
目次
こんにちは.高山です.
先日の記事で手話関連技術について大まかに紹介させていただきました.
今回からはもう少し具体的に,研究開発で用いられる技術やデータセットなどを紹介していきたいなと思っています.
そこで今回は,KaggleのGoogle Isolated Sign Language Recognition (以下,GISLR) で用いられたデータセットについてお話したいと思います.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/17: タグを更新しました
1. GISLRコンペティションについて
こちらの記事でも紹介させていただきましたが,GISLRコンペティションでは,アメリカ手話 (American Sign Language: ASL) の手話単語を題材として,孤立手話単語認識の性能を競い合います.
このコンペティションでは認識モデルの学習・検証用として,下記のようなデータセットが配布されます.
- ASL単語数: 250種類
- ASL話者数: 21名
- 入力データ: MediaPipe (version 0.9.0.1) による追跡点系列
- 総データ数: 94,477個
- ライセンスおよび注意事項: CC-BY 4.0.ただし,個人識別に用いることはできません.
また,基本的に教育ゲーム等における利用を想定しており,翻訳や自然言語インターフェース (AIアシスタンスやチャットボットなど) における利用には適していないとのことです. - ライセンサ: Deaf Professional Arts Network and the Georgia Institute of Technology
コンペティションは既に終了していますが,データセットの入手および,テストデータを用いたモデル評価は今でも行なえます.
ただし,モデルはTensorflow Liteの形式で提出する必要があります.
また,モデルは規定以上のレイテンシでデータを処理できないといけません.
詳細については,公式サイトをご参照ください.
2. データセットについて
2.1 入手方法
図1に示すように,今回紹介するデータセットはKaggle内のコンペティションページからダウンロードできます.
全体をダウンロードすると,50GB以上のサイズになりますので注意してください.
また,ダウンロードにはKaggleのアカウントが必要です.
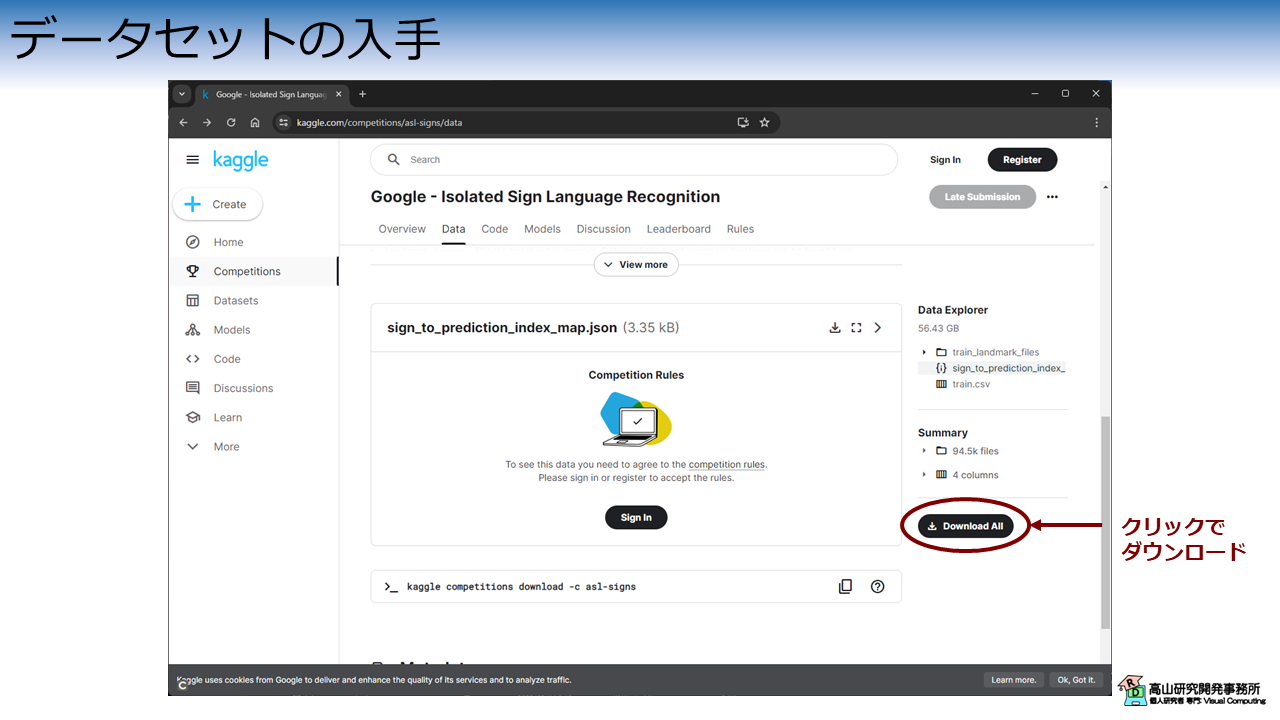
全体のダウンロードが完了すると,asl-signs.zip という ZIPファイルが取得できます.
