目次
こんにちは.高山です.
今回は前回に引き続き,第七回の記事の補足になります.
手話入門記事の第七回ではRNNタイプのレイヤとして,SRNNを改良した long short term memory (LSTM) と gated recurrent unit (GRU) を紹介しました.
また,前回の記事では,SRNNからLSTM,およびGRUへとアーキテクチャの変遷を追っていきながら,どのような意図で設計されているのかを解説しました.
本記事では,LSTMとGRUの内部動作について順を追って説明していきたいと思います.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
1. LSTMとGRU
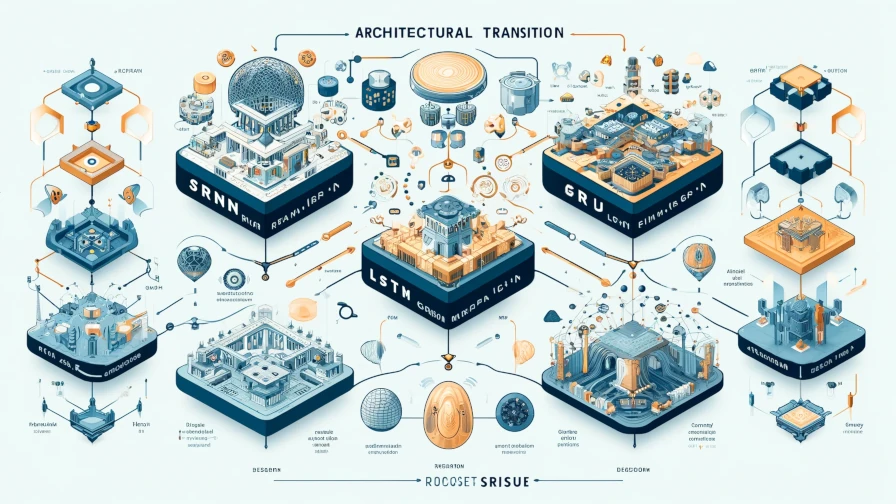
図1は第七回の記事で紹介した,LSTMとGRUの処理構成図です.

LSTMはオリジナル[Hochreiter'97]から段階的に改善[Gers'00, Gers'03, Sak'14]されていっているので少しややこしいですが,PyTorchの実装は文献[Gers'00]をベースに,文献[Sak'14]の機構の一部を (オプション的に) 取り入れた形になってます.
文献[Gers'03]で提案された Peephole connection という機構の導入は古くから検討されていますが,未だ実現していないようです.
図1(a), (b) は,それぞれ文献[Sers'00]と[Cho'14]に基づいています.
図1に示す通りLSTM,GRU共に,内部処理は線形変換と活性化関数を組み合わせた複数の処理ブロックと,行列演算の組み合わせから構成されています.
次節以降では,各処理を Step by step で説明していきます.
- [Hochreiter'97]: S. Hochreiter, "Long Short-term Memory," Neural Computation, Vol.9, No.8, pp.1735-80, available here, 1997.
- [Gers'00]: F. A. Gers, et al., "Learning to forget: continual prediction with LSTM," Neural Computation, Vol.12, No.10, pp.2451-2471, available here, 2000.
- [Gers'03]: F. A. Gers, et al., "Learning precise timing with LSTM recurrent network," Journal of Machine Learning Research, Vol.3, pp.115-143, available here, 2003.
- [Sak'14]: H. Sak, et al., "Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition," arXiv:1402.1128, available here, 2014.
- [Cho'14]: K. Cho, et al., "Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation," Proc. of the EMNLP, available here, 2014.
2. LSTMの内部動作
2.1 セルベクトルの生成
本節ではLSTMの内部動作を説明します.
まず最初に,入力特徴量 \(\boldsymbol{x}_t\) と過去の出力特徴量 \(\boldsymbol{h}_{t-1}\) から次の内部状態の候補 \(\bar{\boldsymbol{c}}_t\) (Cell vector: セルベクトル) を生成します.
