目次
こんにちは.高山です.
今回は,第七回の記事の補足になります.
手話入門記事の第七回ではRNNタイプのレイヤとして,SRNNを改良した long short term memory (LSTM) と gated recurrent unit (GRU) を紹介しました.
このときの記事では実装を中心として説明し,LSTMとGRUについては細かく説明していませんでしたので,本記事で補足説明をさせていただきたいと思います.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
1. LSTMとGRU
図1は第七回の記事で紹介した,LSTMとGRUの処理構成図です.

LSTMはオリジナル[Hochreiter'97]から段階的に改善[Gers'00, Gers'03, Sak'14]されていっているので少しややこしいですが,PyTorchの実装は文献[Gers'00]をベースに,文献[Sak'14]の機構の一部を (オプション的に) 取り入れた形になってます.
文献[Gers'03]で提案された Peephole connection という機構の導入は古くから検討されていますが,未だ実現していないようです.
図1(a), (b) は,それぞれ文献[Sers'00]と[Cho'14]に基づいています.
LSTMやGRUは複雑な構造をしていますので,いきなり特性を紹介しても理解しづらいと思います.
次節では,SRNNからLSTM,GPUへの変遷を追っていきながら,アーキテクチャの設計意図などを説明していきます.
- [Hochreiter'97]: S. Hochreiter, "Long Short-term Memory," Neural Computation, Vol.9, No.8, pp.1735-80, available here, 1997.
- [Gers'00]: F. A. Gers, et al., "Learning to forget: continual prediction with LSTM," Neural Computation, Vol.12, No.10, pp.2451-2471, available here, 2000.
- [Gers'03]: F. A. Gers, et al., "Learning precise timing with LSTM recurrent network," Journal of Machine Learning Research, Vol.3, pp.115-143, available here, 2003.
- [Sak'14]: H. Sak, et al., "Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition," arXiv:1402.1128, available here, 2014.
- [Cho'14]: K. Cho, et al., "Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation," Proc. of the EMNLP, available here, 2014.
2. SRNNの問題点
図2はSRNNを時間方向に展開した様子を表しています.
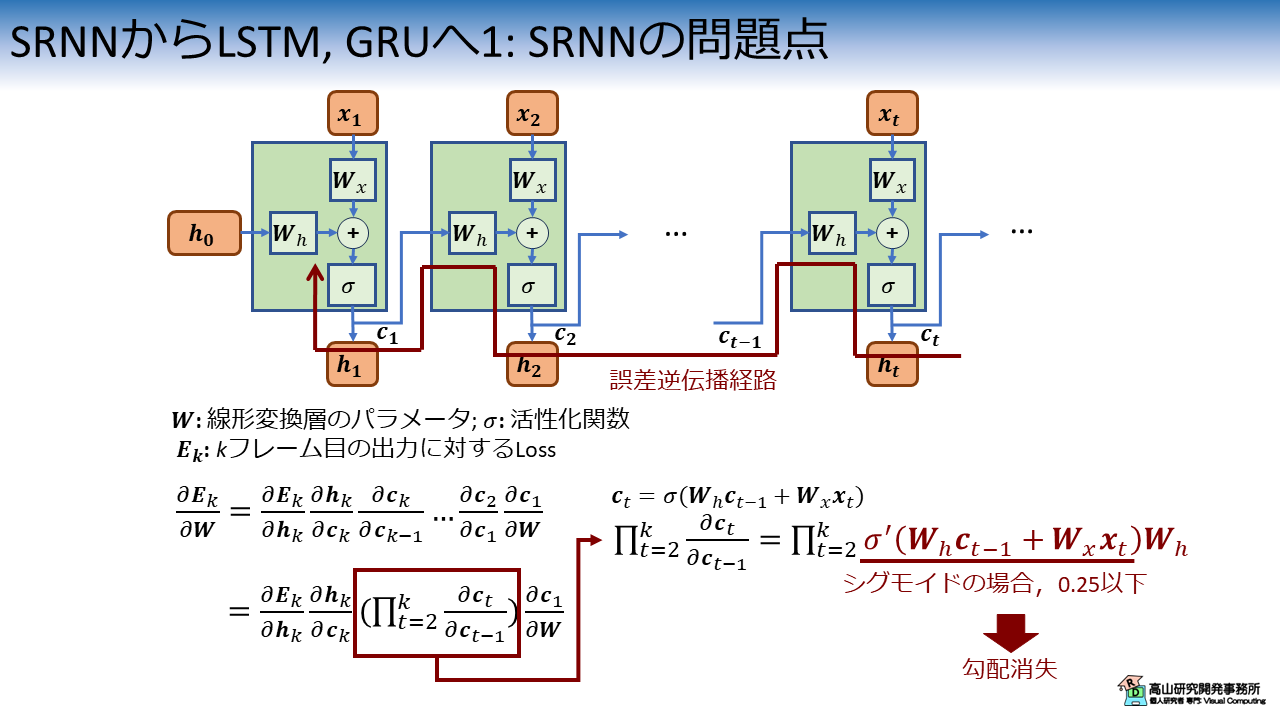
ここで,\(\boldsymbol{W} = [\boldsymbol{W}_h, \boldsymbol{W}_x]\) はSRNN内の線形変換層のパラメータを示し (\([\cdot, \cdot]\) は特徴次元方向の結合),\(\sigma\) は活性化関数を示します.