2.2 データの内容
ZIPファイルを解凍すると,下記のようなファイルが展開されます.
$ unzip asl-signs.zip
$ ls asl-signs
sign_to_prediction_index_map.json train.csv train_landmark_files
辞書ファイル
sign_to_prediction_index_map.json は所謂辞書ファイルで,次のように単語名と数値の関係が定義されています.
$ cat sign_to_prediction_index_map.json
{
"TV": 0,
"after": 1,
"airplane": 2,
...
"zipper": 249
}
表示内容から分かるように,250種類の ASL単語が 0 始まりの番号で定義されています.
認識モデルは追跡点を入力した際に,辞書ファイルで定義した数値を出力するように実装する必要があります.
例えば,入力が TV というASL単語を表している場合,認識モデルは 0 という数値を返すように作らなければなりません.
サンプル情報
train.csv は各サンプルの情報を表形式でまとめたデータで,下記のような内容になっています.
path participant_id sequence_id sign
0 train_landmark_files/26734/1000035562.parquet 26734 1000035562 blow
1 train_landmark_files/28656/1000106739.parquet 28656 1000106739 wait
2 train_landmark_files/16069/100015657.parquet 16069 100015657 cloud
3 train_landmark_files/25571/1000210073.parquet 25571 1000210073 bird
4 train_landmark_files/62590/1000240708.parquet 62590 1000240708 owie
... ... ... ... ...
94472 train_landmark_files/53618/999786174.parquet 53618 999786174 white
94473 train_landmark_files/26734/999799849.parquet 26734 999799849 have
94474 train_landmark_files/25571/999833418.parquet 25571 999833418 flower
94475 train_landmark_files/29302/999895257.parquet 29302 999895257 room
94476 train_landmark_files/36257/999962374.parquet 36257 999962374 happy
各カラムの内容は次のとおりです.
path: 骨格追跡点データへのパスparticipant_id: 手話話者IDsequence_id: データ番号sign: 何の手話単語を表出しているか
追跡点データ
train_landmarks は追跡点データが格納されているディレクトリです.
中身は話者ID毎のサブディレクトリで構造化されています.
各ファイルはApatche Parquet形式で格納されており,Pythonの場合はPandasを用いてロードすることが可能です.
格納されているデータ例を下記に示します.
import pandas as pd
df = pd.read_parquet("./train_landmark_files/26734/1000035562.parquet")
print(df)
frame row_id type landmark_index x y z
0 20 20-face-0 face 0 0.494400 0.380470 -0.030626
1 20 20-face-1 face 1 0.496017 0.350735 -0.057565
2 20 20-face-2 face 2 0.500818 0.359343 -0.030283
3 20 20-face-3 face 3 0.489788 0.321780 -0.040622
4 20 20-face-4 face 4 0.495304 0.341821 -0.061152
... ... ... ... ... ... ... ...
12484 42 42-right_hand-16 right_hand 16 0.001660 0.549574 -0.145409
12485 42 42-right_hand-17 right_hand 17 0.042694 0.693116 -0.085307
12486 42 42-right_hand-18 right_hand 18 0.006723 0.665044 -0.114017
12487 42 42-right_hand-19 right_hand 19 -0.014755 0.643799 -0.123488
12488 42 42-right_hand-20 right_hand 20 -0.031811 0.627077 -0.129067
[12489 rows x 7 columns]
上に示すように,データは表形式で格納されており,各カラムの内容は次のとおりです.
frame: 追跡点系列のフレーム番号.上の例で示されるとおり,0始まりではありません.
