目次
こんにちは.高山です.
今回は前々回,前回に引き続き,RNN層に関する記事 (第五回, 第六回, 第七回) の補足になります.
PyTorchのRNN層は,出力として特徴系列と最後に処理したフレームに対応する内部状態 (隠れ状態やセル状態) を返します (SRNN層では,output が特徴系列,h_n が隠れ状態).
これまでの記事では特徴系列を主に使用していたため,隠れ状態については詳しく説明していませんでした.
そこで今回は,PyTorchのRNN層が出力する特徴系列と隠れ状態の関係や,隠れ状態を利用するケースについて解説したいと思います.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
1. 特徴系列と隠れ状態の関係
1.1 デフォルト構成
特徴系列と隠れ状態の関係は,RNNのレイヤ構成やマスキング設定に応じて変化します.
レイヤ構成については第五回の記事で,マスキングについては第六回の記事で説明していますので,よろしければご一読ください.
図1は,デフォルト構成のときの特徴系列と隠れ状態の関係を示しています.
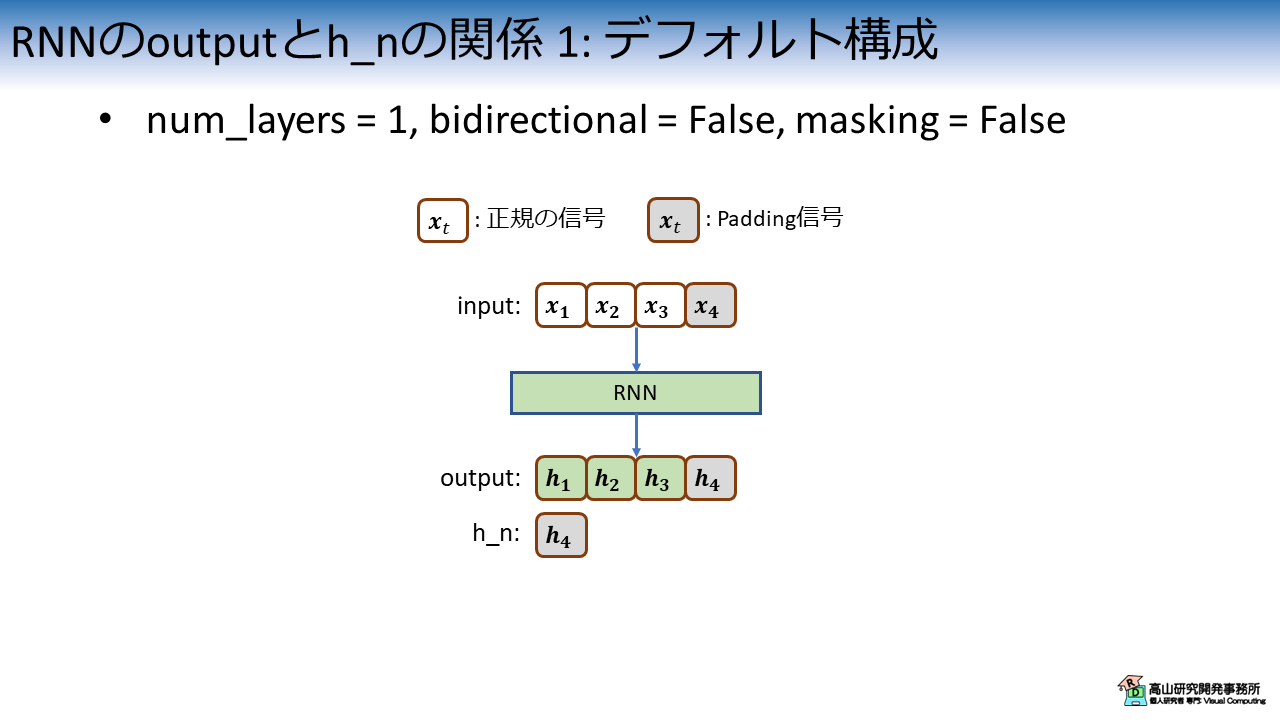
入力系列のうち,正規の信号は白色で表し,Padding 信号は灰色で示しています.
デフォルト構成ではRNN層が返す隠れ状態は,出力する特徴系列の最終フレームと対応するため,図1の例では \(\boldsymbol{h}_4\) が返されます.
1.2 Stacked RNN
図2は,RNN層のインスタンス化時に num_layers = 2 と設定した場合の特徴系列と隠れ状態の関係を示しています.
