目次
こんにちは.高山です.
今まで手話認識や手話翻訳に関連する技術をいくつか紹介してきましたが,ふと振り返ってみて大本の手話認識・翻訳技術に全く触れずにここまで来てしまったことに今更気が付きました(^^;).
そこで今回は手話認識と手話翻訳について簡単に紹介したいと思います.
実は,手話に関連する技術は認識や翻訳以外にも色々と取り組まれています.
今回はそれらについても簡単に触れながら紹介していきたいと思います.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
- 2023/12/07: 記事タイトルを変更しました.
1. 様々な手話関連技術
図1は自己紹介などでよく出てくる手話文章の動画例と,手話関連技術の関係を示しています.
なお,高山は手話自体は初学者で,ここでの手話表現は技術説明のために見様見真似で行っていることをご了承ください.
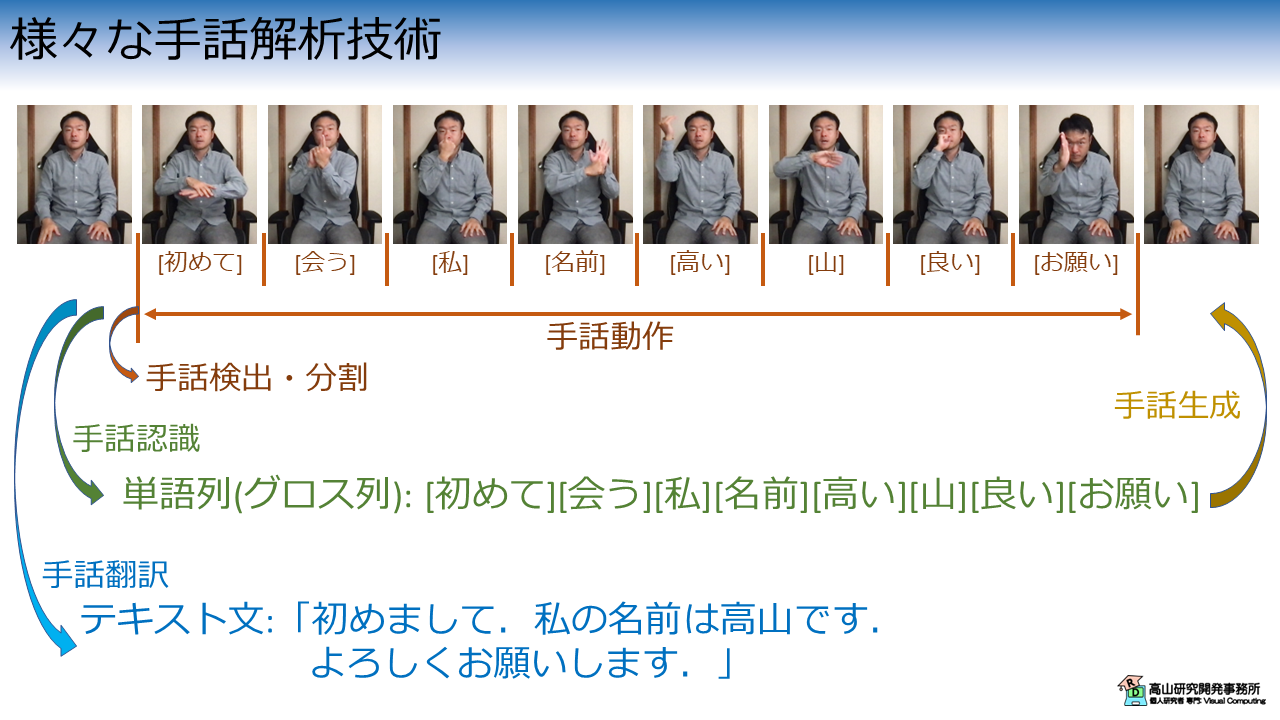
第1節では,図1に示す代表的な4種類の手話関連技術を説明します.
