目次
こんにちは.高山です.
以前の記事で,Numpy を用いてアフィン変換を骨格追跡点に適用して変形する方法を紹介しました.
今回は,同様の処理をTensorflowを用いて実装する方法を紹介します.
今回解説するスクリプトはGitHub上に公開しています.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/17: タイトル,タグ,サマリを更新しました
- 2023/10/30: 処理時間の計測方法を更新しました
1. モジュールのインストールとロード
まず最初に,下記のコードでモジュールをロードします.
1 2 3 4 5 6 7 8 9 10 | |
【コード解説】
- 標準モジュール
- gc: ガベージコレクション用ライブラリ
処理時間計測クラスの内部処理で用います.
- sys: Pythonシステムを扱うライブラリ
今回はバージョン情報を取得するために使用しています.
- time: 時刻データを取り扱うためのライブラリ
今回は処理時間を計測するために使用しています.
- functools: 関数オブジェクトを操作するためのライブラリ
処理時間計測クラスに渡す関数オブジェクト作成に使用しています.
- 画像処理・機械学習向けモジュール
- numpy: 行列演算ライブラリ
今回はデータのロードに用います.
- Tensorflow: ニューラルネットワークライブラリ
今回は行列演算機能を用います.
記事執筆時点のPythonと主要モジュールのバージョンは下記のとおりです.
1 2 3 | |
Python:3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0]
Numpy:1.23.5
Tensorflow:2.13.0
2. データのロードと確認
次に,下記の処理で変換前と変換後の追跡点データをダウンロードします.
変換後の追跡点データはNumpy編で紹介した処理で生成したデータです.
このデータは今回の処理で生成したデータとの比較に用います.
!wget https://github.com/takayama-rado/trado_samples/raw/main/test_data/finger_far0_non_static.npy
!wget https://github.com/takayama-rado/trado_samples/raw/main/test_data/finger_far0_non_static_affine.npy
ls コマンドでデータがダウンロードされているか確認します.
!ls
finger_far0_non_static_affine.npy finger_far0_non_static.npy sample_data
3. 実験用処理の実装
実験に先立って,処理時間計測用の関数と実験用定数を定義します.
次のコードは処理時間の値から,適切なSI接頭辞を設定し,文字列にして返します.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
- 引数
- val: 処理時間を示す値 (秒)
- 2-6行目: 変数の初期化
- 7-11行目: 接頭辞を選択して,表示値を調整
- 12行目: 表示文字列を作成
次のコードは,処理時間を格納した配列から統計量を求めて表示します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
- 引数:
- intervals: 処理時間のNumpy配列
- top_k: intervalsから,処理時間が短いサンプルをk個取り出して統計量を算出
- 2-3行目: Top K個のサンプル抽出
- 4-7行目: 統計量算出
- 9-16行目: 表示文字列を作成して表示
次のクラスは,入力した関数を複数回呼び出して,処理時間の統計量を表示します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
- 引数:
- trials: 入力関数の実行回数
- top_k: 値が定義されている場合,全体の処理時間配列から処理時間が短いサンプルをk個取り出して統計量を算出
- 9-10行目: 計測中はガベージコレクションをしないように設定
- 11-20行目: 処理時間計測処理
- 21-22行目: ガベージコレクションの設定を元に戻す
最後に,次のコードで実験用の定数を定義して処理時間計測クラスをインスタンス化しています.
1 2 3 | |
実際の所,Colabの様な複雑な処理環境で他のプロセスの影響を排除して純粋な処理時間を計測するのはかなり難しいです.
そこでここでは,処理の繰り返し数を \(100\) とし全体の統計量に加えて,処理時間の短い代表値 \(10\) 試行からも統計量を表示するようにしています.
4. アフィン変換の実装
ここから先は変換処理の実装・実行を行います.
Tensorflowは,プログラムの実行時に処理をコンパイル (計算グラフの作成) して実行します.
現在のTensorflowには,下記に示すとおり2種類の計算グラフ作成方法があります.
- Eager execution mode (Define-by-Run): データを入力した際に処理のコンパイルと実行を同時に行う.
Pythonの実行環境と親和性が高くインタラクティブな実行環境で利用しやすくなっています. - Graph mode (Define-and-Run): (C言語のように) 処理のコンパイルと実行が明確に別れて行われる.
処理の最適化性能が高いため高速に動作します.
今回は,変換処理をそれぞれの動作モードで動かして処理時間を比較してみたいと思います.
4.1. Define-by-run に基づく実装
本項ではまず,Define-by-run を用いた場合の実装を紹介します.
以前の記事の後半で紹介した,対象物内の特定位置を変換軸とする変換を実装していきます.
変換行列の算出処理
次のコードは,入力パラメータに応じた変換行列を算出する関数を実装しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
- 引数
- center: 変換軸座標 `(center_x, center_y)`
通常は物体中心位置や特定の追跡点位置を指定します.
- trans: 平行移動量 `(trans_x, trans_y)`
- scale: 拡大縮小量 `(scale_x, scale_y)`
- rot: 回転量 (ラジアン)
この値のみスカラーです.