また,途中抜けの番号もありますが評価で用いられるコードを見る限りでは,そのようなフレームは単純に無視されるようです.row_id: 各行のユニークID.[frame][type][landmark_index] の形式になっています.type: 身体部位名.face,left_hand,pose,right_handのどれかになります.landmark_index: 各部位の追跡点番号x,y,z: 追跡点の座標値
追跡点は face, left_hand, pose, right_hand の順に並んでおり,それがフレーム数分行方向に積まれています.
この並び方は全データに共通しているため,各カラムを細かく追いかける必要はなく,下記に示す処理で追跡点を統一的にロードすることができます.
1 2 3 4 5 6 7 8 | |
- 1行目: 追跡点の個数を事前定義
- 4-5行目: `x`, `y`, `z` のカラムだけロード
- 6-7行目: `[T, J, C]` の形状に変形して返す
- T: フレーム数
- J: 追跡点数.ここでは543
- C: 特徴量数.ここでは3
可視化例
図2に,データセットに含まれるASL単語, duck の可視化例を示します.
図2(a)は,ロードした追跡点の可視化例です.
見やすくするために一部の追跡点だけ描画しています.
また,本データセットには元動画が含まれていないので,参考までに高山の手話動画を図2(b)に示します.
(見様見真似で行っているだけですので,注意してください)
3. 統計情報
本節では,データセット全体の統計情報を解析したいと思います.
3.1 欠損データ
図2(a)から分かるように,追跡点データには追跡に失敗したフレームや部位 (以降,欠損データ) が含まれています.
ここでは,欠損データが含まれるサンプルと,どの部位の欠損データが多いかを解析してみます.
図3はデータセット内に欠損データが含まれるサンプルがどれだけあるかを示しています.
縦軸は全サンプルに対する欠損が含まれるサンプルの割合を示し,横軸は欠損が含まれる部位を示します.
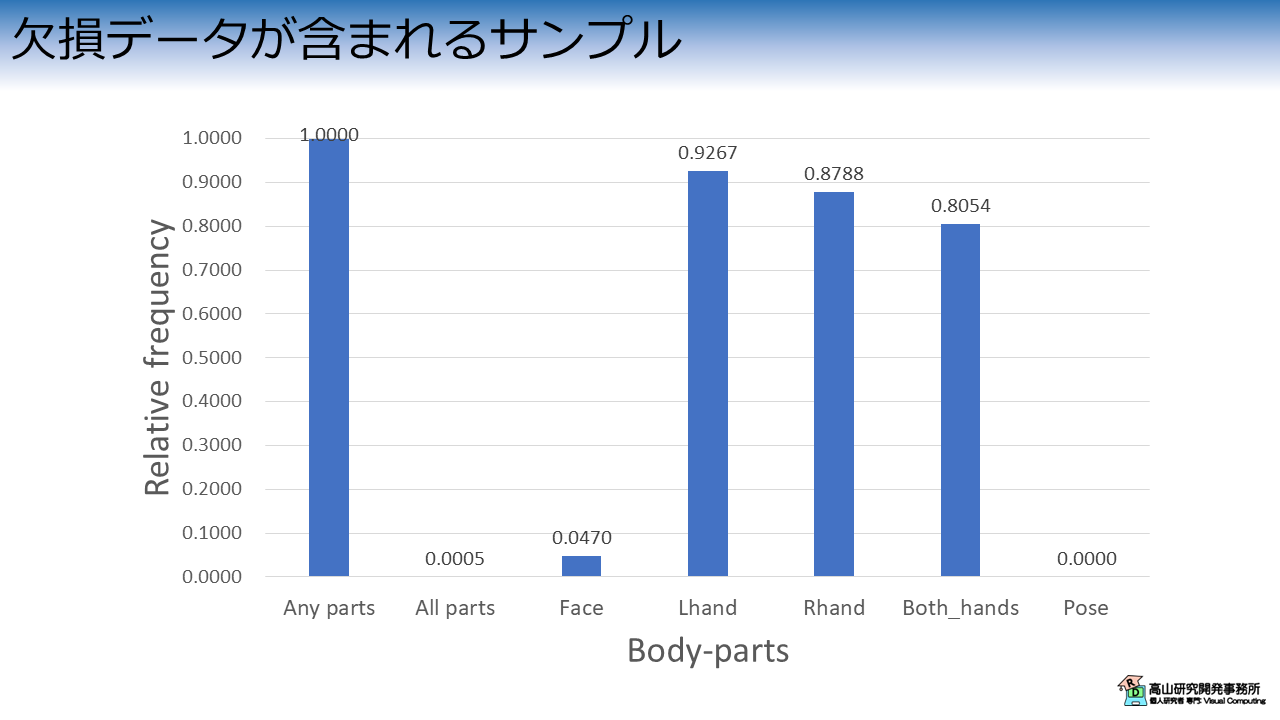
Any parts に示されるように,全てのサンプルで何かしらの欠損データが含まれていることが分かります.