- 手話検出・分割 (Sign Language Detection/Segmentation)
- 手話認識 (Sign Language Recognition)
- 手話翻訳 (Sign Language Translation)
- 手話生成 (Sign Language Production/Generation)
1.1 手話検出・分割
手話検出や手話分割では手話動画を入力して,手話動作の時間範囲 (開始:M秒目,終了:N秒目など) を出力します [Moryossef'20, Renz'21].
例えば図1では,ホームポジション - 単語[初めて] 間の腕上げ動作を手話動作開始とし,単語[お願い] - ホームポジション間の腕下げ動作を手話動作終了として動作区間を検出し,動作中の時間範囲を出力します.
手法によっては,より細かく1文ごと ([初めて][会う],[私]...[山],[良い][お願い]のように区切る),または単語ごと ([初めて],[会う],[私],... ,[お願い]のように区切る) の時間範囲を出力する場合もあります.
これらの手法は,データセット作成の際のアノテーション補助ツールや,リアルタイムシステムのための前処理として利用することが可能です.
傾向としては,手話動作全体の時間範囲を出力する手法を手話検出,細かく単語ごとの時間範囲を出力する場合を手話分割と呼ぶ感じがありますが,定まった定義があるわけではありません.
- [Moryossef'20]: A. Moryossef, et al., "Real-Time Sign Language Detection using Human Pose Estimation," Proc. of the SLRTP, available here, 2020.
- [Renz'21]: K. Renz, et al., "Sign Language Segmentation with Temporal Convolutional Networks," Proc. of the ICASSP, available here, 2021.
1.2 手話認識
手話認識は手話動画を入力して,単語列を出力します [Koller'19, Zhou'20].
例えば図1では,「初めまして.」という手話表現から単語[初めて][会う]という2個の単語列を出力します.
手話認識では大きく分けて,1回の認識で1単語だけ認識する孤立手話単語認識と,図1に示すように1回の認識で文章を構成する複数単語を認識する連続手話単語認識が提案されています.
孤立手話単語認識は,手話検索や手話学習者向けアプリケーションの内部機能として利用が可能です.
また,連続手話単語認識は次項で説明する手話翻訳の前処理として用いることができます.
なお,図1で言っている単語列は,論文などではグロス列と表記されることが多いです [Foster'10].
グロスは形態素と呼ぶ,単語よりも少し細かな括りで割り振るラベルなので正確では無いのですが,言語学の細かな説明が必要になってしまうので (というよりも高山にはできないので(^^;)),ここではイメージがつきやすそうな単語列という表記を用いています.
また,現在発表されている手法,データセットが正確な意味で形態素やグロス [竹村'02] という単位で認識できるようなものかは少し疑問です (個人的意見です).
- [Koller'19]: O. Koller, et al., "Weakly Supervised Learning with Multi-Stream CNN-LSTM-HMMs to Discover Sequential Parallelism in Sign Language Videos," IEEE Trans. PAMI, Vol.42, Issue 9, available here, 2019.
- [Zhou'20]: H. Zhou, et al., "Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition," Proc. of the AAAI, available here, 2020.
- [Foster'10]: J. Foster, et al., "Best Practice for Sign Language Data Collections Regarding the Needs of Data-Driven Recognition and Translation," Proc. of the 4th LREC Workshop on the Representation and Processing of Sign Languages, available here, 2010.
- [竹村'02]: 竹村茂,"手話言語の形態論," 日本大学大学院総合社会情報研究科紀要,No.3, pp.252-260, available here, 2002.
1.3 手話翻訳
手話翻訳は近年の手話関連技術のホットトピックの一つです [Camgoz'18, Camgoz'20].
例えば図1では,手話認識とは違って「初めまして.」という翻訳テキストを出力します.
手法としては,手話動画から直接翻訳テキストを出す手法 (Sign to Text) や 手話動画 -> グロス列 -> 翻訳テキストというステップで出す手法 (Sign to Gloss to Text) などが提案されています [Camgoz'18, Camgoz'20, Coster'23].