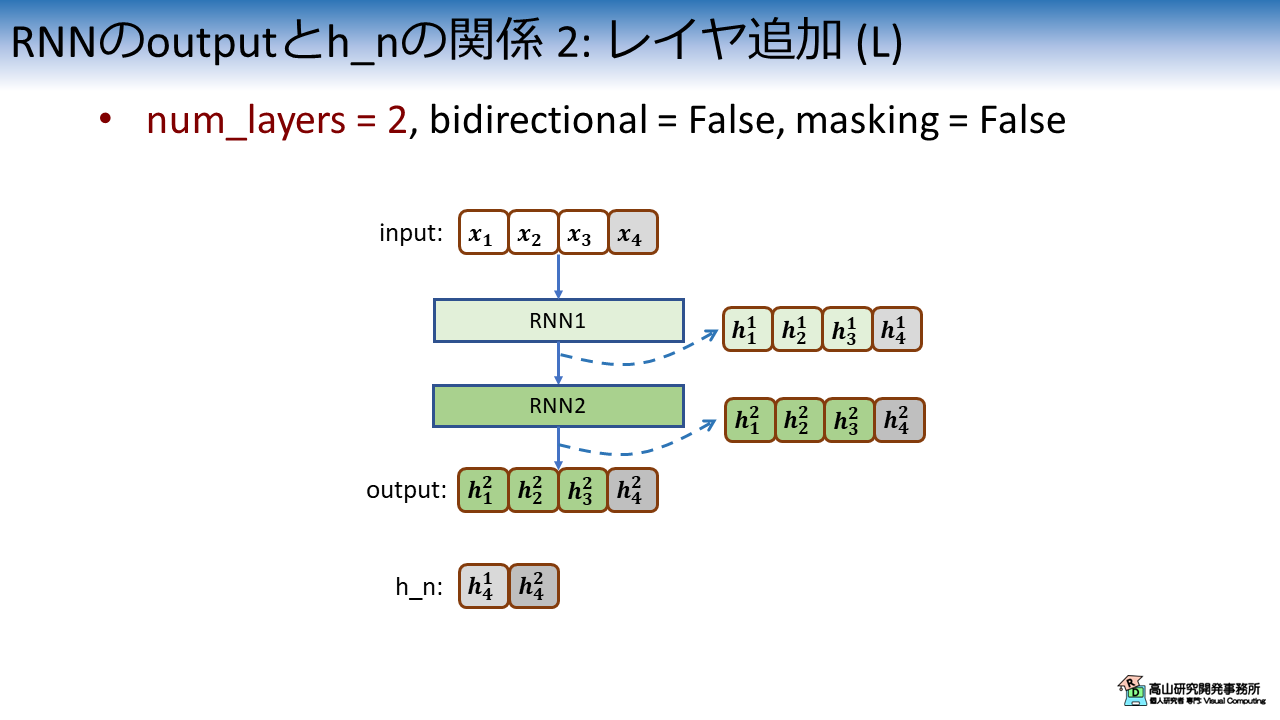
num_layers はRNN層の数を指定する引数で,1より上の値を設定した場合は内部でRNN層がカスケード接続されます.
図2に示すように,RNN層は最終段の特徴系列を出力します.
このとき,内部では各段のRNN層が特徴系列を出力していて,図中では上付き文字で各段の出力を示しています (1段目の出力が\(\boldsymbol{h}^1_1\), 2段目の出力が\(\boldsymbol{h}^2_1\)).
特徴系列には2段目の値だけが含まれています.
一方で,隠れ状態は各段の最終フレームが結合した状態で返されます.
1.3 Bidirectional RNN
図3は,RNN層のインスタンス化時に bidirectional = True を設定した場合の特徴系列と隠れ状態の関係を示しています.

bidirectional = True とした場合,下記に示す2種類のRNN層が内部で作られます.
- forward RNN (FRNN): 順送りで計算を行う (\(\boldsymbol{h}^F_1 \rightarrow \boldsymbol{h}^F_2 \rightarrow \boldsymbol{h}^F_3 \rightarrow \boldsymbol{h}^F_4\) の順で出力)
- backward RNN (BRNN): 逆送りで計算を行う (\(\boldsymbol{h}^B_4 \rightarrow \boldsymbol{h}^B_3 \rightarrow \boldsymbol{h}^B_2 \rightarrow \boldsymbol{h}^B_1\) の順で出力)
特徴系列は,FRNNとBRNNの出力を連結した特徴量になっています.
このとき,BRNNの出力は入力に合わせてソートされています.
一方で,隠れ状態はFRNNとBRNNが "最後に出力した" 特徴量を連結した形になっています.
つまり,\([\boldsymbol{h}^F_4, \boldsymbol{h}^B_1]\) という値が返されます.
1.4 Stacked + Bidirectional RNN
次に,第1.2項,第1.3項で紹介した設定を同時に与えた場合を見ていきます.
図4は,RNN層のインスタンス化時に num_laryers = 2, bidirectional = True を設定した場合の特徴系列と隠れ状態の関係を示しています.

この設定のときは,FRNN,BRNN双方が内部でカスケード接続されます.
内部ではFRNN,BRNN共に各段のレイヤが特徴系列を出力していて,最終段の特徴系列が返されます.
隠れ状態はFRNNとBRNN内の全ての段が "最後に出力した" 特徴量を連結した形で返されます.