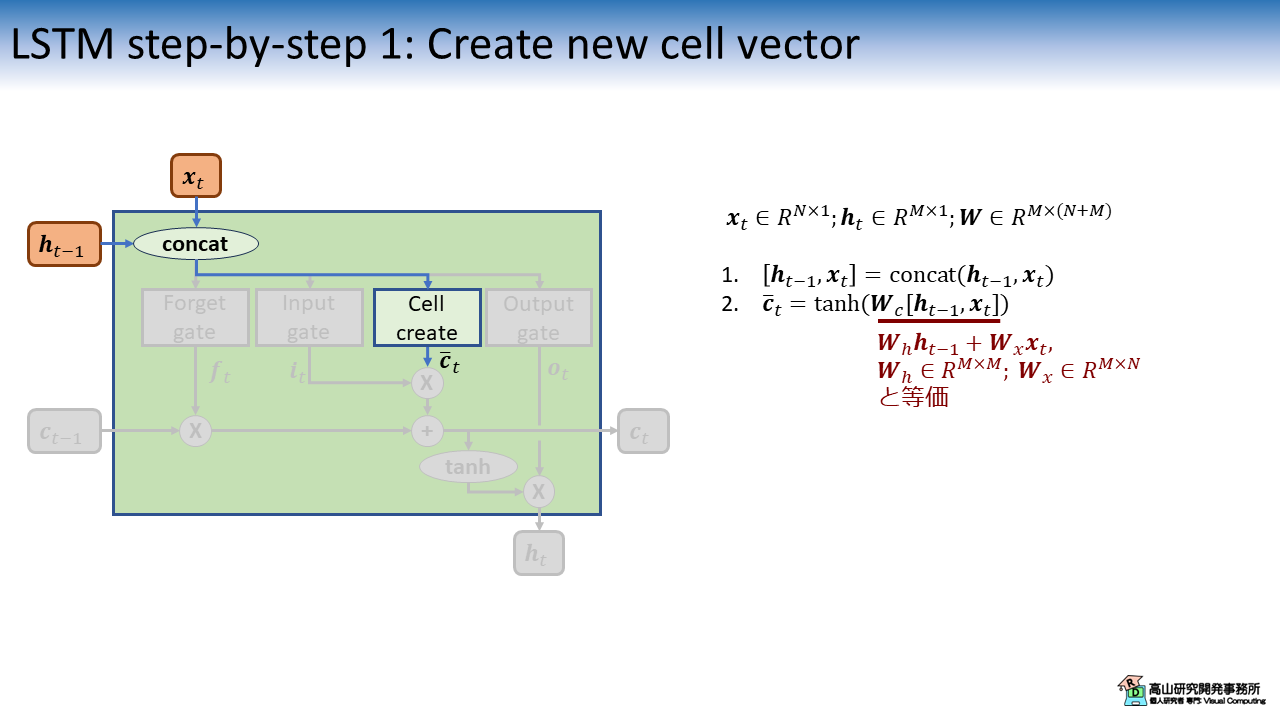
図2では,最初に \(\boldsymbol{x}_t \in R^{N \times 1}\) と \(\boldsymbol{h}_{t-1} \in R^{M \times 1}\) を結合して \(\boldsymbol{W}_c \in R^{M \times (N+M)}\) にかけるように表記しています.
これは図と数式をコンパクトにするための表記で,実際の実装が必ずしもこのようになっているわけではありません.
\(\boldsymbol{W}_h \in R^{M \times M}\) と \(\boldsymbol{W}_x \in R^{M \times N}\) を,それぞれ \(\boldsymbol{h}_{t-1}\) と\(\boldsymbol{x}_{t}\) にかけて足し合わせる処理と等価ですので,図2の赤字で示したような数式 (とそれに対応した図) で表記される場合もあります.
よく見ると,図2のセルベクトルの作成処理は,第五回の記事で紹介した (1.2項 図3(b) SRNNのブロック図を参照してください) SRNNの処理と同じです.
LSTMがSRNNをベースとして,機構を加えて改良していったことがよく分かると思います.
2.2 入力ゲートの適用
図3は,入力ゲート (Input gate) の計算を示しています.
