
目次
こんにちは.高山です.
先日の記事で告知しました手話入門記事の第二回になります.
今回は,PyTorchを使って孤立手話単語認識モデルを実装する方法を紹介します.
認識性能についてはひとまず置いておき,今回はシンプルなモデルを使って学習・評価の処理構成に焦点をおいて説明します.
今回紹介するモデルと学習・評価処理をベースとして,次回以降の記事で性能を改善する方法を紹介していきます.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
- 2024/07/29: Gitスクリプトのダウンロード元を
masterからv0.1タグに変更 - 2024/07/23: 第1節の構成を見直し
- 2024/02/14: データセットのロード方法を変更
1. 機械学習ワークフローとの対応関係
図1は,先日の記事で説明した機械学習モデル構築のワークフローの何処が今回の説明箇所に該当するかを示しています.
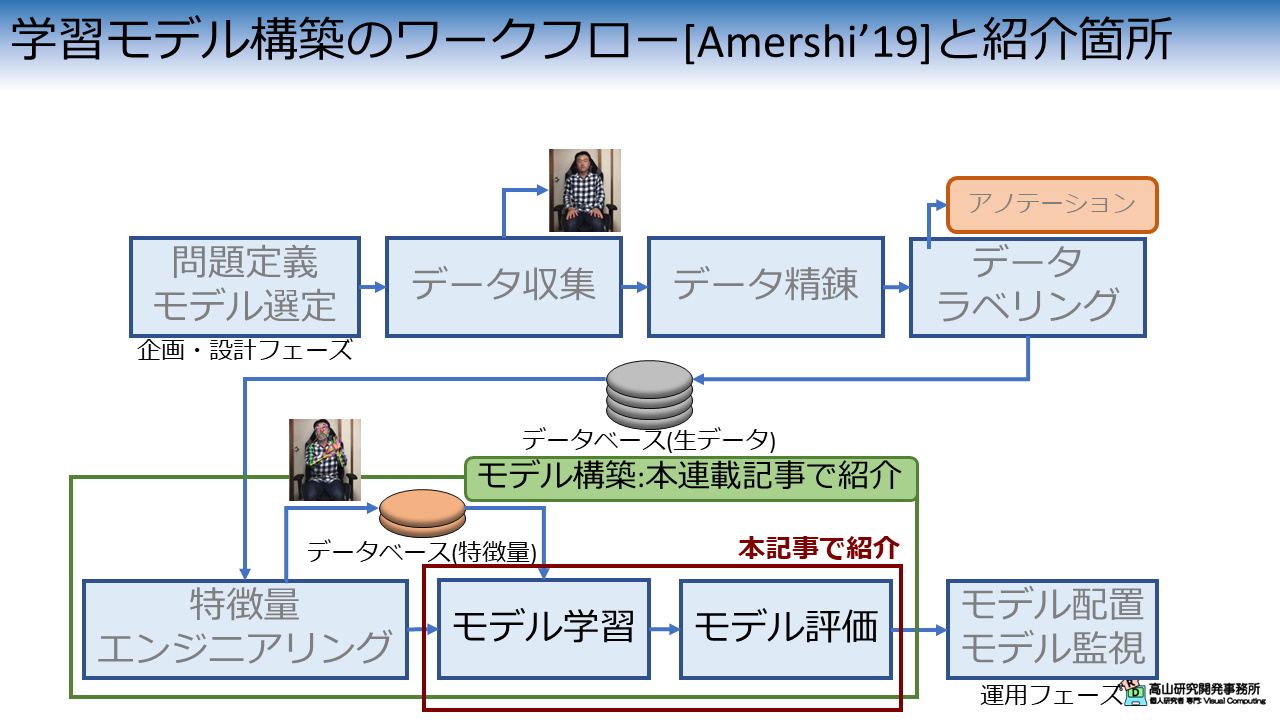
今回説明する内容は,モデルの学習・評価処理に該当します.
これらの処理を動作させるためにはモデルおよび学習・評価処理の実装だけでなく,前工程にあたる特徴量エンジニアリングやデータベースのアクセス処理も実装する必要があります.
この記事ではモデルと学習・評価処理の実装に注力し,前工程については第一回の実装を流用したいと思います.
- [Amershi'19]: S. Amershi, et al., "Software Engineering for Machine Learning: A Case Study," Proc. of the IEEE/ACM ICSE-SEIP, available here, 2019.
2. 孤立手話単語認識
孤立手話単語認識について説明します.
孤立手話単語認識は図2に示すように,手話動画を入力して1単語を認識するタスクです.