手話翻訳は,音声認識サービスでよくあるバーチャルアシスタント (例えばSiriやAlexa) やチャットボット,コミュニケーション補助ツールなどにおける利用が想定されています.
手話翻訳の本格的な研究は未だ始まったばかりです.
2018年になってようやく,機械学習に耐えうる規模 (と言ってもかなり小規模ですが) の手話言語 - 音声言語対訳データセットが発表 [Camgoz'18] されたことによって,研究開発が可能になりました.
ただし,このデータセットはドイツの天気予報の通訳映像を用いており,手話言語の文法的特性が網羅されているわけではありません.
各研究開発者の努力の甲斐もあり,手話認識,手話翻訳ともに性能は年々向上しています.
しかしながら,実際のアプリケーションに結びつけるためには,現状の研究アプローチでは限界があることが指摘されており,学際的,国際的な取り組みの必要性が叫ばれています [Coster'23, Marcos'23, Bragg'19, Meulder'21].
- [Camgoz'18]: N. C. Camgoz, et al., "Neural Sign Language Transition," Proc. of the IEEE CVPR, available here, 2018.
- [Camgoz'20]: N. C. Camgoz, et al., "Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation," Proc. of the IEEE CVPR, available here, 2020.
- [Coster'23]: M. D. Coster et al., "Machine Translation from Signed to Spoken Languages: State of the Art and Challenges," Univ. Access Inf. Soc., available here, 2023.
- [Marcos'23]: A. N.-Marcos, et al., "A survey of Sign Language Machine Translation," Expert System with Applications, available here, 2023.
- [Bragg'19]: D. Bragg et al., "Sign Language Recognition, Generation, and Translation: An Interdisciplinary Perspective," Proc. of the ASSETS 19, pp.16-31, available here, 2019.
- [Meulder'21]: M. D. Meulder, "Is "Good Enough" Good Enough? Ethical and Responsible Development of Sign Language Technologies," Proc. of the 1st International Workshop on AT4SSL, pp.12-22, available here, 2021.
1.4 手話生成
手話生成は手話認識や手話翻訳とは逆に,単語列やテキスト文を入力して手話動画を出力します [Efthimiou'12, Stoll'20].
図1では生の手話動画が出力されるような画像になってしまっていますが,実際には Computer Graphics (CG) 画像を生成します.
手話言語を母語とされている方は,第2言語である日本語の文章などよりも手話映像の方が理解しやすいです [Rastgoo'21].
そのため,手話生成は音声ガイドのような情報保障アプリケーションにおける利用が想定されています.
有名な利用例としては,NHKの手話CGが挙げられます [NHK'23].
NHKは以前から力を入れて手話生成に取り組んでおり,東京パラリンピックの際に映像を見た方もいらっしゃるかと思います.
なお,手話生成は実際には音声言語から手話言語への翻訳なので,これも "手話翻訳: SLT" と表記すべきでは?,という意見も出ています [Marcos'23].
高山個人は,(少なくとも現状では) 両者で用いられている技術がかなり異なるので,同じにするのは混乱の元だと思っています.
翻訳と表記するのであれば,"音声手話言語翻訳: Speech to Sign Language Translation," "手話音声言語翻訳: Sign to Speech Language Translation" などのように違いが分かるように記述した方が良いという意見です.
- [Efthimiou'12]: E. Efthimiou, et al., "The Dicta-Sign Wiki: Enabling Web Communication for the Deaf," Proc. of the ICCHP, 2012.
- [Stoll'20]: S. Stoll, et al., "Text2Sign: Towards Sign Language Production Using Neural Machine Translation and Generative Adversarial Networks," Int. J. Comp. Vis, available here, 2020.
- [Rastgoo'21]: R. Rastgoo, at al., "Sign Language Production: A Review," Proc. of the IEEE CVPR, available here, 2021.
- [NHK'23]: NHK, "天災・防災 手話CG," available here, 2023.
- [Marcos'23]: A. N.-Marcos, et al., "A survey of Sign Language Machine Translation," Expert System with Applications, available here, 2023.