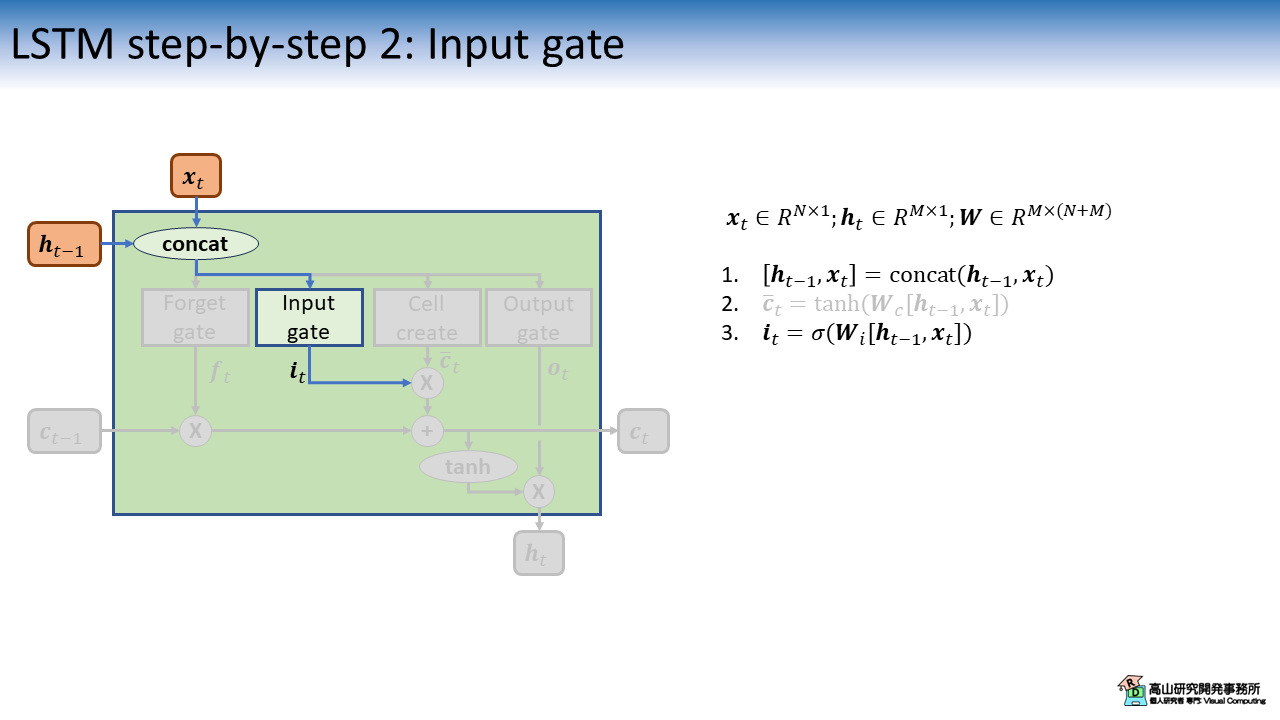
図中の \(\sigma(\cdot)\) はシグモイド関数を表し,\(\boldsymbol{i}_t\) は\([0, 1]\)の範囲の値を持ちます.
\(\boldsymbol{i}_t\) を他のベクトルに掛け合わせることで,そのベクトルを重み付け (抑制) することができます.
そのため,これらの処理をゲートと呼びます (という理由だと思います(^^;)).
2.3 忘却ゲートの適用
図4は,忘却ゲート (Forget gate) の計算を示しています.