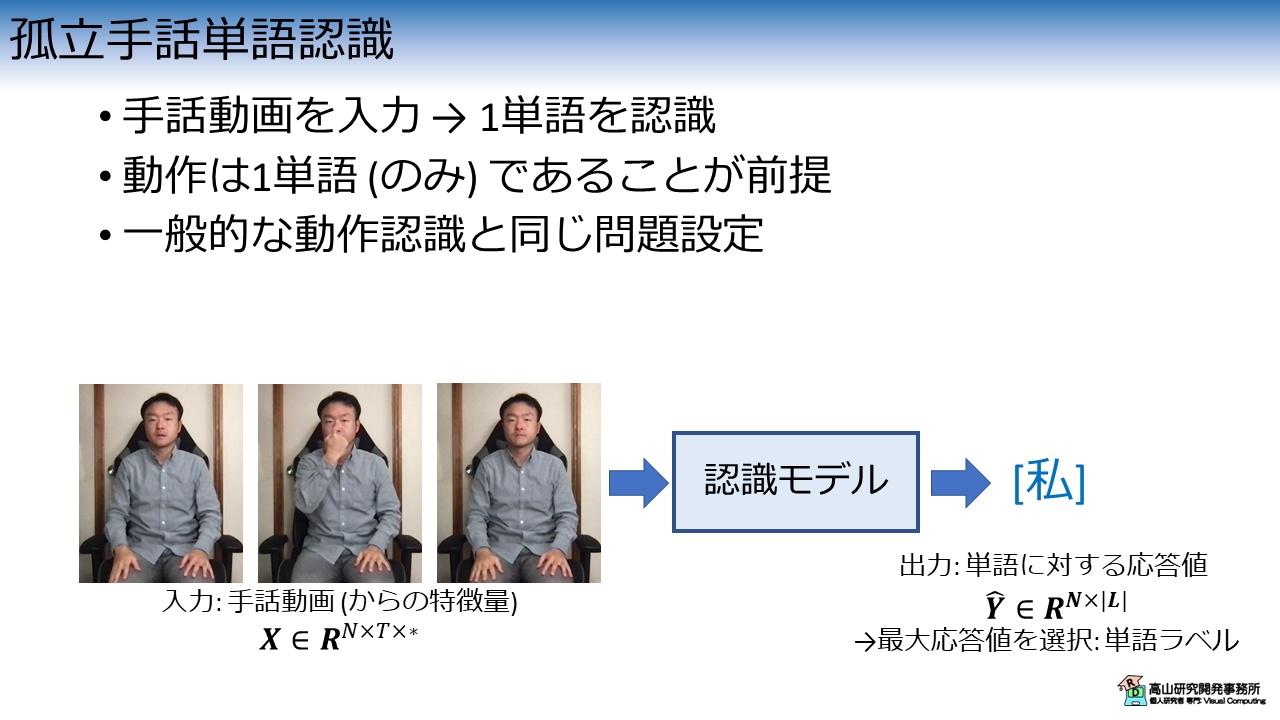
ここで,動作は1単語のみを表していることが前提になっています.
孤立手話単語認識は代表的な動作認識タスク[Soomro'12, Kay'17]とほぼ同じ問題設定になっているため,動作認識の手法が流用しやすいという特徴があります.
孤立手話単語認識モデルでは,時系列の入力データ \(\boldsymbol{X} \in \boldsymbol{R}^{N \times T \times *}\) を単語ラベル \(\hat{\boldsymbol{Y}} \in \boldsymbol{R}^{N \times |\boldsymbol{L}|}\) に変換します.
ここで,\(N, T\) は,それぞれバッチデータのサンプル数と時系列長を示します.
\(*\) は特徴量などの次元を表し,入力に応じて変わります.
例えば,動画フレームを直接入力する場合は \(H \times W \times C\) (\(H\): フレーム高さ,\(W\): フレーム幅,\(C\): RGB値など) と表せますし,追跡点の場合は \(J \times C\) (\(J\): 追跡点数,\(C\): XY座標値など) と表せます.
\(|L|\) は認識対象の単語数 (今回は10) を示します.
\(\hat{\boldsymbol{Y}}\) は各単語に対する応答値の分布になっています.
応答値が高い単語は,モデルが入力を見て,その単語の可能性が高いと判断していることを示しています.
最終的に,最大応答値を出力しているインデクスを選択することで単語ラベルが得られます.
- [Soomro'12]: K. Soomro, et al., " UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild," CRCV-TR-12-01, available here, 2012.
- [Kay'17]: W. Kay, et al., "The Kinetics Human Action Video Dataset," available here, 2017.
3. モデルの基本構造
3.1 共通処理
それでは,モデルの構造を見ていきましょう.
図3は孤立手話単語認識モデルの基本構造を示しています.