2. 認識・翻訳系の手話関連技術
第2節では,認識・翻訳系の手話関連技術についてもう少し細かく説明したいと思います.
認識系の手話関連技術としては,指文字認識,(孤立/連続) 手話単語認識,手話翻訳がよく知られています.
この中で指文字は,音声言語 (日本の場合は日本語) の身体的表現と呼べるもので少し特殊な立ち位置です.
本節では指文字認識と手話認識・手話翻訳で項を分けて,それぞれ説明したいと思います.
2.1 指文字認識
先に述べたように,指文字は手話言語の中では特殊な立ち位置です.
入力が身体的表現であるだけで,処理対象はあくまで音声言語であると言えます.
その分指文字認識は:
- 手話初学者でも理解しやすい
- データセットが作成しやすい
- 既存研究との対応関係が分かりやすく手法が流用しやすい
という特徴があります.
手話関連技術の中では比較的参入障壁が低く現在でも研究開発が行われています [Pugeault'11, Shi'19].
図2に示すように,指文字認識では:
- (a) 画像から1文字を認識する手法
- (b) 動画から1文字を認識する手法
- (c) 動画から文字列を認識する手法 (連続指文字認識)
というタスクが考えられます.
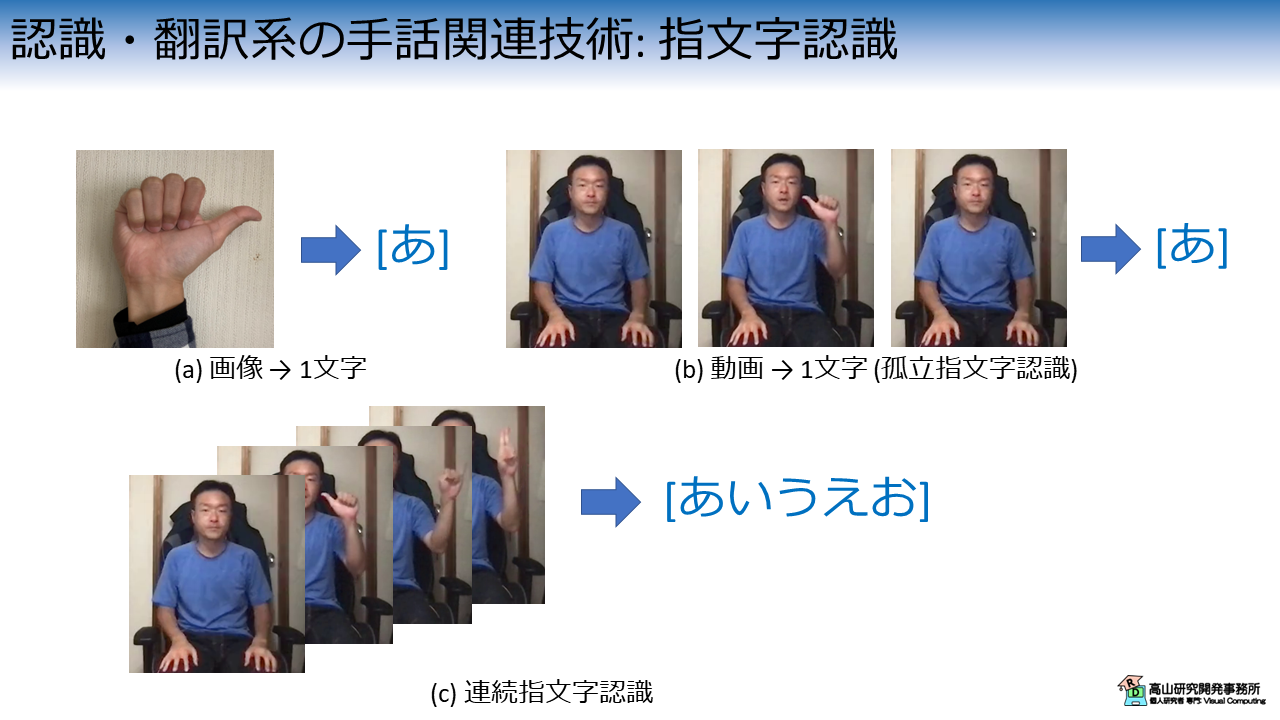
それぞれのタスクは,(a) 画像認識,(b) 動作認識 (c) 動作認識・音声認識 と類似の問題設定になっており,既存手法を流用して解くことが可能です.