All parts はフレーム全体が欠損していることを示しています.
第2.2項-追跡データで示したロード処理から分かるとおり,欠損フレームは単純に無視されます.
他の縦棒は各部位の欠損を示しており,特に手の追跡が失敗するケースが多いことが分かります.
また,手が顔に重なるケースなどで,顔の追跡に失敗するケースもあるようです.
上記から分かるとおり,本データセットには欠損データが多数含まれているため,認識モデルには欠損データに対する各種の対処法を実装する必要があります.
3.2 系列長
次に,サンプルの系列長を解析してみます.
図4はデータセットの系列長分布を示しています.
縦軸は頻度を示しており,横軸は系列長のデータ区間 (ビンと言います) を示しています.
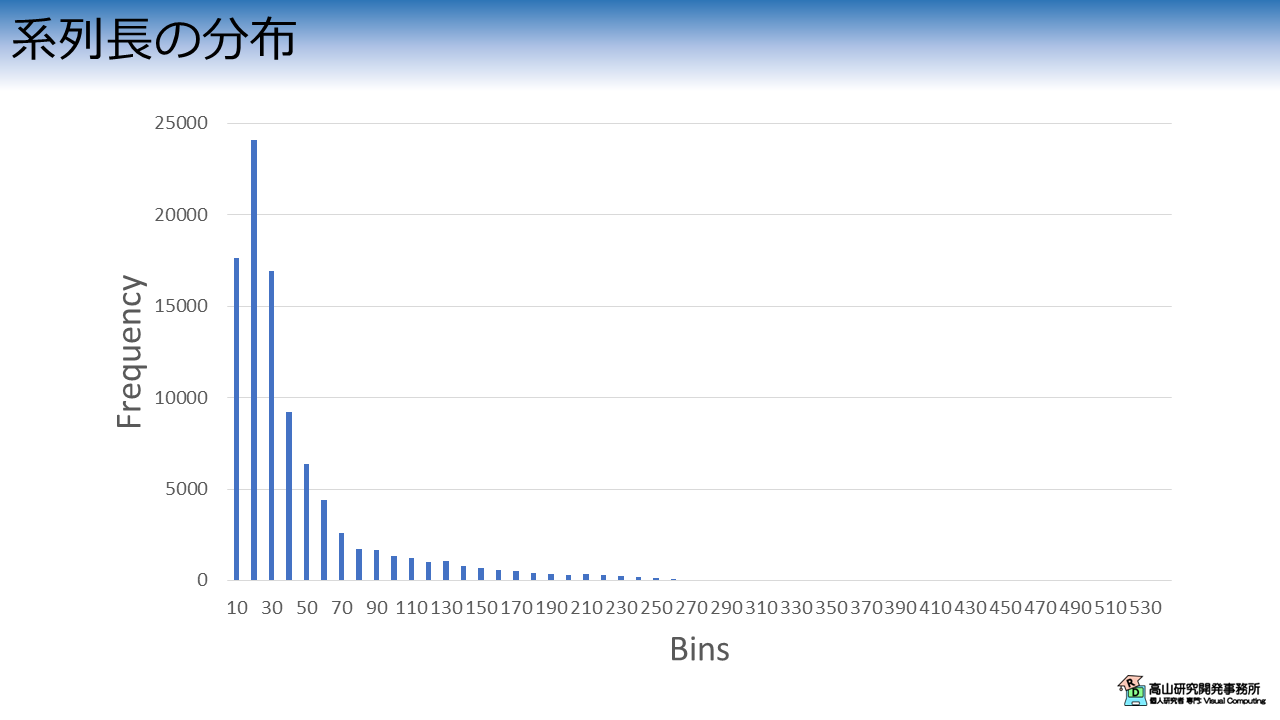
各サンプルは1単語の手話動作のため,10から20フレーム程度 (1秒に満たない系列長) で動作が完了するサンプルが最も多くなっています.