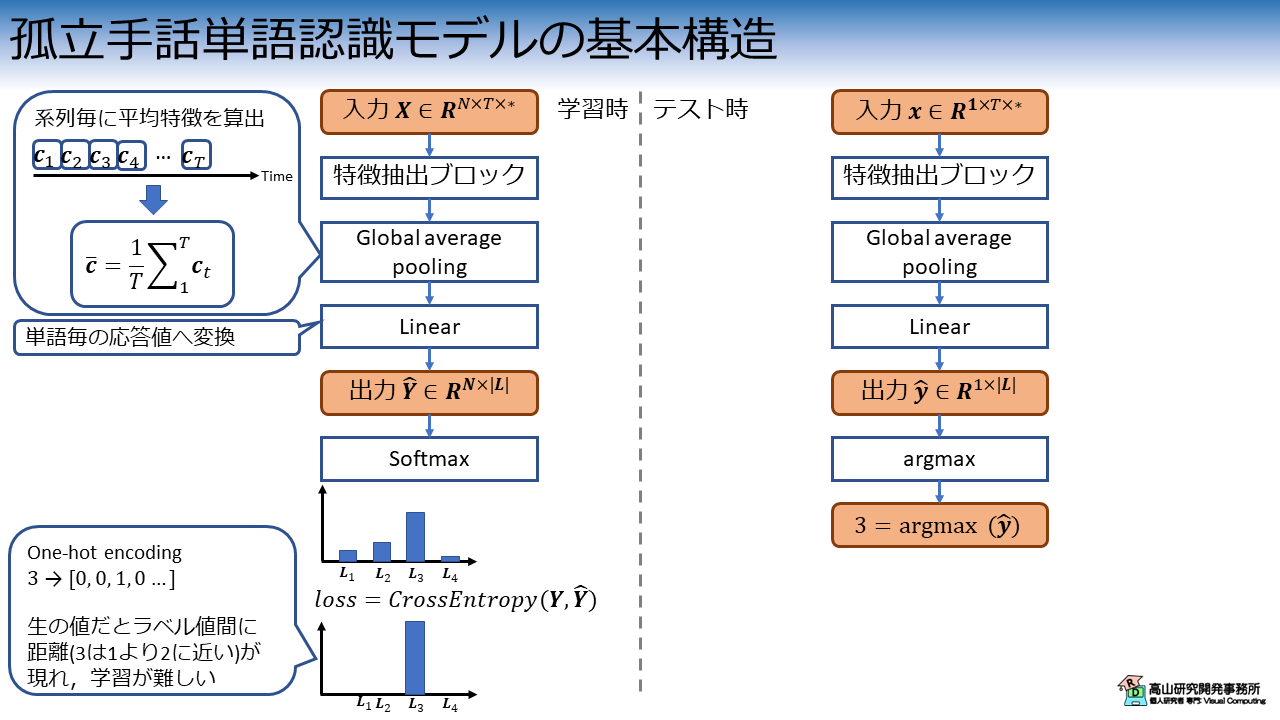
孤立手話単語認識モデルでは,まず時系列の入力データ \(\boldsymbol{X}\) に対して特徴抽出を行います.
その後,特徴抽出後の系列 \(\boldsymbol{c}\) に Global average pooling を行い,単一の特徴ベクトル \(\bar{\boldsymbol{c}}\) に変換します.
Global average pooling は全特徴量の平均値を求める操作です.
ここでは時系列の特徴量を想定していますので,時間インデクスを \(t \in \{1, \ldots, T\}\) とすると,Global average pooling は下記のように表すことができます.
最後に,線形変換を行って各単語に対する応答値 \(\hat{\boldsymbol{Y}}\) に変換します.
ここまでは,学習・テストともに処理は同じです.
図3に示すとおり,孤立手話単語認識モデルでは特徴抽出ブロックが主要な処理を担うため,認識性能に大きく影響します.
これらの改善については,別記事で取り上げたいと思います.
3.2 学習時の処理
学習時はここから,推論結果と正解データとの違いを表すLoss値を計算して,Loss値が小さくなるようにモデルのパラメータを更新していきます.
正解データはOne-hot encodingと呼ばれる方法で表されます.
これは,各単語を表すインデクス値をそのまま用いるのではなく,多次元ベクトルで表す形式です.
例えば,正解データのインデクス値が\(3\)の場合,そのOne-hot encodingは\([0, 0, 1, 0, 0, 0, 0, 0, 0, 0]\)になります (単語インデクスが1始まりの場合).
One-hot encodingで表した正解データは,正解インデクスに対応する要素だけが \(1\) となり,他は \(0\) となるカテゴリカル分布になっています (各要素が \([0, 1]\) の範囲で総和が \(1\) なので確率分布になっています).