SRNNにはセル状態 \(\boldsymbol{c}_t\) はありませんが,後のLSTMとの対応関係を分かりやすくするために,SRNN内部で受け渡す過去の情報を \(\boldsymbol{c}_t (=\boldsymbol{h}_t)\) で表記しています.
SRNNが \(k\) フレーム目に推測値 \(\boldsymbol{h}_k\) を出したとして,\(\boldsymbol{h}_k\) と正解を比較した際の Loss を \(\boldsymbol{E}_k\) で表します.
SRNNの学習では,図2の赤線に示すように時間軸に沿ってさかのぼるような経路でLossを伝播していき,パラメータを更新量 \(\frac{\partial \boldsymbol{E}_k}{\partial \boldsymbol{W}}\) を求めます (この値はGradient: 勾配と呼びます).
\(\frac{\partial \boldsymbol{E}_k}{\partial \boldsymbol{W}}\) は合成関数の微分表記 (覚えてますか? 私は完全に忘れてました(^^;)) を用いると図2の下側に示すような式に展開できます.
ここで問題になるのは図2の右下に示す,活性化関数の微分の直積部分です.
SRNNの学習では,入力系列の数だけ活性化関数の微分がかけ合わせられます.
そのため,\(\frac{\partial \boldsymbol{E}_k}{\partial \boldsymbol{W}}\) は活性化関数の微分がとる値域によって指数的に膨張 (\(\sigma ' > 1\)) または 消失 (\(\sigma ' < 1\)) します.
例えば,シグモイド関数を用いた場合は, \(\sigma ' <= 0.25\) なので勾配消失しやすくなり,学習が進まない,または学習時間が長くなる現象が起きやすくなります.
3. LSTMの発展
3.1 Constant Error Carouselの導入
SRNNの勾配爆発/消失問題を解決するために,文献[Hochreiter'97]では Constant Error Carousel (CEC) という機構が提案されました.
CECは,誤差逆伝播時に値を変化させずに時間をさかのぼるための仕組みで,図3に表すような機構になります.