このとき,特徴量の並び順は \([\boldsymbol{h}^{F1}_4, \boldsymbol{h}^{B1}_1, \boldsymbol{h}^{F2}_4, \boldsymbol{h}^{B2}_1]\) という順になっています.
1.5 マスキング適用時
図5は,Padding信号のマスキング処理を適用した場合の特徴系列と隠れ状態の関係を示しています.
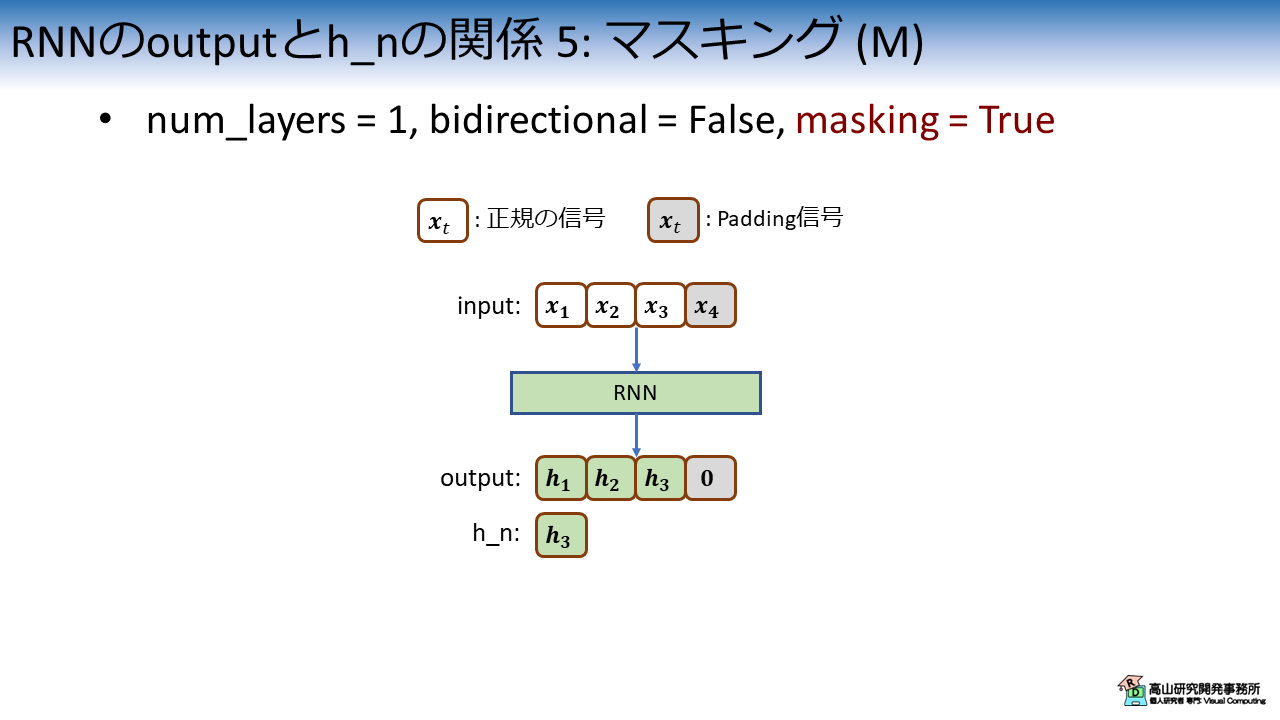
第六回の記事で説明したように (第3.1項をご参照ください),PyTorchのRNN層ではダミー信号をスキップすることでマスキング処理を行います.
マスキング後は,バッチを形成するために再度Paddingを行います.
結果として,特徴系列のPadding信号に対応する箇所は,特定の値 (ゼロベクトルなど) で埋められます.
一方,隠れ状態は "最後に出力した" 特徴量なのでPadding信号の手前 (図5では \(\boldsymbol{h}_3\)) の値が返されます.
1.6 Stacked RNNにマスキング適用時
図6は,num_layers = 2 で,かつ,Padding信号のマスキング処理を適用した場合の特徴系列と隠れ状態の関係を示しています.