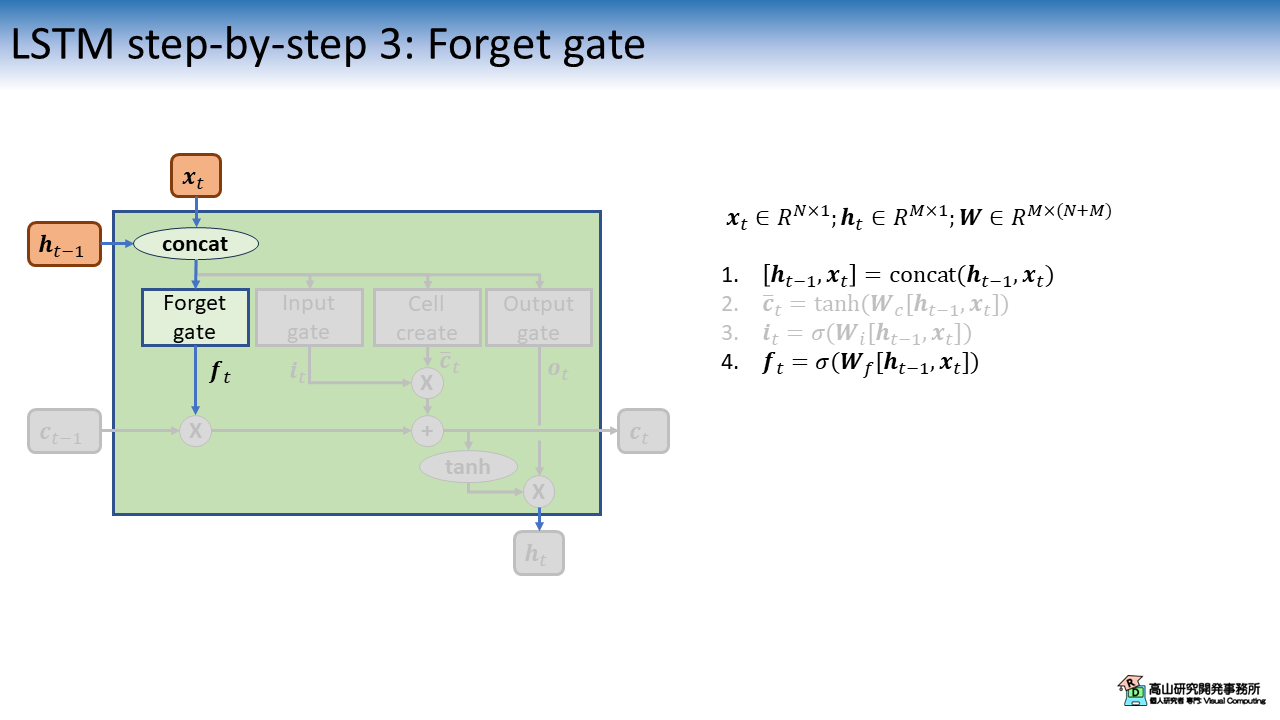
処理構成は Input gate と同じで,適用先が異なります.
2.4 セル状態の更新
図5はセル状態の更新処理を示します.
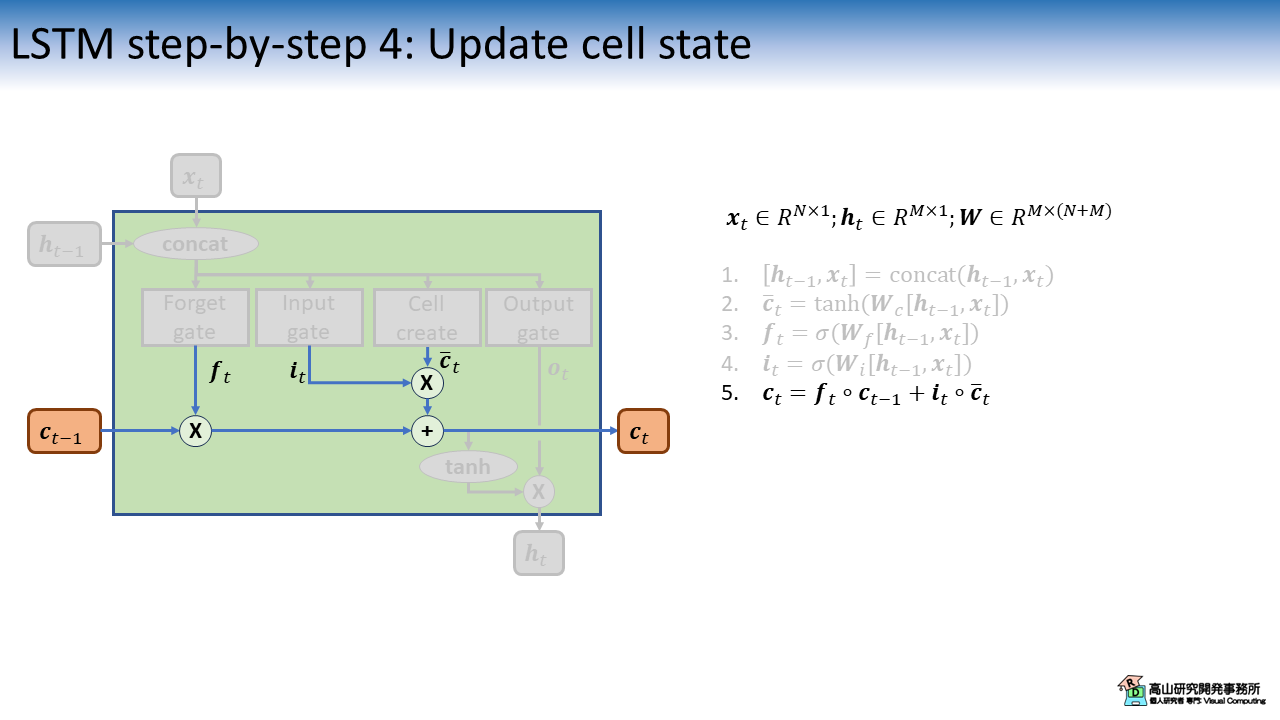
まず最初に,入力ゲートと忘却ゲートの計算結果 (\(\boldsymbol{i}_t, \boldsymbol{f}_t\)) を,それぞれセルベクトルと過去のセル状態 (\(\bar{\boldsymbol{c}}_t, \boldsymbol{c}_{t-1}\)) にかけます.
その後,ゲートを適用したセルベクトルと過去のセル状態を足しあわせることで,セル状態 \(\boldsymbol{c}_t\) を更新します.