(なお,文献[Hochreiter'97]では次項で説明するゲート機構も同時に提案されているので,図3のようなモデルが実際に提案されたわけではありません)
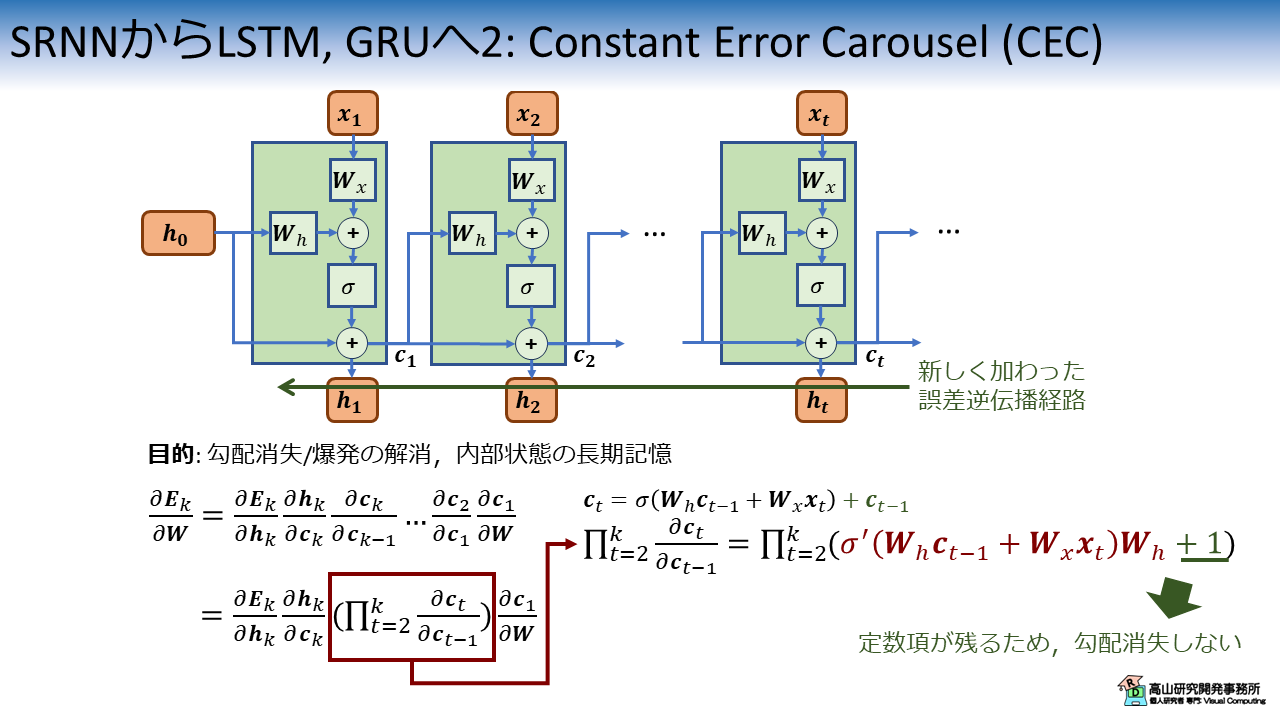
図2と違い,図3では現在の出力 \(\boldsymbol{c}_{t} (=\boldsymbol{h}_{t})\) を計算する際に,過去の情報 \(\boldsymbol{c}_{t-1} (=\boldsymbol{h}_{t-1})\) が足しあわされています.
数式で表すと下記のようになります.
(長くて一々書くのが面倒なので(^^;)) 活性化関数部分を \(\sigma (t)\) で置き換えて,展開すると下記のように表せます.
このように,CECによってLSTMでは過去の情報 (\(\sigma (t)\)) を長期間保持することが可能になっています.
また同時に,CECを導入すると図3の緑線で示す誤差逆伝播経路が加わります.
この経路を加味しすると,勾配 \(\frac{\partial \boldsymbol{E}_k}{\partial \boldsymbol{W}}\) とその展開式は図3の下部のように表せます.
このとき,図3右下に示すように直積部分には定数項が加わります.
そのため,勾配消失をせず学習をすることが可能になります.
3.2 Input/Output gateの導入
LSTMのコアとなるアイデアはCECですが,文献[Hochreiter'97]では,Input gate と Output gate という機構も同時に提案されています.
文献[Hochreiter'97]で提案されたオリジナルのLSTMを図4に示します.