モデルの出力は各単語に対する応答値ですので正解データとはスケールが異なっています.
そこで,Softmax という処理を用いて各単語に対する応答値をスケーリングします.
1サンプル分の応答分布を \(\hat{\boldsymbol{y}} \in R^{1 \times |\boldsymbol{L}|}\) とすると,Softmax処理は下記のように表すことができます.
\(i, j \in \{1, 2, \ldots, L \}\) は単語インデクスを示します.
この処理によってモデルの応答値分布は,各要素が \([0, 1]\) の範囲で総和が \(1\) の確率分布にスケーリングされます.
正解データ,出力ともに確率分布の形で表すことができると,確率分布間の類似性や違いを表す指標を用いてLoss値を求めることができます.
確率分布間の類似性を示す指標としては,交差エントロピー誤差 (Cross-Entropy Loss) やKL情報量 (Kullback-Leibler Divergence) がよく使われます.
(本筋からそれてしまうので説明は割愛します(^^;))
3.3 テスト時の処理
テスト時も基本的な処理は同じです.
ただし,テスト時は応答値が最大の単語インデクスが分かればよいので,argmax処理で算出できます.
argmaxは,関数や集合などに対して最大値を与える引数を返す処理です.
今回のケースでは,モデルの出力は \(\hat{\boldsymbol{y}}=\{\hat{y}_i\}\) のように表せますので,これにargmax処理を適用すればよいです.
例えば,\(y_3\) が最大値の場合は,\(3 = \mathrm{argmax}_i (\hat{\boldsymbol{y}})\) のようにしてモデルが予想する単語インデクスを求めることができます.
3.4 なぜ出力を分布で表すのか
なぜモデルは単語インデクス (1や2など) ではなく,応答値の分布を多次元ベクトルで出力するのでしょうか?
生のインデクス値を用いて学習をしようとすると,単語間に距離の概念が発生します.
例えば,3の単語は1の単語よりも2の単語に近い,というような関係性が生まれてしまいます.
単語のラベル値は実装の都合で振られているだけなので,このような関係性が生まれてしまうと学習が難しくなってしまいます.
このような理由から,One-hot encoding 表現が用いられます.
4. 前準備
4.1 データセットのダウンロード
ここからは実装方法の説明をしていきます.
まずは,前準備としてGoogle Colabにデータセットをアップロードします.
以前までは,gdown を用いてダウンロードしていたのですが,このやり方ですと多数の方がアクセスした際にトラブルになるようなので (多数のご利用ありがとうございます!),セットアップの方法を少し変えました.
まず最初に,データセットの格納先からデータをダウンロードし,ご自分のGoogle driveへアップロードしてください.
次のコードでGoogle driveをColabへマウントします.
Google Driveのマウント方法については,補足記事にも記載してあります.
1 2 3 | |
ドライブ内のファイルをColabへコピーします.
パスはアップロード先を設定する必要があります.
# Copy to local.
!cp [path_to_dataset]/gislr_dataset_top10.zip gislr_top10.zip
データセットはZIP形式になっているので unzip コマンドで解凍します.
!unzip gislr_top10.zip
Archive: gislr_top10.zip
creating: dataset_top10/
inflating: dataset_top10/16069.hdf5
...
inflating: dataset_top10/sign_to_prediction_index_map.json
成功すると dataset_top10 以下にデータが解凍されます.
HDF5ファイルはデータ本体で,手話者毎にファイルが別れています.
JSONファイルは辞書ファイルで,TXTファイルは本データセットのライセンスです.
!ls dataset_top10
16069.hdf5 25571.hdf5 29302.hdf5 36257.hdf5 49445.hdf5 62590.hdf5
18796.hdf5 26734.hdf5 30680.hdf5 37055.hdf5 53618.hdf5 LICENSE.txt
2044.hdf5 27610.hdf5 32319.hdf5 37779.hdf5 55372.hdf5 sign_to_prediction_index_map.json
22343.hdf5 28656.hdf5 34503.hdf5 4718.hdf5 61333.hdf5
単語辞書には単語名と数値の関係が10単語分定義されています.
!cat dataset_top10/sign_to_prediction_index_map.json
{
"listen": 0,
"look": 1,
"shhh": 2,
"donkey": 3,
"mouse": 4,
"duck": 5,
"uncle": 6,
"hear": 7,
"pretend": 8,
"cow": 9
}
ライセンスはオリジナルと同様に,CC-BY 4.0 としています.
!cat dataset_top10/LICENSE.txt
The dataset provided by Natsuki Takayama (Takayama Research and Development Office) is licensed under CC-BY 4.0.
