
こんにちは.高山です.
今回から複数回に分けて,「手話認識入門」と題した連載記事を発表していきます.
連載記事の中では手話認識モデルの実装方法を紹介していきたいと思います.
手話認識の研究は小規模ながら,いくつかの研究グループで継続的に行われており,新しい技術が毎年発表されています.
一方,まとまった専門書や教科書が乏しいため,新規で研究を始める方や一般のエンジニアにはとっつきにくい分野になっていると感じていました.
手話認識を始める足がかりとなるようなチュートリアルがあれば良いのになぁと思ったことが,本連載記事の執筆を決めたきっかけです.
今回は,本連載記事の内容について大まかに紹介したいと思います.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タイトル,タグ,序文を更新しました
1. 本連載記事の概要
本連載記事では,近年のトレンドである深層学習ベースの手話認識にターゲットを絞って紹介していきます.
まず,本連載記事で取り扱う内容が実際のシステム開発などではどのような工程にあたるのかを説明します.
図1は,機械学習モデルを構築して,システムに組み込む際の基本的な工程を示しています.
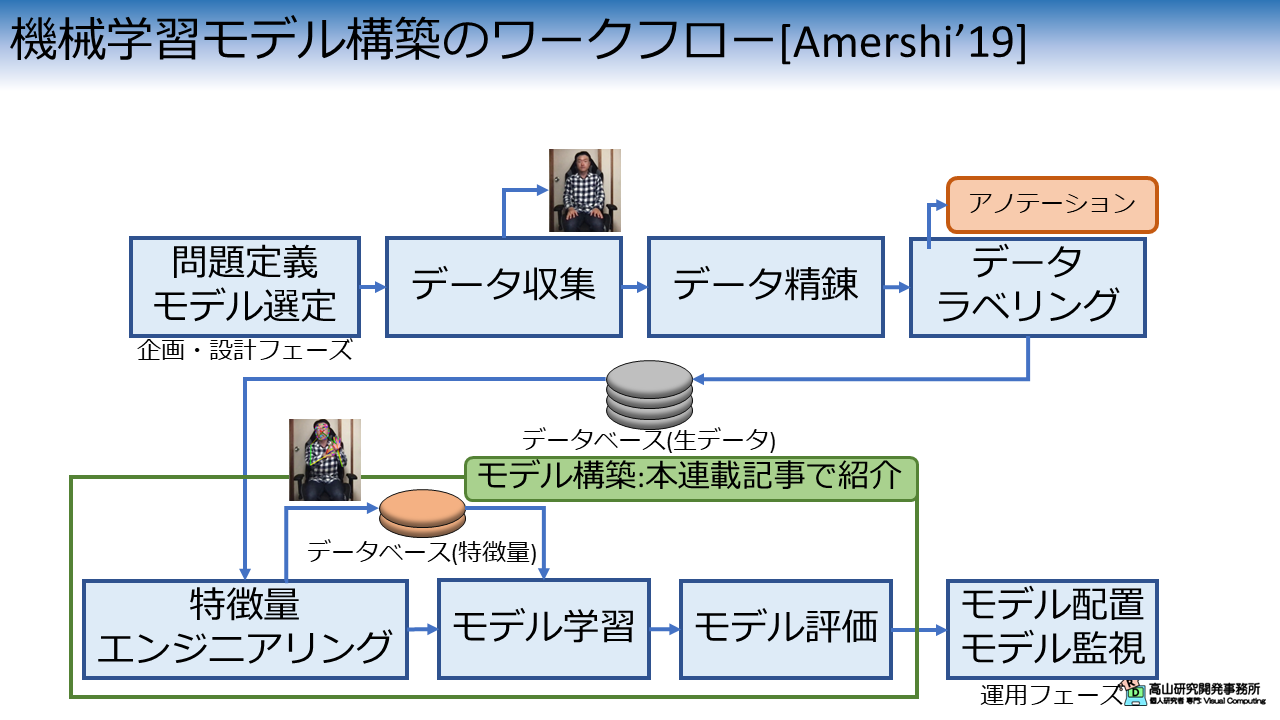
機械学習モデルを含むシステムを作る際はまず,企画・設計フェーズでシステムのどの処理を機械学習モデルに解かせるかを決めます.