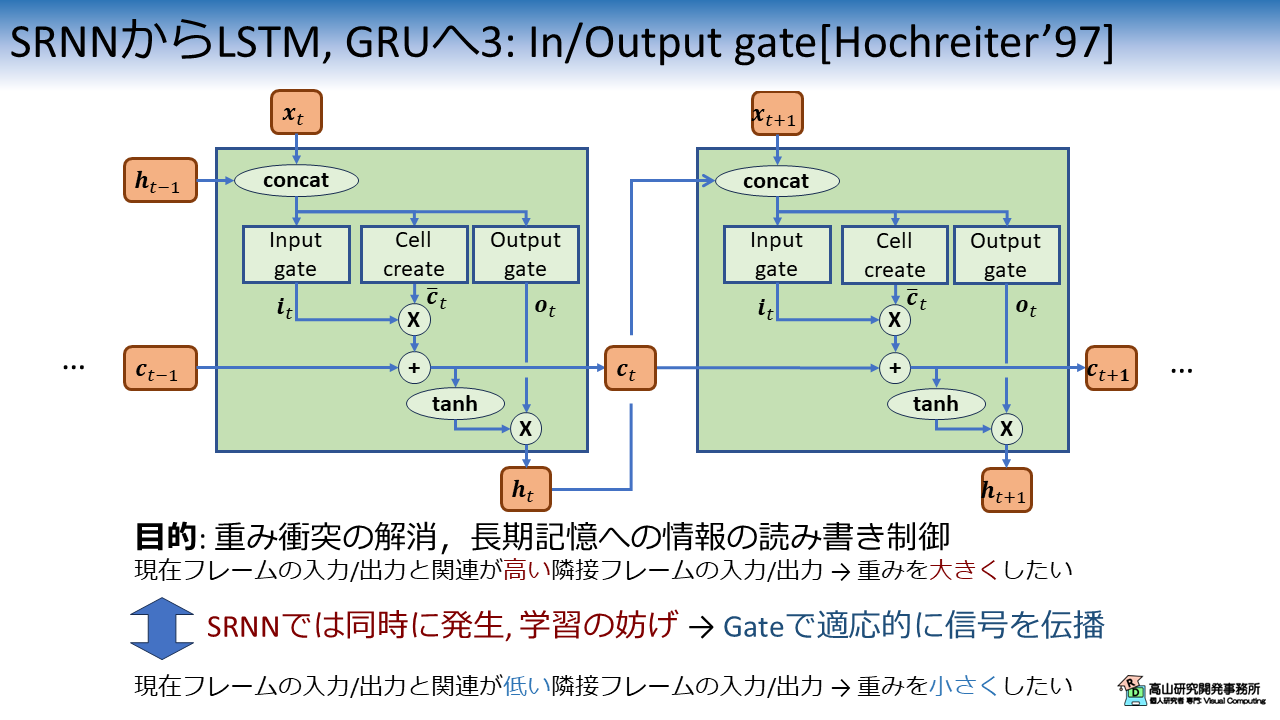
図1(a) に大分近づいてきましたね.
計算の中身については別記事で解説しますので,ここでは定性的な特徴について紹介したいと思います.
文献[Hochreiter'97]では,Input/Output gate は重み衝突という現象の解消を目的として導入されています.
例えば,現在フレームと関連が「高い」隣接フレームが入力または出力される場合,モデルは線形変換層の重みを大きくするように学習しようとするかもしれません.
一方,現在フレームと関連が「低い」隣接フレームが入力または出力される場合,モデルは線形変換層の重みを小さくするように学習しようとするかもしれません.
このような相反したパラメータ更新が,RNN型のモデルでは同時に起こるため学習が上手くいかない問題が発生します.
LSTMでは,Input/Output gate により各フレームの学習への影響を制御することで,重み衝突の問題を解消しています.
また,より見たままの解釈では,Input/Output gate は長期記憶 (セル) への情報の読み書き制御をしていると言えます.
最近では,後者の特徴を挙げられることはよく見られますが,重み衝突に言及することは少ない印象です.
3.3 Forget gateの導入
文献[Hochreiter'97]のLSTMで,長期記憶と勾配消失の問題は解消できました.
一方で,2.2項の式\(\eqref{equ:cell_cec_exp}\)に示したように,オリジナルのLSTMは過去の全情報を蓄積する特性があります.
この特性は,入力系列のパターンが途中から大きく変わった場合に推論を妨げる要因になるため改善が必要でした.
この問題に対処するために導入されたのが,図5に示す Forget gate です.