一方,10フレーム以下のサンプルや,数百フレーム (10秒を超える系列長) かかっているサンプルも含まれています (見えづらいですが,数サンプル程度あります).
このような極端な長さのサンプルは,撮影に失敗しているデータである可能性が高いです.
また,長いサンプルに合わせて学習を行うと,メモリを多く消費したり学習時間が長くなってしまったりします.
そのため,前処理でデータをカットしたり,系列長を変えたりなどの工夫をする必要が出てきます.
3.3 単語数の分布
最後に,単語数の分布を解析してみます.
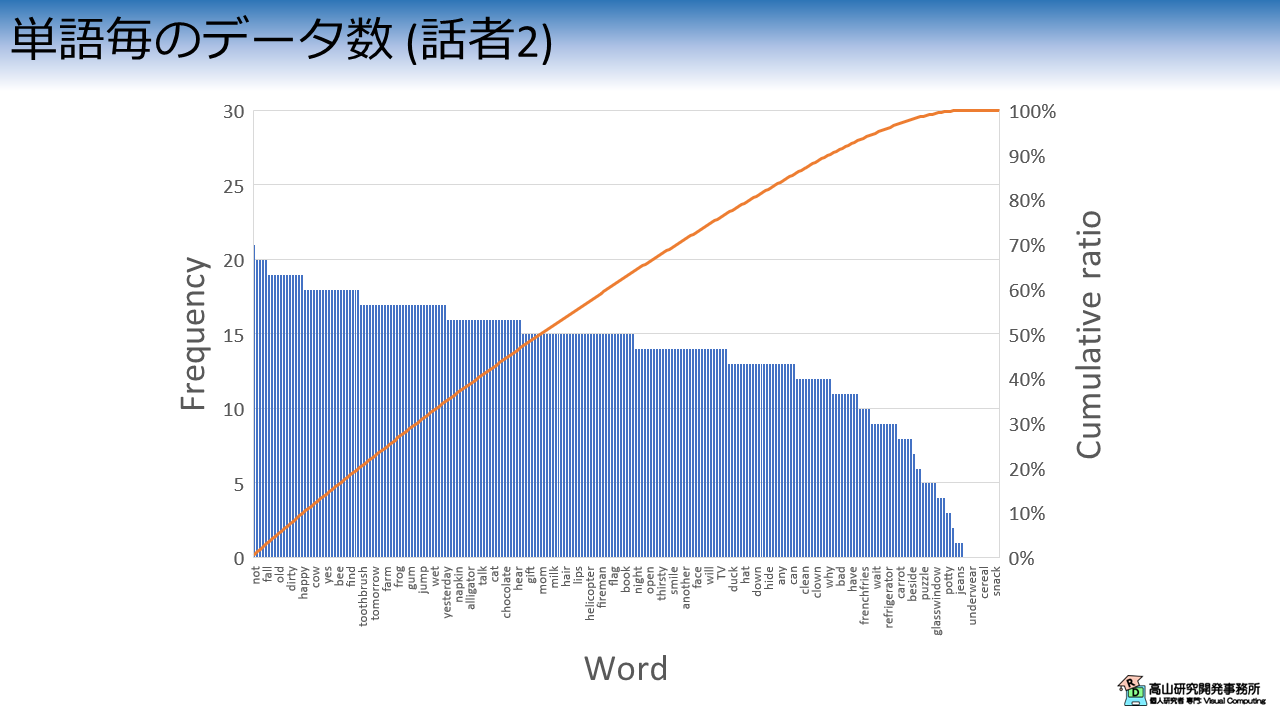
図5は単語毎のデータ数を話者別 (ここでは話者1,話者2とします) に示したグラフです.
