy配列をtorch.Tensor型に変換しています
- 12-18行目: 要素がリスト型だった場合は,サブ要素を取り出して変換します
- 19-24行目: 要素がnumpy配列だった場合はそのまま変換します
5.2 Datasetクラス
次のコードは,HDF5形式のファイルをロードして,呼び出しに応じてサンプルを返すクラスを実装しています.
このクラスはDatasetクラスを継承しており,DataLoaderクラスを通じて呼び出されます.
Datasetクラスを継承したクラスは,下記のメソッドを実装する必要があります.
- init(): インスタンス化処理
- len(): ロードしたデータのサンプル数を返す
- getitem(): インデックスで指定したサンプルを返す
詳細については,公式ドキュメントを参照してください.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | |
【コード解説】
- 引数
- hdf5files: HDF5ファイルパスのリストです.
各要素はPathクラスのインスタンスであることを想定しています.
- load_into_ram: `True`の場合は,`__init__()`内でデータをメモリに読み込みます.
`__getitem__()`呼び出し時は読み込んだデータをそのまま使用します.
`False`の場合は,ファイルパスとデータIDだけを保持し,`__getitem__()`呼び出し時に実データを都度ロードします.
- pre_transforms: 固定パラメータを想定した前処理クラスを保持します.
`load_into_ram=True` の場合は,`__init__()`内で全データに処理を適用します.
`load_into_ram=False` の場合は,`__getitem__()`呼び出し時に各データに都度処理を適用します.
- transforms: 動的パラメータを想定した前処理クラスを保持します.
`__getitem__()`呼び出し時に各データに都度処理を適用します.
- 1行目: PyTorchのDatasetクラスを継承しています.
- 11-31行目: データ読み込み処理
各HDF5を開き,ファイルパス,データID,話者ID,左右反転データかどうかのフラグ,
実データ (`load_into_ram=True`時) を読み込みます.
- 34-56行目: 前処理クラスの適正チェック
transformsはComposeクラスのインスタンスで,かつ,末尾要素がToTensorクラスのインスタンスである必要があります.
transformsの適正をチェックし,変換可能な場合は変換します.
- 58-69行目: サンプルの取り出し処理
- 59-65行目: 実データを `data` へロード
- 66-69行目: 前処理クラスを適用し `data` を返す
- 71-72行目: サンプル数を返す処理
Datasetクラスの実装ができましたので,実際に動かしてみます.
まず,次のコードでデータセットからHDF5ファイルとJSONファイルのパスを読み込みます.
1 2 3 4 5 6 7 8 | |
dataset_top10/sign_to_prediction_index_map.json
[PosixPath('dataset_top10/37055.hdf5'), PosixPath('dataset_top10/34503.hdf5'), ..., PosixPath('dataset_top10/61333.hdf5')]
次に,HDF5Datasetをインスタンス化し,__len__(), __getitem()__ メソッドの動作確認をします.
__len__() メソッドは len() 関数にインスタンスを与えることで呼び出すことができます.
また,__getitem()__ メソッドはイテレータやfor文を介して呼び出すことができます.
1 2 3 4 5 6 7 8 9 | |
4081
torch.Size([3, 23, 543])
tensor([2])
どちらのメソッドも,問題なく動作していることが確認できます.
5.3 DataLoaderクラス
パディング処理について
DataLoaderクラスの実装に先立って,パディング処理について説明したいと思います.
深層学習では多くの場合,複数のデータをまとめたバッチデータを入力として学習を行います.
複数のデータをまとめることで,GPUの並列演算による学習処理の高速化が期待できます.
また,複数のデータから統計的な特徴を得ることで学習性能を挙げることも可能です.
しかし,時系列データをバッチデータに整形する場合は注意が必要です.
時系列データをバッチデータに整形する様子を図5に示します.
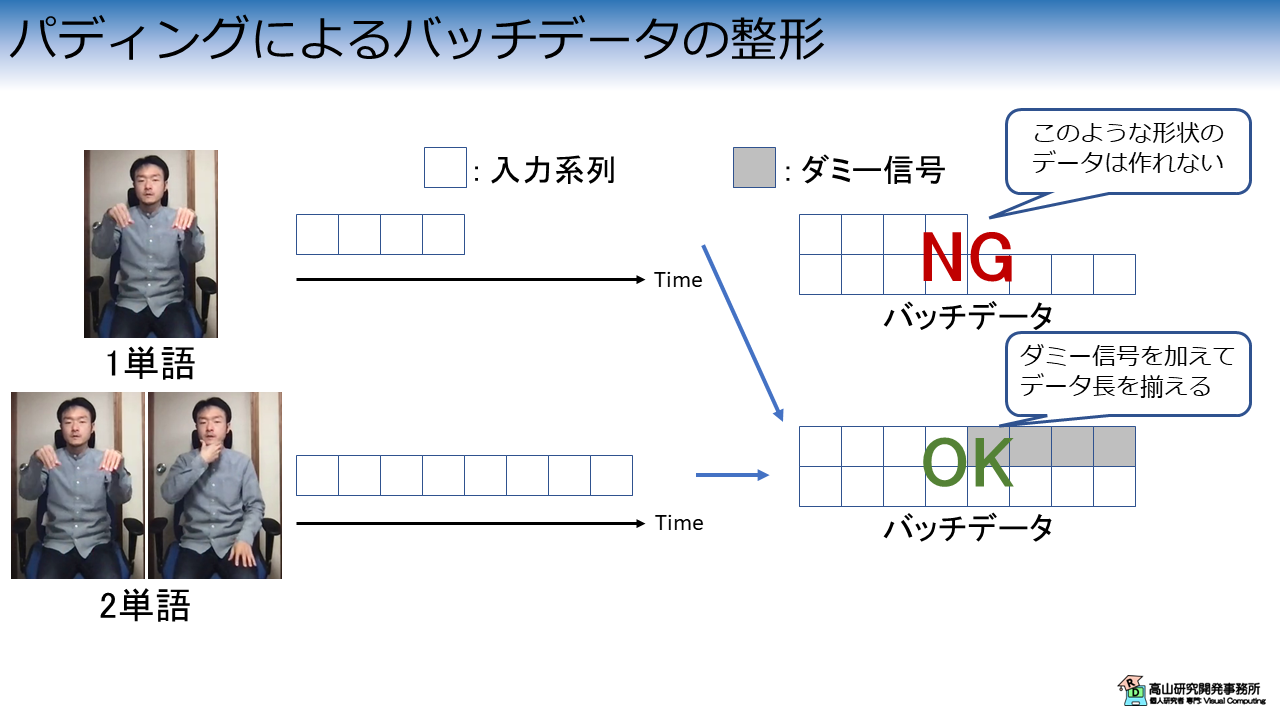
例えば,DataLoaderクラスが1単語と2単語のデータをそれぞれサンプリングしたとします.