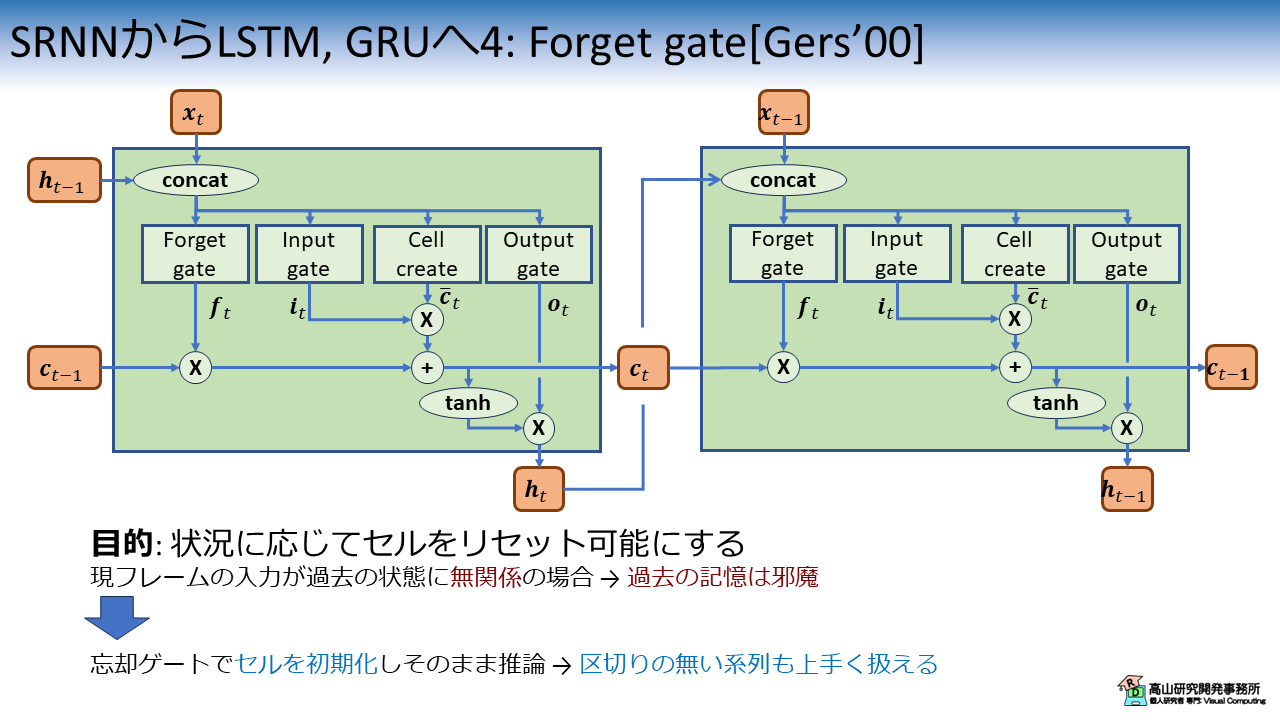
やっと図1(a) で示したLSTMになりました(^^).
Forget gate の役割は,\(\boldsymbol{f}_t \in [0, 1]\) によってセルをリセットすることにあります.
この機構により,区切りのない系列も上手く扱えるようになりました.
なお,今まで孤立手話単語認識の話しかしてこなかったので,"区切りのない系列","入力系列のパターンが途中から大きく変わる"というのはイメージしにくいかもしれません.
孤立手話単語認識で扱っていたデータは,予め動画が単語毎に区切られています.
これはLSTM側から見ると,外部から強制的に内部状態をリセット (または再起動) していることになります.
文献[Gers'00]では孤立手話単語認識とは異なり,複数の系列が一続き (各系列は互いに無関係) になって入力されるような状況を想定しています.
断続的に入力される波形やイベント信号を予測・検出するようなタスクではよくある状況かと思います.
手話動画の文脈で (頑張って) 考えるならば,
- カメラは起動しっぱなし
- 手話者がランダムに手話単語を表出する
- 表出の合間にカメラ前から立ち去ってまた戻ってくる
というような状況でしょうか? (もちろん,文献[Gers'00]では手話を扱ってはいないので,私の想像に過ぎませんが(^^;))
- [Gers'00]: F. A. Gers, et al., "Learning to forget: continual prediction with LSTM," Neural Computation, Vol.12, No.10, pp.2451-2471, available here, 2000.
3.4 Peephole connectionsの導入
2.4節までで,PyTorchに実装されているLSTMは紹介したのですが,折角ですので文献[Gers'03]で提案された Peephole connections についても紹介します.
Peephole connections を備えたLSTMを図6に示します.