Author: Copyright 2024 Natsuki Takayama
Title: GISLR Top 10 dataset
Original licenser: Deaf Professional Arts Network and the Georgia Institute of Technology
Modification
- Extract 10 most frequent words.
- Packaged into HDF5 format.
次のコードでサンプルを確認します.
サンプルは辞書型のようにキーバリュー形式で保存されており,下記のように階層化されています.
- サンプルID (トップ階層のKey)
|- feature: 入力特徴量で `[C(=3), T, J(=543)]` 形状.C,T,Jは,それぞれ特徴次元,フレーム数,追跡点数です.
|- token: 単語ラベル値で `[1]` 形状.0から9の数値です.
1 2 3 4 5 6 7 8 9 | |
['1109479272', '11121526', ..., '976754415']
<KeysViewHDF5 ['feature', 'token']>
(3, 23, 543)
[1]
4.2 モジュールのダウンロード
次に,第一回で実装したコードをダウンロードします.
コードはGithubのsrc/modules_gislrにアップしてあります (今後の記事で使用するコードも含まれています).
まず,下記のコマンドでレポジトリをダウンロードします.
(目的のディレクトリだけダウンロードする方法はまだ調査中です(^^;))
!wget https://github.com/takayama-rado/trado_samples/archive/refs/tags/v0.1.zip -O master.zip
--2024-01-21 11:01:47-- https://github.com/takayama-rado/trado_samples/archive/master.zip
Resolving github.com (github.com)... 140.82.112.3
...
2024-01-21 11:01:51 (19.4 MB/s) - ‘master.zip’ saved [75710869]
ダウンロードしたリポジトリを解凍します.
!unzip -o master.zip -d master
Archive: master.zip
641b06a0ca7f5430a945a53b4825e22b5f3b8eb6
creating: master/trado_samples-main/
inflating: master/trado_samples-main/.gitignore
...
モジュールのディレクトリをカレントディレクトリに移動します.
!mv master/trado_samples-main/src/modules_gislr .
他のファイルは不要なので削除します.
!rm -rf master master.zip gislr_top10.zip
!ls
dataset_top10 drive modules_gislr sample_data
4.3 モジュールのロード
主要な処理の実装に先立って,下記のコードでモジュールをロードします.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
【コード解説】
- 標準モジュール
- json: JSONファイル制御ライブラリ.辞書ファイルのロードに使用します.
- math: 数学計算処理ライブラリ
- sys: Pythonインタプリタの制御ライブラリ.
今回はローカルモジュールに対してパスを通すために使用します.
- functools: 関数オブジェクトを操作するためのライブラリ.
今回はDataLoaderクラスに渡すパディング関数に対して設定値をセットするために使用します.
- pathlib.Path: オブジェクト指向のファイルシステム機能.
主にファイルアクセスに使います.osモジュールを使っても同様の処理は可能です.
高山の好みでこちらのモジュールを使っています(^^;).
- typing: 関数などに型アノテーションを行う機能.
ここでは型を忘れやすい関数に付けていますが,本来は全てアノテーションをした方が良いでしょう(^^;).
- 3rdパーティモジュール
- numpy: 行列演算ライブラリ
- torch: ニューラルネットワークライブラリ
- torchvision: PyTorchと親和性が高い画像処理ライブラリ.
今回はDatasetクラスに与える前処理をパッケージするために用います.
- ローカルモジュール: sys.pathにパスを追加することでロード可能
- dataset: データセット操作用モジュール
- transforms: 入出力変換処理モジュール
5. 前処理の実装
これまで深く触れてきませんでしたが,GISLRデータセットは追跡に失敗している追跡点が多数含まれており,それらは NaN (Not a Numberの略) という特殊な値になっています.
NaN は学習に使えませんので,下記のコードで NaN を0に置き換えます.
(簡単な処理ですので説明は割愛します)
1 2 3 4 5 6 7 8 9 10 11 12 | |
ReplaceNanクラスの動作を確認します.
まず,次のコードでデータセットからHDF5ファイルとJSONファイルのパスを読み込みます.
1 2 3 4 5 6 7 8 | |
dataset_top10/sign_to_prediction_index_map.json
[PosixPath('dataset_top10/34503.hdf5'), ..., PosixPath('dataset_top10/2044.hdf5')]
次のコードで辞書ファイルをロードして,認識対象の単語数を格納します.
1 2 3 4 5 | |
次に,HDF5DatasetとDataLoaderをインスタンス化し,データを取り出してみます.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
torch.Size([2, 3, 88, 543])
tensor([[1],
[5]])
tensor([[ True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True],
[ True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, False]])
tensor([[True],
[True]])
データは問題なく取り出せたので,feature の中身を見てみます.