ここの処理は,前回の記事で説明した (3.1項をご参照ください) Constant Error Carousel に相当します.
2.5 出力ゲートを適用し隠れ状態を更新
図6は 出力ゲート (Output gate) の計算と,その計算結果をセル状態 \(\boldsymbol{c}_t\) に適用して出力特徴量 (隠れ状態: \(\boldsymbol{h}_t\)) を更新する処理を示しています.
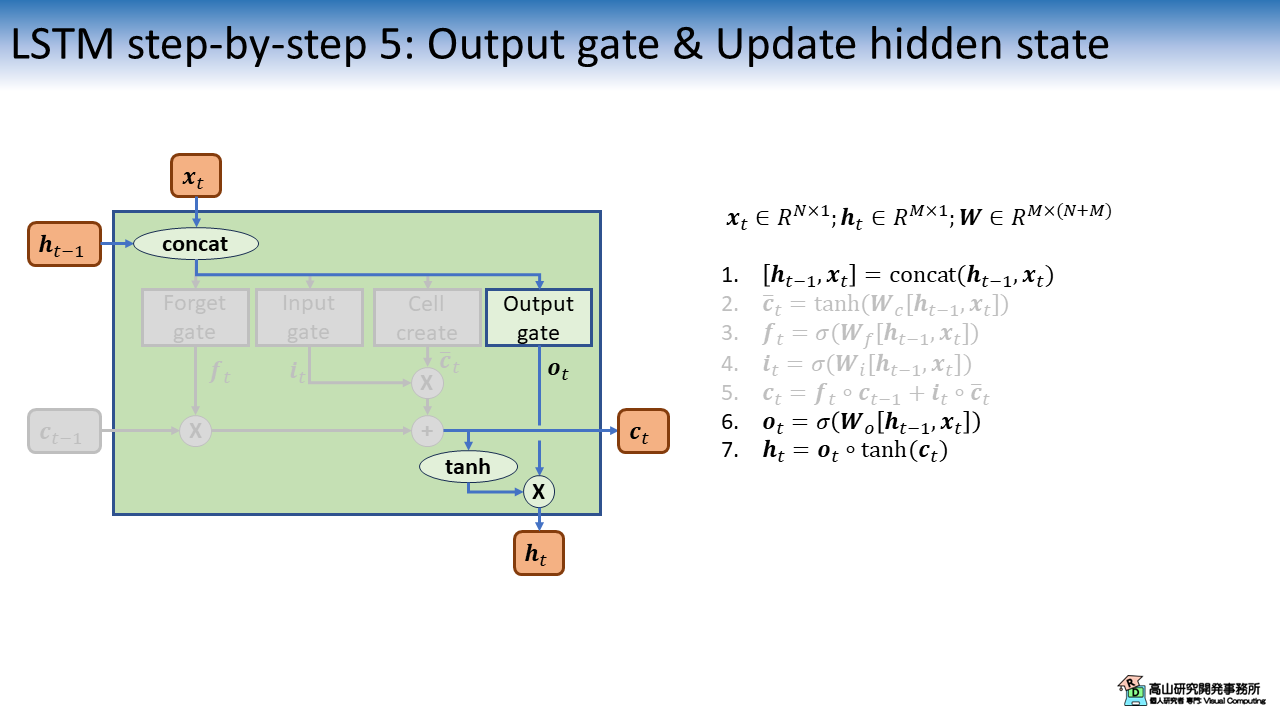
Output gate の処理構成は他のゲートと同様で,\(\boldsymbol{o}_t\) をセル状態に掛け合わせることで出力を重み付けします.