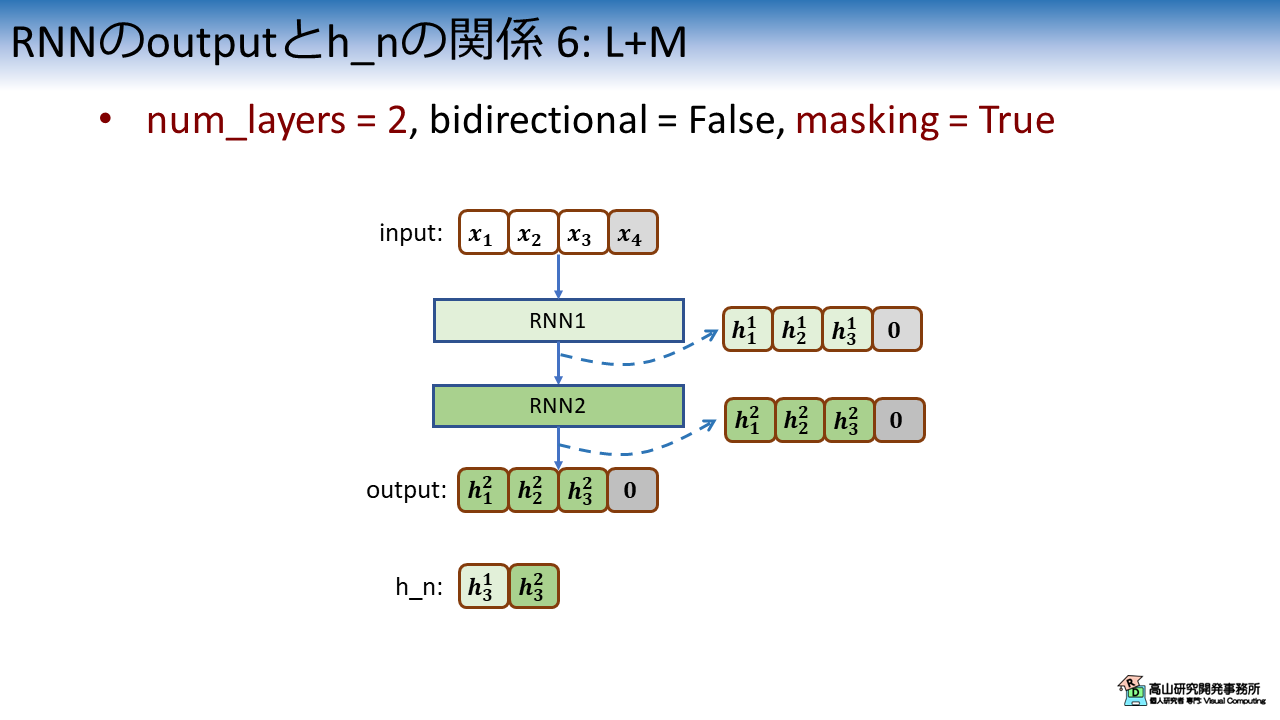
ここから先は,ここまでに紹介した処理の組み合わせで考えればよいです.
RNN層は最終段の特徴系列を出力しますので,特徴系列は2段目の出力値となり,Padding箇所はゼロクリアされます.
隠れ状態は各段が "最後に出力した" 特徴量が連結されますので,[\(\boldsymbol{h}^1_3, \boldsymbol{h}^2_3\)] となります.
1.7 Bidirectional RNNにマスキング適用時
図7は,bidirectional = True で,かつ,Padding信号のマスキング処理を適用した場合の特徴系列と隠れ状態の関係を示しています.
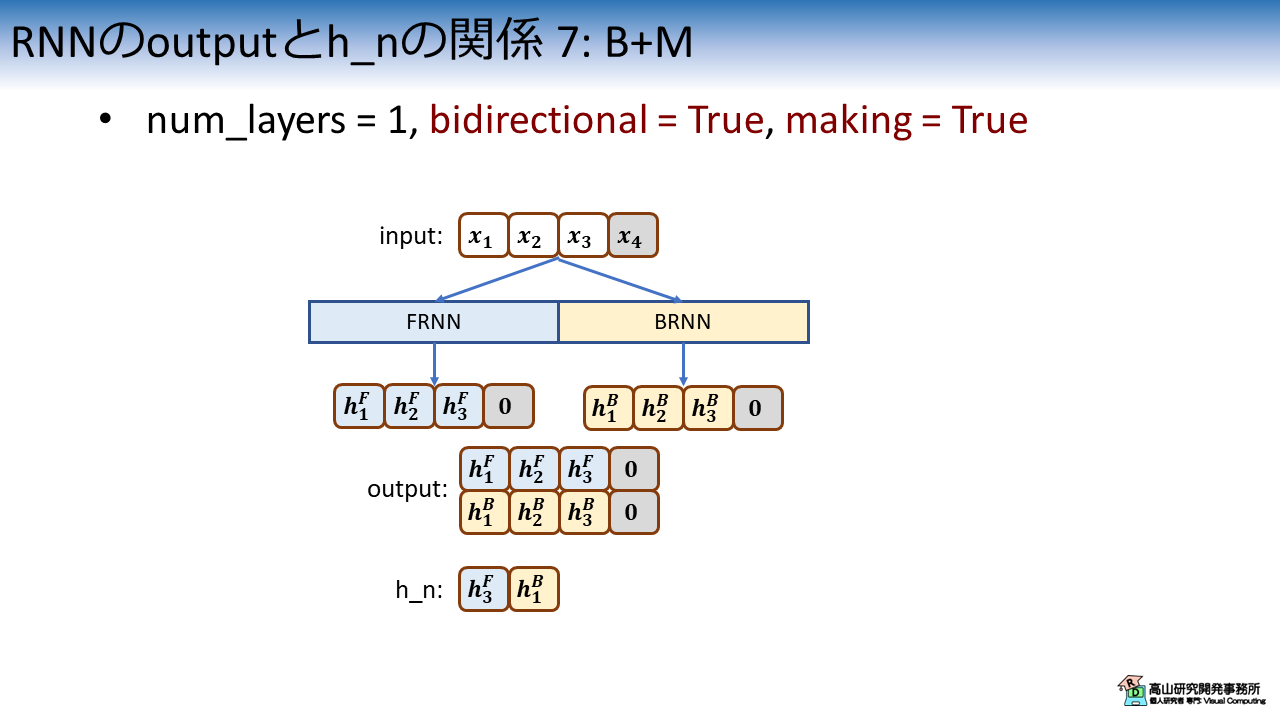
ここも1.6項と同様に考えればよく,特徴系列はFRNNとBRNNの出力を連結した特徴量になり,Padding箇所はゼロクリアされます.