左側の縦軸と青棒は頻度を示しており,右側の縦軸とオレンジ線はサンプル数の累積比率を示しています.
横軸は単語を示しており,サンプル数で降順に並べられています.
(見えづらくてすみません(^^;).画像をクリックすると大きな画像が別タブで開きます).
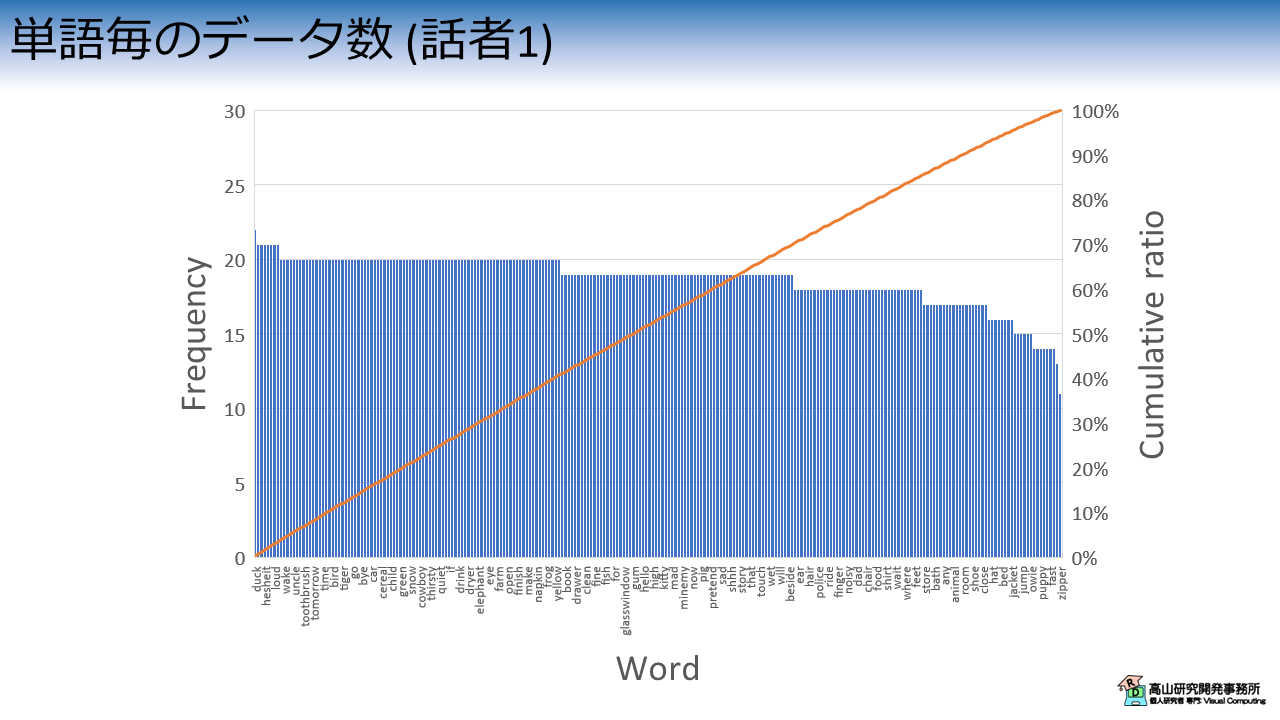
(a): 話者1
(b): 話者2
単語数の分布は話者毎,および単語毎に異なっています.
図5(a)に示したとおり,話者1は各単語に対して10 - 20個程度データがあるため,累積比率は直線に近くなっています.
一方図5(b)に示したとおり,話者2はデータ数のばらつきが多くデータが存在しない単語もあります.そのため,累積比率は曲線になっています.