先日行われたKaggleのコンペティションは (c) の連続指文字認識タスクで,優勝者は音声認識の技術・知見を利用していました.
- [Pugeault'11]: N. Pugeault, et al., "Spelling it out: Real-time ASL Fingerspelling Recognition," Proc. of the ICCV Workshop, available here, 2011.
- [Shi'19]: B. Shi, et al., "Fingerspelling Recognition in the Wild with Iterative Visual Attention," Proc. of the ICCV, available here, 2019.
2.2 手話認識・手話翻訳
図3に示すように,手話認識・手話翻訳では:
- (a) 孤立手話単語認識
- (b) 連続手話単語認識
- (c) 手話翻訳
というタスクが取り組まれています.

孤立手話単語認識は,手話動画を入力して1単語を認識します.ここで,動作は1単語 (のみ) を表していることが前提になっています [Dongxu'20, Jiang'21].
孤立手話単語認識は,図2(b) の動画から1文字を認識する指文字認識と同様に,一般的な動作認識とほぼ同じ問題設定になっています.
そのため,動作認識の手法がそのまま流用できるという特徴があります.
連続手話単語認識 [Koller'19, Zhou'20] と手話翻訳 [Camgoz'18, Camgoz'20] は,図1で示した例のように手話文を表現した動画を入力して,それぞれ単語列 (グロス列) と音声言語の翻訳テキストを出力します.
連続手話単語認識は,一見すると音声認識と類似の問題設定に見えます.
実際のところ,現在発表されているデータセットに対してはその考えである程度まで行けます.
しかしながら,より自然な手話言語の表現は必ずしも単語列で表せるとは限らないので,現在のアプローチがどこまで通用するのかは未知数です.
手話翻訳はそのまま流用できるような既存の問題設定を見つけるのは難しいですが,音声認識,動作認識,および自然言語処理などの技術・知見を組み合わせたアプローチがよく用いられます.
動画から直接翻訳テキストを出力するため,連続単語認識の問題を回避できそうに思えるのですが,制約が少ない分安定した学習・処理が課題になっています.
- [Dongxu'20]: L. Dongxu, et al., "Word-level Deep Sign Language Recognition from Video: A New Large-scale Dataset and Methods Comparison," Proc. of the WACV, available here, 2020.
- [Jiang'21]: S. Jiang, et al., "Skeleton Aware Multi-modal Sign Language Recognition," Proc. of the IEEE CVPR Workshop, available here, 2021.
- [Koller'19]: O. Koller, et al., "Weakly Supervised Learning with Multi-Stream CNN-LSTM-HMMs to Discover Sequential Parallelism in Sign Language Videos," IEEE Trans. PAMI, Vol.42, Issue 9, available here, 2019.
- [Zhou'20]: H. Zhou, et al., "Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition," Proc. of the AAAI, available here, 2020.
- [Camgoz'18]: N. C. Camgoz, et al., "Neural Sign Language Transition," Proc. of the IEEE CVPR, available here, 2018.
- [Camgoz'20]: N. C. Camgoz, et al., "Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation," Proc. of the IEEE CVPR, available here, 2020.
今回は手話関連の技術についての概要を紹介しましたが,如何でしたでしょうか?
手話関連の研究開発は,画像処理,CG,機械学習,ヒューマンインタフェースなど様々な技術が関係します.
また,言語学,福祉学,教育学,歴史学なども絡む学際的な分野でもあります.
幅広い知識・技術が必要とされますが,その分研究開発のネタが尽きない非常に面白くやりがいのある分野だと思います.
今回紹介した話が,これから手話関連の研究開発を始める方に,何かご参考になれば幸いです.