隠れ状態はFRNNとBRNNが "最後に出力した" 特徴量が連結されますので,[\(\boldsymbol{h}^F_3, \boldsymbol{h}^B_1\)] となります.
1.8 Stacked Bidirectional RNNにマスキング適用時
図7は,num_layers = 2, bidirectional = True で,かつ,Padding信号のマスキング処理を適用した場合の特徴系列と隠れ状態の関係を示しています.
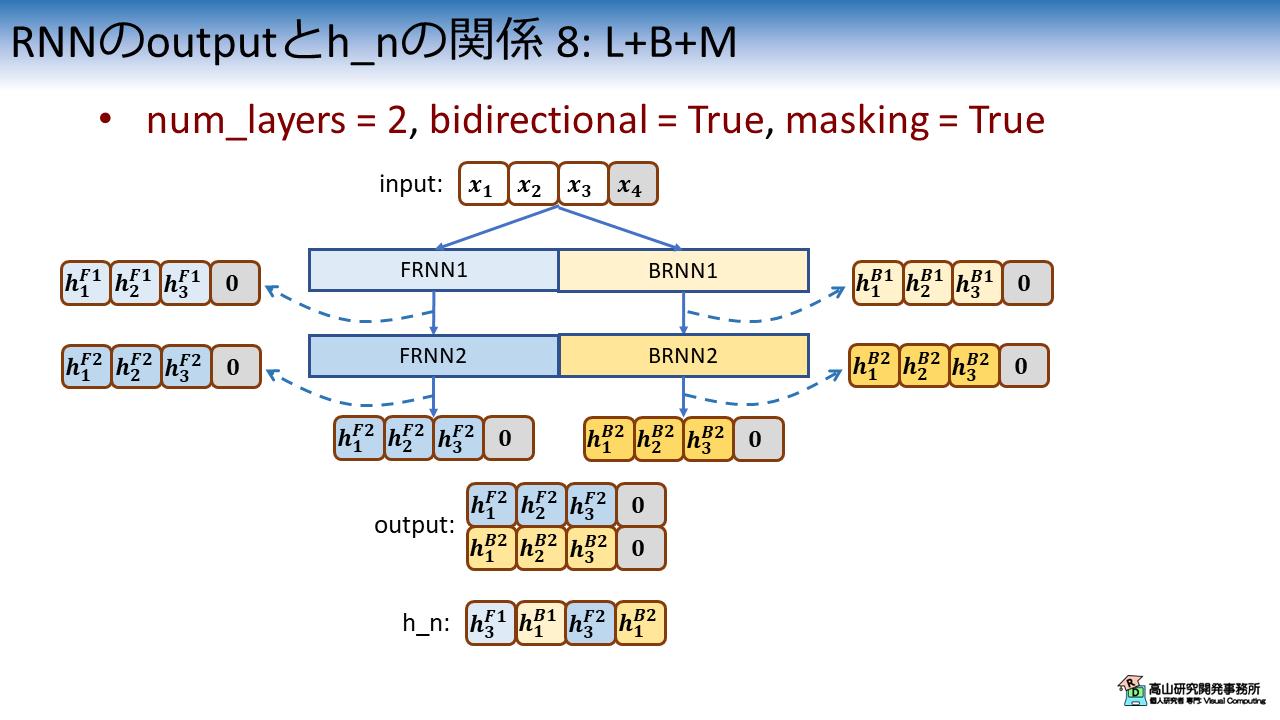
1.6項, 1.7項と同様に考えればよく,特徴系列は最終段のFRNNとBRNNの出力を連結した特徴量になり,Padding箇所はゼロクリアされます.
隠れ状態は各段のFRNNとBRNNが "最後に出力した" 特徴量が連結されますので,[\(\boldsymbol{h}^{F1}_3, \boldsymbol{h}^{B1}_1, \boldsymbol{h}^{F2}_3, \boldsymbol{h}^{B2}_1\)] となります.