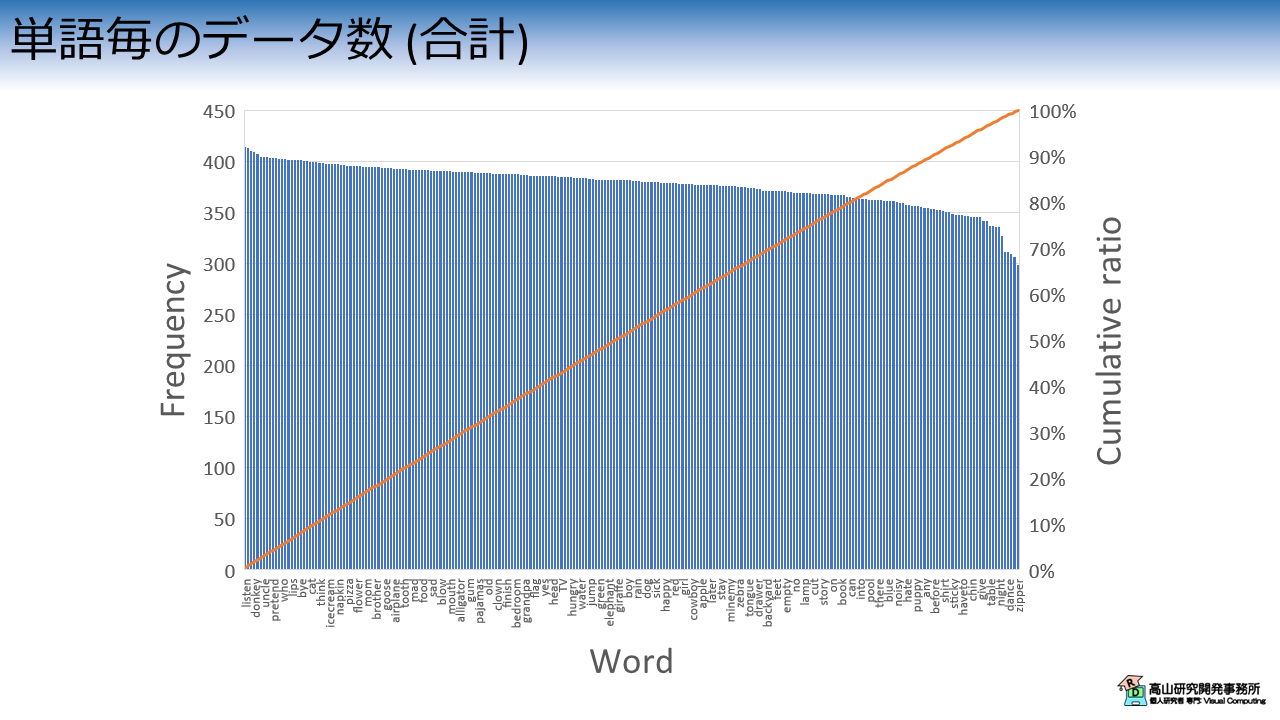
次に,図6にデータセット全体の単語数分布を示します.
各単語は300 - 400個程度のデータがあり,累積比率も直線に近い形をしています.
上記の結果から,学習データとテストデータの分け方に応じて,それぞれ異なる副作用が生じることを理解することが大事です.
例えば,学習データとテストデータを話者毎に分割した場合は,未学習 (学習: 話者2,テスト: 話者1) や未テスト (学習: 話者1,テスト: 話者2) の単語が生じる場合があります.
また,データセット全体を比率で分割した場合は,未学習や未テストの単語が生じる可能性は低いですが,分割方法にランダム性が生じる場合は結果の再現性に影響が大きく出る可能性があります.
どの状況でも対処可能なベストな分け方を見出すのは難しく,目的に応じて判断する必要があります.
(コンペティションのことだけを考えるのであれば,全データを学習させる場合もあり得ます)
今回はKaggleの孤立手話単語認識コンペティションで用いられたGISLRデータセットについて紹介しましたが,如何でしたでしょうか?
手話のデータセットは多くの場合,大学などの公共機関が取り扱っているので研究や教育用途に利用が制限されています.
本データセットが,CC-BYのような商用可能ライセンスになっているのは注目すべき点で,当サイトのように広告を入れているWebサイトにとってはありがたい存在です.
手話データセットの商用利用については,色々と難しい面もありますが,今後このようなデータセットが増えてきてほしいなと個人的には願っています.
今回はデータセットの紹介に焦点を絞りましたが,今後本データセットを用いて手話認識に関する具体的な技術の解説記事なども書いていきたいと思います. 今回紹介した話が,手話認識などにご興味をお持ちの方に何か参考になれば幸いです.