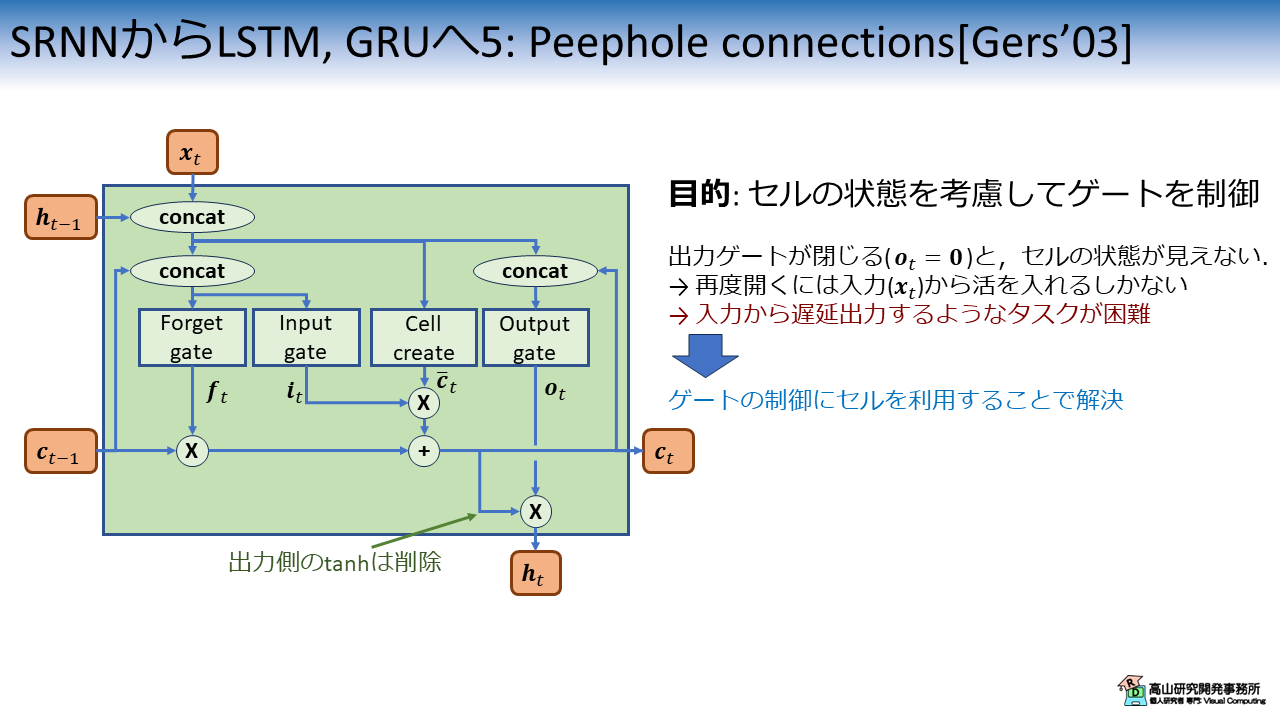
2.4節までに紹介したLSTMでは,各ゲートの制御にセルの状態は関わっていませんでした.
そのため,一旦 Output gate が閉じる (\(\boldsymbol{o}_t = \boldsymbol{0}\)) と内部状態はブラックボックスになってしまい,再度開くには入力側 (\(\boldsymbol{x}_t\)) から信号を入れる必要がありました.
これは入力から遅延出力するようなタスク (例えば,10と入力すると10フレーム語にパルスを出力する,この間入力は無いし,Output gate は閉じている) が困難であることを意味します.
このようなタスクは手話の文脈ではイメージしづらいですが,制御回路などでは一般的な状況かと思います.
図6に示すように,Peephole connections はセル状態がゲートの制御に関わるように経路を加えた機構です.
この機構により,入力が無くてもセルの内部状態からLSTMが自己判断をして Output gate を開くことが可能になり,上記のようなタスクを扱えるようになりました.
4. GRUの提案: アーキテクチャの簡略化
LSTMでは,時系列処理に対処するための様々な工夫が取り入れられ,目覚ましい成果を挙げたのですが,その分,次第にアーキテクチャが複雑になっていきました.
この問題を受けて,GRUはよりシンプルなアーキテクチャで,LSTMと同様の性能を維持することを目的として提案されました.
図1と同じく,図7にLSTMとGRUのアーキテクチャを比較した図を示します.