2. 隠れ状態を利用するケース
第2節では,(実装上で意識的に) 隠れ状態を利用するケースを紹介します.
具体的には,下記に挙げる3個のケースを紹介します.
- 特徴量として利用
- Encoder-Decoder
- オンライン認識
2.1 特徴量として利用
図9は,隠れ状態を認識の際の特徴量として利用する場合の処理構成を示しています.

この構成では,認識のための特徴量として最終フレームでRNN層が出力した隠れ状態を用います.
中間結果をメモリ上に保持する必要が無くなるため,処理が軽量になる利点があります.
一昔前まではこの構成が主流で,LSTM [Hochreiter'97, Gers'00, Gers'03, Sak'14] やGRU [Cho'14] の文献もこの構成を使用しています.
比較として,今までの記事で使用してきた,特徴系列を利用する場合の処理構成を図10に示します.
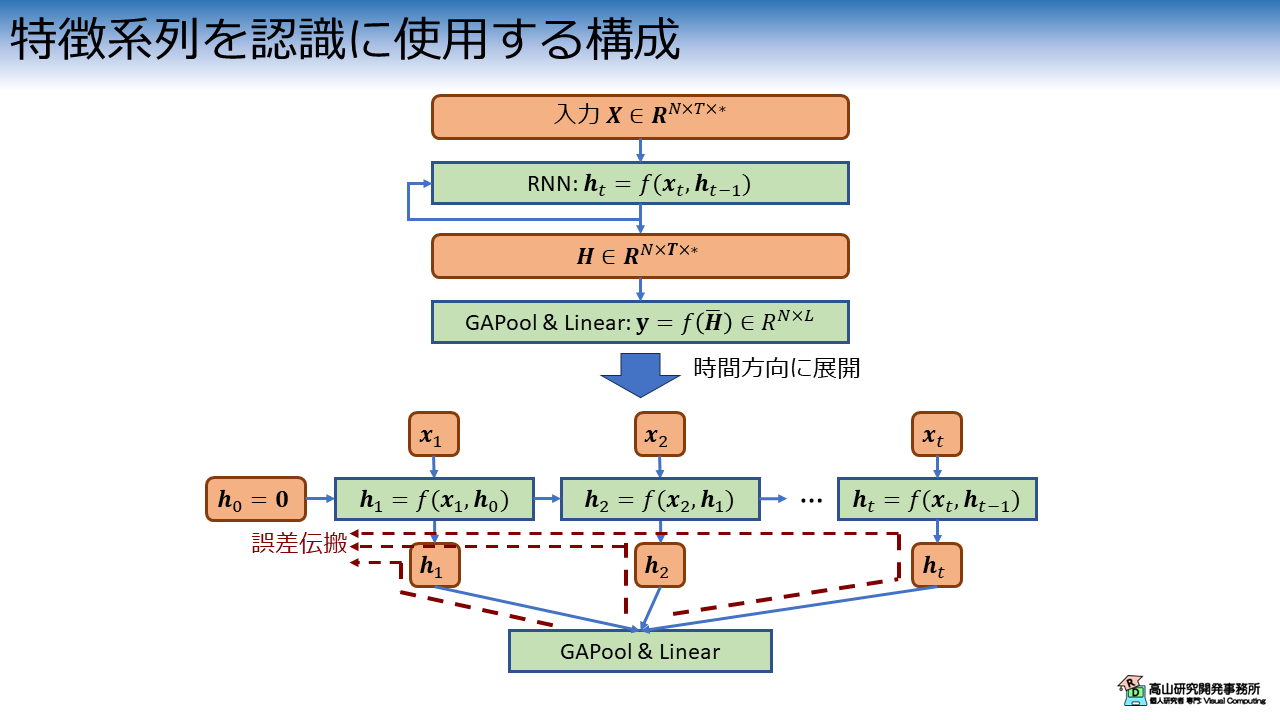
特徴系列を利用する構成がいつから用いられるようになったのかは定かではありませんが,動作認識の分野では2017年頃には導入されているようです[Liu'17].
余談ですが,図10に示すように特徴系列を認識の特徴量として用いる場合は,隠れ状態を用いる場合と誤差伝播の経路が異なります.
第七回で少し触れましたが (4.3項をご参照ください) この場合はSRNNの問題点とされている勾配消失などが緩和されるのではないかと感じています.
(実験で確かめたわけではありませんが)
- [Hochreiter'97]: S. Hochreiter, "Long Short-term Memory," Neural Computation, Vol.9, No.8, pp.1735-80, available here, 1997.
- [Gers'00]: F. A. Gers, et al., "Learning to forget: continual prediction with LSTM," Neural Computation, Vol.12, No.10, pp.2451-2471, available here, 2000.
- [Gers'03]: F. A. Gers, et al., "Learning precise timing with LSTM recurrent network," Journal of Machine Learning Research, Vol.3, pp.115-143, available here, 2003.