このようなケースでは各データの時間長が大きく異なります.
右上の例のように異なる時間長のデータをそのまま混ぜることはできません.
このようなケースでは,次に示すテクニックがよく使われます.
- クリッピング: 固定長でデータを切り出す処理
シンプルな動作認識ではよく使われます.
ただし,長さが大きく異なるケースで短いデータに合わせてクリップすると認識性能が落ちる場合があります. - 時系列ワーピング: データを時系列方向に伸縮します.
- パディング: 短いデータにダミー信号を加えて信号長をそろえる
実際には,前処理の中でこれらのテクニックを組み合わせて複雑な変換を行います.
今回はパディングだけを取り上げて,他の処理については別記事で取り上げたいと思います.
パディング処理が無い場合の挙動
まずは,パディング処理が無い場合に,DataLoaderがどのような挙動をするかを見てみましょう.
DataLoaderは,Datasetクラスのインスタンスとバッチサイズを与えることでインスタンスを作成します.
データはDatasetクラスと同様に,for文やイテレータを介して取り出すことができます.
1 2 3 4 5 6 7 8 9 | |
torch.Size([1, 3, 88, 543])
tensor([[1]])
batch_size=1 の場合は問題なく動作するようです.
Datasetクラスの呼び出し時とは異なり,先頭にバッチ内のデータインデックスを示す軸が追加されている点に注意してください.
では次に,batch_size=2 としてDataLoaderを呼び出してみます.
1 2 3 4 5 6 7 8 9 10 11 12 | |
stack expects each tensor to be equal size, but got [3, 88, 543] at entry 0 and [3, 87, 543] at entry 1
先程とは異なり,取り出したデータの形状が異なるためエラーになっていることが分かります.
パディング処理の実装
では,上記のエラーを解消するためにパディング処理を実装していきます.
まず,次のコードで汎用的なパディング関数を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
【コード解説】
- 引数
- sequences: データのリスト.
各要素はDatasetクラスから取り出した1サンプルだが,配列であること(辞書ではなく)を想定
- merged_shape: 結合後のバッチデータの形状
- padding_val: パディングのためのダミー値
- 2-4行目: バッチデータを `padding_val` で埋めて生成
- 5-26行目: `merged` に各サンプルを代入
各サンプルのデータ長を調べながら先頭詰めで代入している点に注意
次に,下記のコードで今回のデータセット向けのパディング処理全体を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
【コード解説】
- 引数
- batch: データのリスト.
各要素はDatasetクラスから取り出した1サンプル (辞書データ)
- feature_shape: バッチに結合後の入力特徴量形状
- token_shape: バッチに結合後の出力ラベル形状
- feature_padding_val: 入力特徴量のパディング用ダミー値
- token_padding_val: 出力ラベルのパディング用ダミー値
- 6-7行目: 入力特徴量と出力ラベルを取り出して,それぞれリスト化
- 13-18行目: 入力特徴量のバッチデータ作成.
時系列長が指定されていない場合(-1の場合),バッチ内の最大長を用いてバッチデータを作成する
- 24-25行目: 出力ラベルのバッチデータ作成
- 31-35行目: パディング値の場所が分かるようにマスク信号を生成.
ここでは,元の信号が`True`,ダミー値が`False`となるようにマスクを生成している.
形状は,
feature_pad_mask: `[N, T]`, Tは時系列長
token_pad_mask: `[N, L]`, Lはラベル長 (今回は1固定)
- 37-42行目: 戻り値を辞書型でまとめて返す
パディング処理がある場合の挙動
では,パディング処理がある場合の挙動を見てみましょう.
パディング処理はDataLoaderクラスの collate_fn に関数オブジェクトを渡すことで呼び出すことができます.
merge_padded_batch() はデータセット依存の引数がありますので,呼び出し側で partial() 関数を使って予め設定しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
torch.Size([2, 3, 88, 543])
tensor([[1],
[5]])
tensor([[ True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, False]])
tensor([[True],
[True]])
先程とは異なり,正常に動作させることができました.
feature_pad_mask の2行目の配列で一部がFalseになっている点に注目してください.
False の値はダミー値を示しています.
今回は単純な確認用にマスクを生成していますが,実際のモデル学習ではマスクを利用してモデルがダミー値の影響を受けないように処理を構成することもよく行われます.
今回はPyTorchを使って孤立手話単語認識のデータセットを操作する方法を紹介しましたが,如何でしたでしょうか?
今回はベースとなる機能を中心に紹介しましたが,追加の機能についてはまた別記事で紹介しようと思います.
今回紹介した話が,これから手話認識を勉強してみようとお考えの方に何か参考になれば幸いです.