ハイパーボリックタンジェント (tanh) は,\(\boldsymbol{c}_t\) を[-1, 1]の範囲の値に変換するために適用しています.
ただし,この処理は性能への寄与が不明確なようで,後に改良された文献[Gers'03]のLSTMでは削除されています.
3. GRUの内部動作
3.1 初期化ゲートの適用
本節ではGRUの内部動作を説明します.
まず最初に,入力特徴量 \(\boldsymbol{x}_t\) と過去の出力特徴量 \(\boldsymbol{h}_{t-1}\) から初期化ゲート (Reset gate) の計算をします.
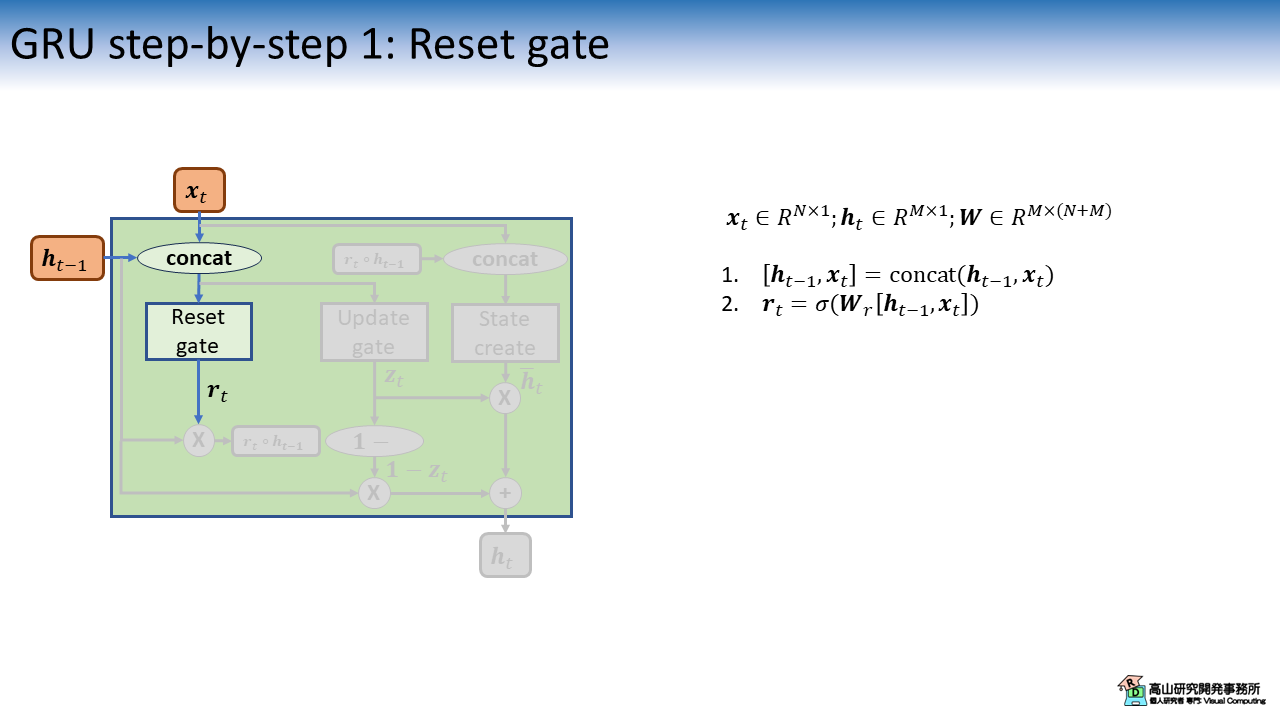
処理構成はLSTMの各ゲートと同様で,\(\boldsymbol{r}_t\) の値は\([0, 1]\)の範囲になります.