- [Sak'14]: H. Sak, et al., "Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition," arXiv:1402.1128, available here, 2014.
- [Cho'14]: K. Cho, et al., "Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation," Proc. of the EMNLP, available here, 2014.
- [Liu'17]: L. Jiu, et al., "Global Context-Aware Attention LSTM Networks for 3D Action Recognition," Proc. of the IEEE CVPR, available here, 2017.
2.2 Encoder-Decoder
次に紹介するのは,Encoder-Decoderと呼ばれるアーキテクチャを用いるケースです.
このアーキテクチャは翻訳などでよく用いられます.
図11にEncoder-Decoderの処理構成を示します.
(かなり端折っています.ご興味のある方は文献[Bahdanau'15]などをご参照ください)
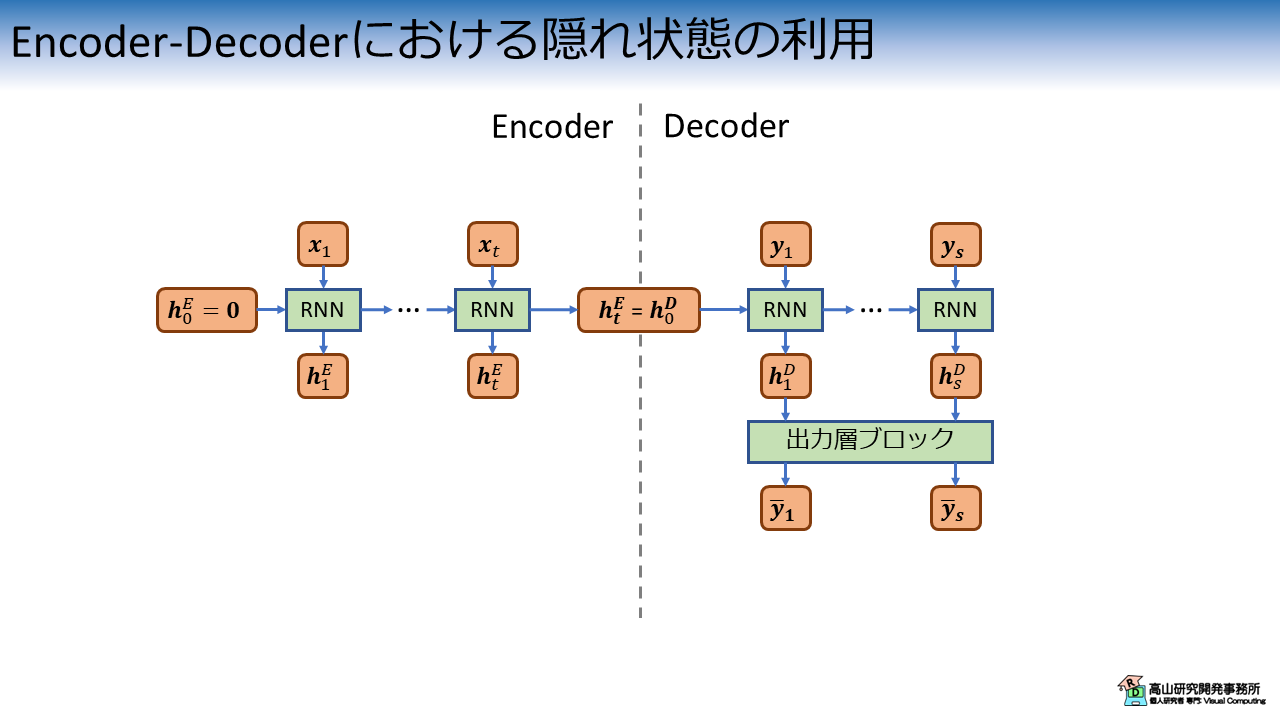
Encoder-Decoderアーキテクチャではまず,Encoderで片方の入力系列 (例えばフランス語) をRNN層で特徴抽出します.
Encoderの処理後にDecoderでは,別の入力系列 (例えば英語) をRNN層で特徴抽出し認識 (翻訳) 結果を出力します.
このとき,Encoderの処理結果 (\(\boldsymbol{h}^E_t\)) はDecoderの入力 (\(\boldsymbol{y}_1\)) や初期隠れ状態 (\(\boldsymbol{h}^D_0\)) として用いられます.
- [Bahdanau'15]: D. Bahdanau, et al., "Neural Machine Translation by Jointly Learning to Align and Translate," Proc. of the ICLR, available here, 2015.
2.3 オンライン認識
最後に紹介するのはオンライン認識を行うケースです.
このケースは図12に示すように,少し特殊なデータの入れ方をします.