その後,どのようなモデルでその問題を解くかを検討します.
図1に示すように本連載記事では,モデル構築を主に取り扱いますのでこの工程は省略しますが,実際のシステム開発においては重要な工程です.
例えば,手話検索システムを作る際は孤立手話単語認識モデルを利用することを思い浮かべますが,入力が画像の場合は通常の画像認識モデルを手話画像へ応用する方が適切かもしれません.
問題設定とモデル選定が終わったら,モデルを学習するためのデータベースの作成を行います.
この工程はかなり労働集約的で,本連載記事の中で作成するのは難しいです.
(作り方自体の紹介はいずれするかもしれません)
そこで本連載記事では,先日の記事で紹介した,KaggleのGoogle Isolated Sign Language Recognition (以下,GISLR) のデータセット (を加工したもの) を用います.
特徴量エンジニアリングの工程では生データを実際の学習に使うデータに変換し,モデルの学習と評価を行います.
本連載記事ではこれらの工程にで扱われる技術について主に紹介します.
なお,実際の業務では学習後のモデルをシステム内に配置し,それらの性能を実システムを通して監視するという工程があります.
本連載記事ではこの工程は扱いませんが (いずれ執筆したいとは思っています),実際のシステム開発では全体工程を意識して問題やモデルの検討を行うことが重要です.
- [Amershi'19]: S. Amershi, et al., "Software Engineering for Machine Learning: A Case Study," IEEE/ACM ICSE-SEIP 2019.
2. 本連載記事の構成
本連載記事の構成を下記に記します.
実装にはPyTorchを用います.
今後記事をアップする毎にリンクを追加していく予定です.
- データベースの操作方法 (リンク)
- シンプルな孤立手話単語認識モデル (リンク)
- 特徴量エンジニアリング1 - 追跡点の選定 (リンク)
- 特徴量エンジニアリング2 - 追跡点の正規化 (リンク)
- RNNを用いた孤立手話単語認識モデル1 - レイヤ構成の設計 (リンク)
- RNNを用いた孤立手話単語認識モデル2 - Padding信号のマスキング (リンク)
- RNNを用いた孤立手話単語認識モデル3 - レイヤ種別の選択 (リンク)
- シンプルなAttention層の適用 (リンク)
- Transformerを用いた孤立手話単語認識モデル (リンク)
- 様々な改善手法1 - ラベルスムージングによる正則化 (リンク)
- 様々な改善手法2 - 追跡点の左右入れ替えによるデータ拡張 (リンク)
- 様々な改善手法3 - 時系列クリッピングによるデータ拡張 (リンク)
- 様々な改善手法4 - 時系列ワーピングによるデータ拡張 (リンク)
- 様々な改善手法5 - アフィン変換によるデータ拡張 (リンク)
- 様々な改善手法6 - ノイズ付加によるデータ拡張 (リンク)
- 様々な改善手法7 - 追跡点のマスキングによるデータ拡張 (リンク)
- 様々な改善手法8 - 時系列リサイジングによる処理軽量化 (リンク)
- 補足1: Google Driveのマウント (リンク)
- 補足2: 深掘りRNN1: SRNNからLSTMとGRUへの変遷 (リンク)
- 補足3: 深掘りRNN2: LSTMとGRUの動作について (リンク)
- 補足4: 深掘りRNN3: PyTorchのRNNクラスの出力について (リンク)
- 補足5: 深掘りTransformer1: Positional encoding の処理について (リンク)
- 補足6: 深掘りTransformer2: Multi-head self-attention の処理について (リンク)
- 補足7: 深掘りTransformer3: 正規化層について (リンク)
- 補足8: 深掘りTransformer4: 欠損値の補間は認識性能を向上させるのか? (リンク)
- 補足9: 実験用GISLRデータセットの作成方法 (リンク)
- 補足10: 深掘りTransformer5: GISLRタスクに合う正規化層は何か? (リンク)
今回は手話認識のチュートリアル記事について,簡単に概要を紹介させていただきましたが,如何でしたでしょうか?
目次を並べてみると,思ったよりも盛り沢山の内容になってしまいました(^^;).
なるべく早く公開できるように頑張りたいと思います.
今回紹介した話が,これから手話認識を勉強してみようとお考えの方に何か参考になれば幸いです.