3.2 隠れベクトルの作成
次に,新しい出力特徴量の候補 \(\bar{\boldsymbol{h}}_t\) (Hidden vector: 隠れベクトル) を生成します.
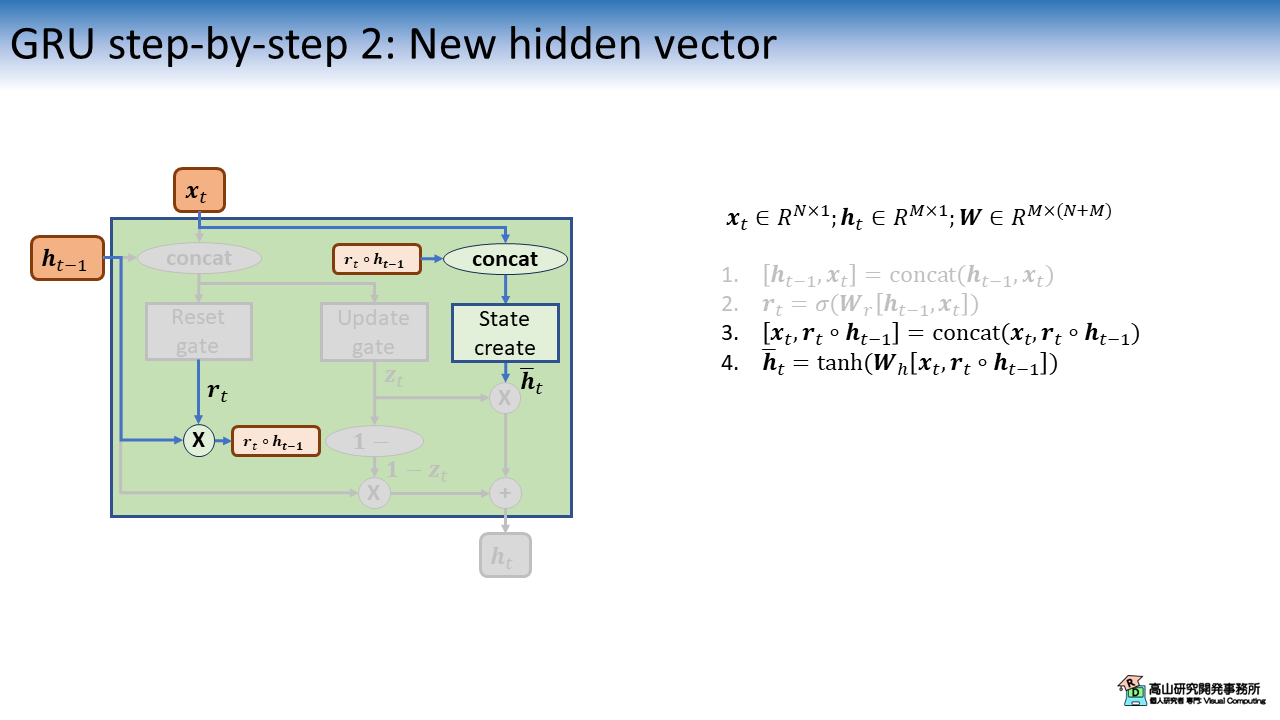
この処理は2.1項で紹介したセルベクトルの生成と似ていますが,Reset gate が先に過去の出力特徴量 \(\boldsymbol{h}_{t-1}\) に適用されている点が異なります.