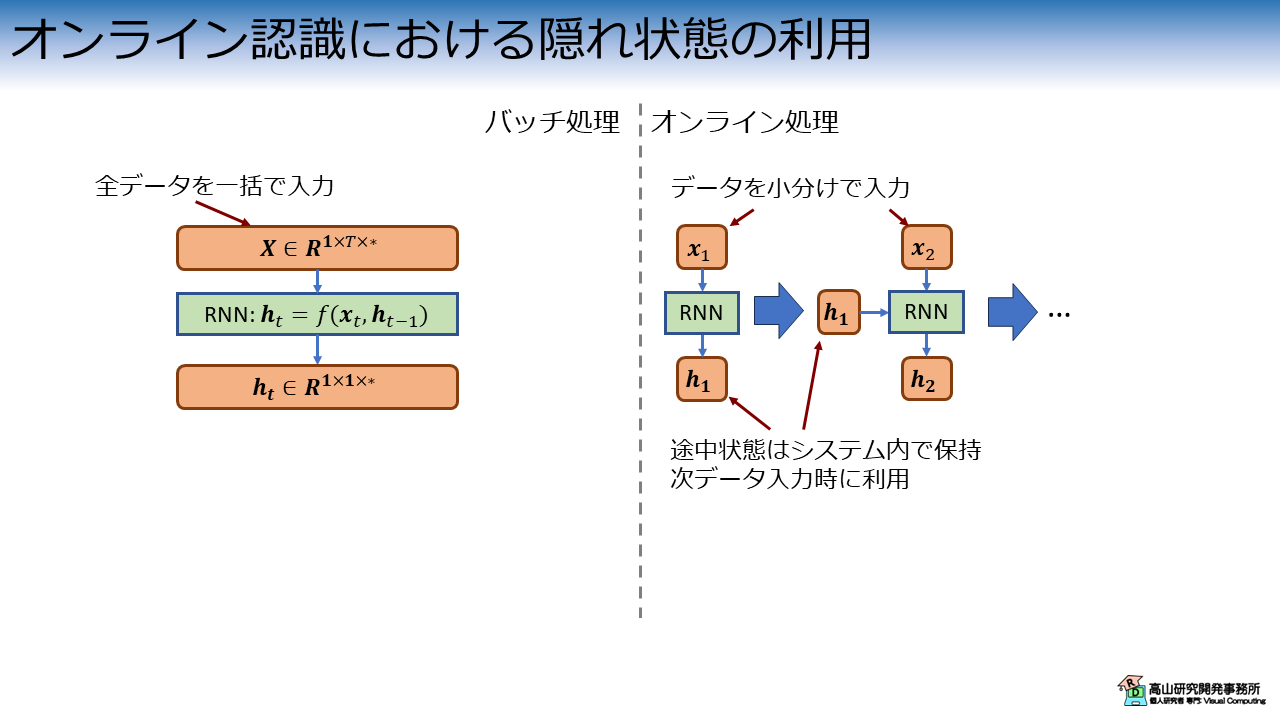
今までの記事で紹介してきた認識処理は,いわゆるバッチ処理と呼ばれる方法で,入力データを一括で処理して認識結果を得ます.
この場合は認識に必要な処理を一括で行うため,システムが途中状態を記憶しておく必要はありません.
一方,オンライン処理ではデータが小分けでシステムに入力されてきます.
この場合,一回目に入力されたデータに全データが含まれているかはシステムには分かりません.
そこで,システムは一回目のときに出力した隠れ状態を保持し,二回目にデータが入力された際の初期隠れ状態として利用することで処理を継続します.
オンライン認識は手話認識では取り組みが少ないですが (手前味噌ですみませんが,[Takayama'22]などはあります(^^;)),音声認識では継続的に取り組まれています[Inaguma'20, Shim'23].
なお,ここではオンライン認識 (Online recognition) と読んでいますが,用語は定まっておらず,Streaming recognition や Incremental recognition などの用語も用いられます.
- [Takayama'22]: N. Takayama, et al., "Skeleton-based Online Sign Language Recognition using Monotonic Attention," Proc. of the VISAPP, 2022.
- [Inaguma'20]: H. Inaguma, et al., "Enhancing Monotonic Multihead Attention for Streaming ASR," Proc. of the INTERSPEECH, available here, 2020.
- [K. Shim'23]: K. Shim, et al., "Knowledge Distillation from Non-streaming to Streaming ASR Encoder using Auxiliary Non-streaming Layer," Proc. of the INTERSPEECH, available here, 2023.
今回はPyTorchのRNN層が出力する特徴系列と隠れ状態の関係や,隠れ状態を利用するケースについて紹介しましたが,如何でしたでしょうか?
PyTorchのRNNページを見ると分かりますが (Outputsの項をご参照ください),RNN層が返す隠れ状態は特徴系列と次元の並び方が異なります.
意識的に隠れ状態を使うケースは最近はあまりないですが,いざ使おうとすると戸惑うかもしれませんのでご注意ください.
今回紹介した話が,これから手話認識や深層学習を勉強してみようとお考えの方に何か参考になれば幸いです.