1 2 | |
tensor([[[[ 0.3574, 0.3642, 0.3579, ..., nan, nan, nan],
[ 0.3601, 0.3618, 0.3556, ..., nan, nan, nan],
[ 0.3620, 0.3612, 0.3551, ..., nan, nan, nan],
...,
[-0.0506, -0.0759, -0.0458, ..., nan, nan, nan],
[-0.0510, -0.0759, -0.0461, ..., nan, nan, nan],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]]])
tensor(True)
上の表示結果から分かるように,nan が多数含まれていることが分かります.
では,先程実装したReplaceNanをHDF5Datasetに与え,再度インスタンス化してデータを取り出してみます.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
tensor([[[[ 0.3574, 0.3642, 0.3579, ..., 0.0000, 0.0000, 0.0000],
[ 0.3601, 0.3618, 0.3556, ..., 0.0000, 0.0000, 0.0000],
[ 0.3620, 0.3612, 0.3551, ..., 0.0000, 0.0000, 0.0000],
...,
[-0.0506, -0.0759, -0.0458, ..., 0.0000, 0.0000, 0.0000],
[-0.0510, -0.0759, -0.0461, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]]])
tensor(False)
先の表示で nan だった箇所が0に置き換わっていることが分かります.
6. 孤立手話単語認識モデルの実装
ここから先は,認識モデルを実装していきます.
まずは,Global average pooling を行って,さらに単語応答値へ変換するレイヤを実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
【コード解説】
- 引数
- in_channels: 入力特徴量の次元数
- out_channels: 出力特徴量の次元数.単語応答値を出力したいので,全単語数と同じにします.
- 1行目: PyTorchのカスタムレイヤはnn.Moduleクラスを継承する必要があります.
- 5-10行目: 初期化処理.
- 5行目: nn.Moduleを継承したクラスは,親クラスの`__init__()`を呼び出す必要があります.
- 9行目: 単語毎の応答値に変換する線形変換レイヤを作成
- 12-15行目: `self.head` のパラメータ初期化処理
- 17-25行目: 推論処理
- 20-21行目: Global average pooling処理.
`avg_pool1d()` のカーネルサイズを時系列長にすることで時系列全体の平均値を求めています.
- 24行目: 単語毎の応答値に変換
次に,認識モデル全体を実装します.
今回はコードの全体像を掴むことが目的ですので,特徴ブロックはシンプルな線形変換と活性化関数だけで実装しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
【コード解説】
- 引数
- in_channels: 入力特徴量の次元数
- out_channels: 出力特徴量の次元数.単語応答値を出力したいので,全単語数と同じにします.
- 3-7行目: 初期化処理.
特徴ブロックとして線形変換とReLU活性化関数を用いています.
内部の特徴次元数は64としています (適当です(^^;)).
その後,先程実装したGPoolRecognitionHeadクラスを作成しています.
- 9-22行目: 推論処理
- 12-14行目: Linearレイヤに合わせて,入力形状を`[N, C, T, J] -> [N, T, C*J]`に変換
- 16-17行目: 特徴変換フロック適用
- 20-21行目: GPoolRecognitionHead適用
それでは,モデルの動作チェックをしてみます.
入力追跡点数は543で,各追跡点はXYZ座標値を持っていますので,入力次元数は1629になります.
出力次元数は単語数なので10になります.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
SimpleISLR(
(linear): Linear(in_features=1629, out_features=64, bias=True)
(activation): ReLU()
(head): GPoolRecognitionHead(
(head): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([2, 10])
問題なく,\(N \times |L|\) 形状の出力が得られています.
なお,PyTorchでは print(model) のようにするとモデルのレイヤ構造を出力することが可能です.
7. 学習ループの実装
7.1 処理構成
では,実装したモデルを使用して学習・評価を行っていきます.
図4は学習・評価処理の処理構成を示しています.