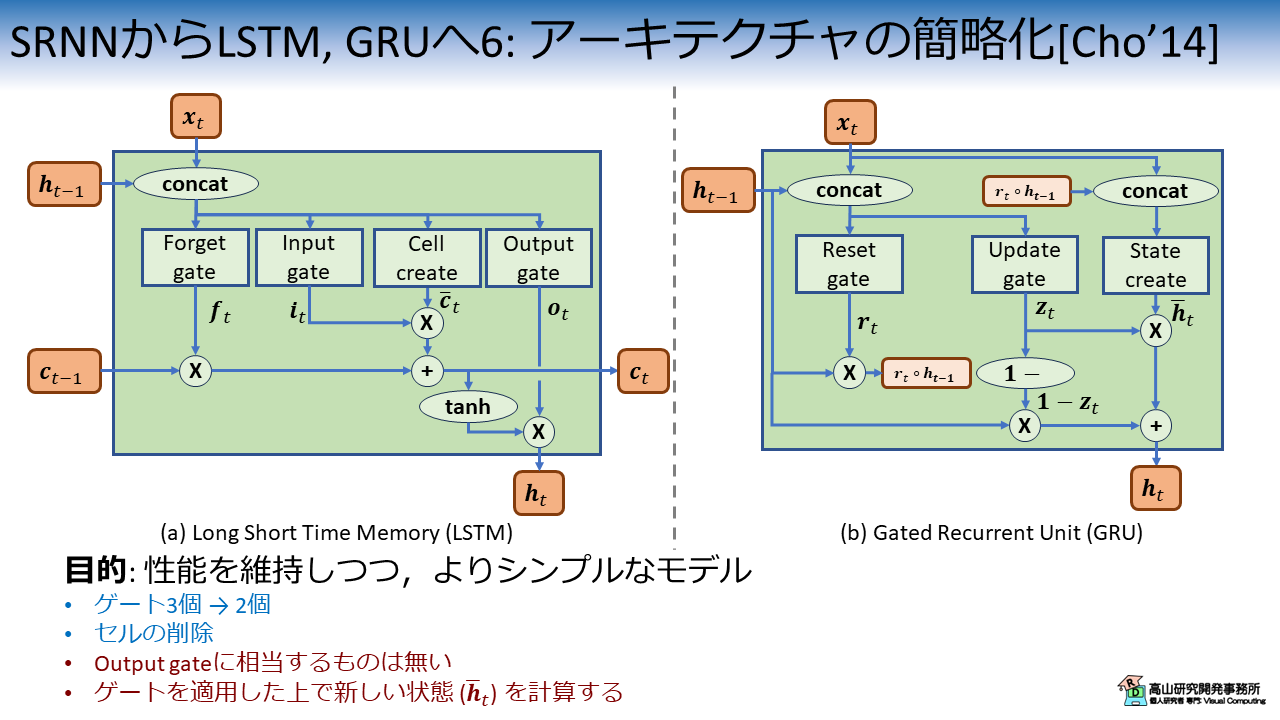
LSTMとGRUでは内部機構の組み方が異なるので,ブロック間にきれいな対応関係は無いのですが,下記のような違いが見出せます.
- GRUではゲートが3個から2個へと減っている.
- LSTMにおけるセル (\(\boldsymbol{c}_t\)) は削除.
- Output gate に相当するブロックはGRUには無い.
- LSTMでは,ゲートとは独立して新しい状態 (\(\bar{\boldsymbol{c}}_t\)) を計算しているのに対して,GRUでは,ゲートを適用した上で新しい状態 (\(\bar{\boldsymbol{h}}_t\)) を計算している.
より詳細な比較分析は,文献[Chung'14]に記載されています.
GRUは元々時系列認識タスクを対象にして提案されており,その性能は第七回の記事で確かめたとおりです.
(このときは,30単語のデータセットを用いた場合はGRUが最も良い性能でした)
一方,Output gate に相当するブロックが無いことから,LSTMでは対応できていた遅延出力などへのタスクは処理が難しいかもしれません.
(実験をしたわけではないので,ただの推測です(^^;))
- [Chung'14]: J. Chung, et al., "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling," arXiv.1412.3555, available here, 2014.
今回はSRNNからLSTM,GRUへのアーキテクチャの変遷を紹介しましたが,如何でしたでしょうか?
今までLSTMに関する一連の論文を集中的に読んだことは無かったので,非常に勉強になりました.
CECは,現在ではResidual connection と呼ばれる技術に相当するもので,90年代に既に提案されていたのはすごいですね.
最近は次から次へと新しいアーキテクチャが発表されて,追いかけるのも大変な状況ですが,ときには昔に提案された技術をじっくり理解してみるのも良いなと思いました.
今回紹介した話が,これから手話認識や深層学習を勉強してみようとお考えの方に何か参考になれば幸いです.