3.3 更新ゲートの適用
図9は,更新ゲート (Update gate) の計算を示しています.

処理構成は Reset gate と同じで,適用先が異なります.
3.4 隠れ状態の更新
最後に,図10に示すように隠れ状態 \(\boldsymbol{h}_t\) を更新します.
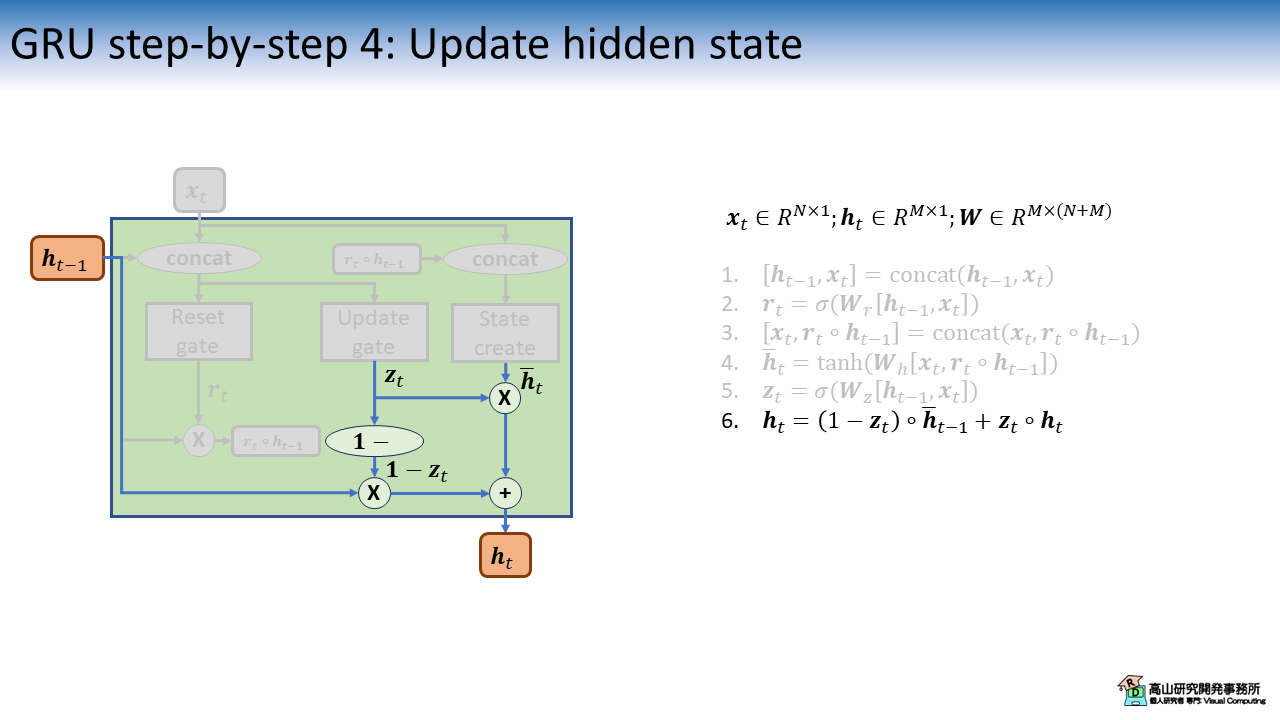
この処理は2.4項で紹介したLSTMのセル状態の更新に似た処理ですが,LSTMでは重みが各項で独立しているのに対して,GRUでは重みの合計が1となる加重平均を計算している点が異なります.
今回はLSTMとGRUの内部動作を紹介しましたが,如何でしたでしょうか?
当初は前回の記事の後半に入れるつもりだったのですが,長くなってしまったので分けることにしました.
LSTMやGRUは様々な工夫が凝らされていて,内部動作を細かく追っていくと面白いですね.
細かいところを最新の技術で置き換えていったらまだまだ良くなりそうです.
(PyTorchのRNN層の実装は少し癖が強くて拡張し辛いところが難点ですが...)
今回紹介した話が,これから手話認識や深層学習を勉強してみようとお考えの方に何か参考になれば幸いです.