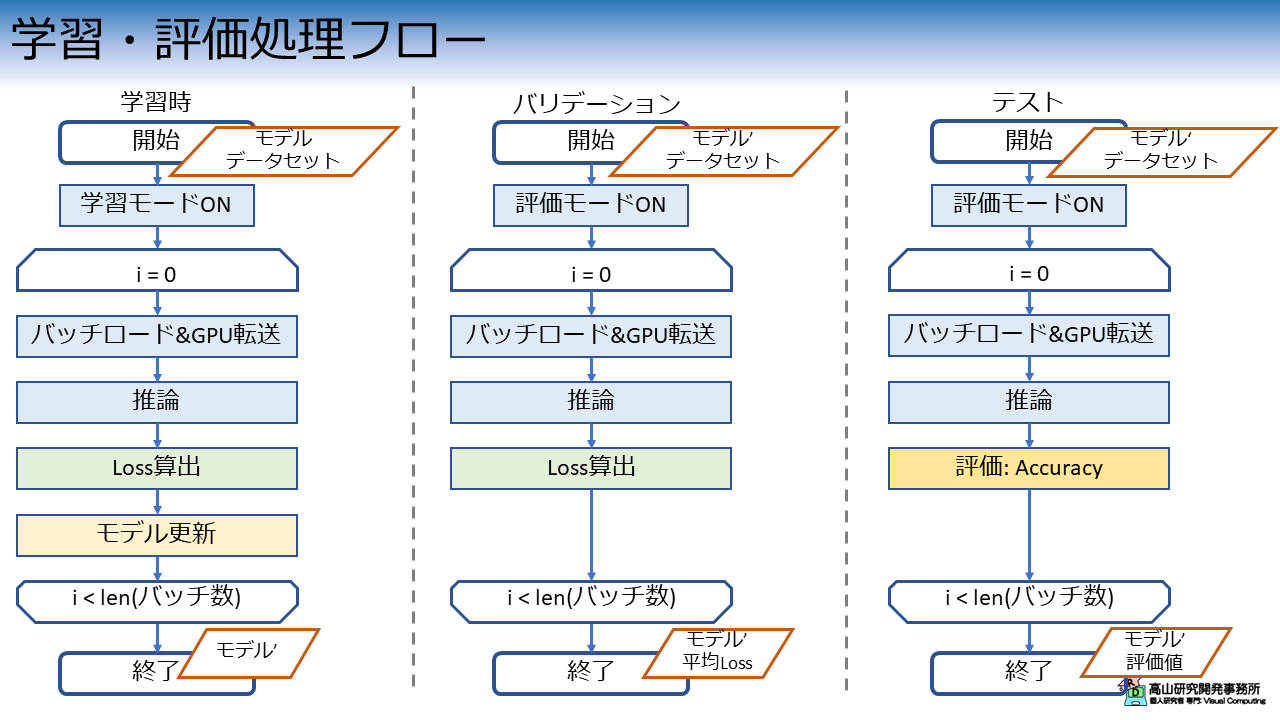
図4に示すとおり,学習・評価処理には学習ループ,バリデーションループ,テストループの3種類の処理があります.
各ループでは最初にモデルを適切なモードに設定します.
この処理自体は難しいところは何もありませんが,この処理を忘れると学習が上手くいかなくなり,かつ,エラーも発生しませんので見つけづらいバグになりますので注意してください.
学習ループでは,データをロード後推論を行い,Loss算出とモデルの更新を行います.
バリデーションループはLoss算出までは学習ループと同じですが,モデルの更新は行いません.
バリデーションで使用するデータは学習には使わず,モデルが過学習していないかをモニタリングするために使用します.
テストループでは推論後Loss算出は行わず,規定の評価指標でモデルの認識性能を評価します.
孤立手話単語認識では,単純な認識率がよく使われます.
今回はこれらのループを1セットとして,任意回数繰り返して学習と評価を行う実装をしています.
7.2 学習ループ
まずは,次のコードで学習ループを実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
【コード解説】
- 引数
- dataloader: DataLoaderクラスのインスタンス
- model: 認識モデルのインスタンス
- loss_fn: Loss関数のインスタンス
- optimizer: モデルのパラメータ制御クラスのインスタンス
- device: 計算処理を行うデバイスを示す文字列 ("cpu"や"cuda"など)
- 2行目: データ数を取得.この値は学習の進捗を表示するために使用します.
- 5行目: モデルを学習モードに切り替え
- 9-28行目: 学習ループ
- 10-13行目: バッチデータをロードしてデバイス (CPUやGPU) に転送
- 16-17行目: 推論後,Loss値を算出
- 20-22行目: モデルのパラメータを更新
- 25-28行目: 学習の進捗状況を表示
7.3 バリデーションループ
次に,バリデーションループを実装します.
認識モデルが評価モードになっている点と,モデルパラメータ更新を行わない点に注意してください.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
【コード解説】
- 引数
- dataloader: DataLoaderクラスのインスタンス
- model: 認識モデルのインスタンス
- loss_fn: Loss関数のインスタンス
- device: 計算処理を行うデバイスを示す文字列 ("cpu"や"cuda"など)
- 2行目: バッチ数を取得.この値は平均Loss値を算出するために使用します.
- 6行目: モデルを評価モードに切り替え
- 10-18行目: バリデーションループ
- 10行目: ループを `with torch.no_grad()` で囲むことで,パラメータ更新に使用する
勾配計算処理をOFFにしています.
これにより無駄なメモリ消費と計算を抑制することができます.
- 12-15行目: バッチデータをロードしてデバイス (CPUやGPU) に転送
- 17-18行目: 推論後,Loss値を算出.また,平均Lossを計算するために総和Lossを計算.
- 22-25行目: 平均Loss値を計算して返す
7.4 テストループ
最後に,テストループを実装します.
認識モデルが評価モードになっている点と,Lossではなく認識率を計算している点に注意してください.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
【コード解説】
- 引数
- dataloader: DataLoaderクラスのインスタンス
- model: 認識モデルのインスタンス
- device: 計算処理を行うデバイスを示す文字列 ("cpu"や"cuda"など)
- 2行目: データ数を取得.この値は認識率を計算するために使用します.
- 6行目: モデルを評価モードに切り替え
- 10-20行目: テストループ
- 10行目: ループを `with torch.no_grad()` で囲むことで,パラメータ更新に使用する
勾配計算処理をOFFにしています.
これにより無駄なメモリ消費と計算を抑制することができます.
- 12-15行目: バッチデータをロードしてデバイス (CPUやGPU) に転送
- 17-20行目: 推論後,最大応答値となる単語インデクスを算出.
その後,正解ラベルと比較することで正解数を算出.
後で認識率を計算するための正解数の総和を計算.
- 23-25行目: 認識率を計算して返す
8. 学習と評価の実行
全ての処理が実装できましたので,実際に学習・評価を行ってみます.
まず,次のコードで学習・バリデーション・評価処理それぞれのためのDataLoaderクラスを作成します.
ここでは,ID:16069の手話者データをバリデーションと評価処理用とし,その他を学習用データとしています.
(横着して同じ手話者にしていますが,本当はバリデーションと評価も,それぞれ別手話者にした方が良いです(^^;))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
次に,Loss関数とモデルパラメータ更新の制御クラスをインスタンス化しています.
Loss算出には交差エントロピー誤差を用いて,パラメータ更新にはAdam法[Kingma'15]を用います.
1 2 | |
次のコードで学習・評価処理を行います.
今回は10回各ループを繰り返してみて (ここでの繰り返し数は,エポックと呼ばれます),最小Lossと最大認識率を表示します.
難しいところはありませんが,6行目でモデルをデバイスに転送している点に注意してください.
モデルとデータを異なるデバイスに転送するとエラーになります.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Using cpu for computation.
Start training.
--------------------------------------------------------------------------------
Epoch 1
Start training.
loss:2.374237 [ 0/ 3881]
loss:2.310635 [ 3200/ 3881]
Done. Time:15.682512226000028
Start validation.
Done. Time:1.03349592699999
Validation performance:
Avg loss:2.299444
Start evaluation.
Done. Time:0.8781382120000103
Test performance:
Accuracy:15.0%
--------------------------------------------------------------------------------
...
--------------------------------------------------------------------------------
Epoch 10
Start training.
loss:2.078655 [ 0/ 3881]
loss:2.278803 [ 3200/ 3881]
Done. Time:22.57564999600004
Start validation.
Done. Time:1.1715261269999928
Validation performance:
Avg loss:2.245935
Start evaluation.
Done. Time:0.9451968230000602
Test performance:
Accuracy:15.0%
Minimum validation loss:2.245934554508754 at 10 epoch.
Maximum accuracy:15.0 at 1 epoch.
問題なく学習・評価処理が実行できました.
表示結果から,15.0%程度の認識率が最初のエポックで達成し,その後改善していないことが分かりますが,今回は認識性能には注力していませんので特に気にする必要はありません.
認識性能の改善については別記事で取り上げていきます.
- [Kingma'15]: D. P. Kingma, et al., "Adam: A Method for Stochastic Optimization," Proc. of the ICLR, available here, 2015.
今回はPyTorchを使って孤立手話単語認識のモデルを実装し,学習・評価を行ってみましたが,如何でしたでしょうか?
今回は認識性能は取り敢えず無視して,全体の処理構成を把握することに注力しました.
経験の少ないタスクに取り組む際は,高性能なモデルや複雑なフレームワークにいきなり取り組むのではなく,今回のようなトイモデルでまず動作や処理構成を理解することが重要です.
トイモデルをベースに少しづつ改善していくと,何処かの段階で自然と高性能なモデルやフレームワークを利用したくなります.
その時に切り替えればタスクは十分に理解できているはずなので,コードの移植やフレームワークの切り替えはスムーズにできると思います.
(個人的意見です(^^;))
今回紹介した話が,これから手話認識を勉強してみようとお考えの方に何か参考になれば幸いです.