- skew: せん断量 (ラジアン) `(skew_x, skew_y)`
- dtype: 出力データ型
- 7-25行目: 各変換行列を算出
`center_m` の算出では,指定座標を原点に移動するためにマイナスをかけた値を移動量として設定しています.
回転とせん断はラジアン値を入力として,それぞれ対応する三角関数を適用した値を設定しています.
平行移動では,最初に行う指定座標の原点への移動をオフセットとして加えた値を移動量として設定しています.
- 27-31行目: 指定したデータ型にキャスト
- 33-38行目: 初めに`mat` を単位行列で初期化し,各変換行列を順次適用
- 39行目: `dtype` で指定した型に変換して値を返す
アフィン変換の適用処理
次のコードは,追跡点配列に変換行列を適用する関数を実装しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
- 引数:
- inputs: 追跡点配列 `[T, J, C]`
- T: 動画フレームインデクス
- J: 追跡点インデクス
- C: 特徴量インデクス.今回は $(x, y, z, c)$ の4次元特徴量を用いています.
- mat: アフィン変換行列 `[3, 3]`
- 2行目: 追跡点配列から $(x, y)$ 座標列を取り出し
- 6-7行目: 特徴量次元の末尾に $1$ を加えて同次座標形式に変換
- 8行目: `xy` の特徴量次元に対してアフィン変換行列を適用
- 10-19行目: 変換後の$(x, y)$ 座標列を `inputs` に代入して返す
基本的に,Tensorflowでは配列に値を代入することができません.
ここでは `tensor_scatter_nd_update()` によって同じ結果になるように実装しています.
4-5行目のコメントに示しましたが,Numpy版の実装のように xy の形状を基に ones を生成すると,Tensorflow (Define-and-run時) ではエラーとなります.
これは,コンパイル時に xy の形状が定まっておらず,tf.ones()の引数仕様を満たせないためです.
そのため,ここでは tf.ones_like() で [T, J, 2] 形状の \(\boldsymbol{1}\) ベクトルを生成し,後に余分な特徴量を除去して値を得ています.
8行目の変換行列の適用では,Numpy版と同様にアインシュタインの縮約表記を用いた演算を行っています.
Einsum についてはこちらに簡単な解説記事を用意しています.
ご一読いただければうれしいです.
アフィン変換の実行
次のコードでは,追跡点を trackdata にロードして,関数の仕様に合わせて形状を変更しています.
今回用いるデータは [P, T, J, C] 形状 ( P は人物インデクス) の配列ですが,動画に映っている人物は1名だけですので P 軸は除去しています.
1 2 3 4 5 6 7 8 9 10 | |
次のコードでは,アフィン変換行列の設定パラメータを次のように指定しています.
- 変換軸座標: \((C_x, C_y) = (638.0, 389.0)\),おおよそ両肩の中心になる座標を指定しています.
- 平行移動量: \((T_x, T_y) = (100.0, 0.0)\)
- 拡大縮小量: \((S_x, S_y) = (2.0, 0.5)\)
- 回転量: \(R = \pi * 15.0 / 180.0\)
- せん断量: \((K_x, K_y) = \pi * (15.0, 15.0) / 180.0\)
回転量とせん断量はラジアンになってます.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
print処理の結果を示します.
Parameters
Center: [638. 389.]
Trans: [100. 0.]
Scale: [2. 0.5]
Rot: 0.2617993877991494
Skew: [0.26179939 0.26179939]
では,アフィン変換処理を実行していきます.
まず次のコードで処理時間計測クラスに入力するためのラッパー関数を定義します.
1 2 3 | |
次のコードは先程実装した変換処理にtrackdataを入力して,変換後の追跡点newtrackを得ています.
1回目の処理呼び出しでは,処理のコンパイルが行われるため個別に時間を計測し,参照用の変換後追跡点との誤差を計測しています.
その後,処理時間計測クラスを用いて平均処理時間を表示しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
print 処理の結果を示します.
1回目の処理時間は204.6ミリ秒程度で,誤差はほぼありませんでした.
2回目以降の処理では,(他のプロセスの影響が少ない場合は) 18.6ミリ秒程度で処理が完了しています.
Time of first call.
Overall summary: Max 204.563ms, Min 204.563ms, Mean +/- Std 204.563ms +/- 0s
Sum of error:0.0
Time after second call.
Overall summary: Max 43.2781ms, Min 18.1728ms, Mean +/- Std 20.6453ms +/- 3.22142ms
Top 10 summary: Max 18.8043ms, Min 18.1728ms, Mean +/- Std 18.5944ms +/- 168.285µs
入力データ形状が変わった場合の挙動
次に,入力データ形状が変わった場合の挙動を確認します.
Tensorflowで Graph mode を用いた場合の典型的な問題として,処理の再トレーシングが挙げられます.
これは,入力データの型や形状が変わった場合に処理のコンパイルが再度行われてしまう問題を指します.
処理の再トレーシングについての詳細は,公式ドキュメントをご参照ください.
Define-by-run で動かした場合や,入力データの型と形状を明示的に指定した場合では再トレーシングを回避することが可能です.
次のコードは先程の変換実行処理とほぼ同じですが,入力データの時間長が1フレーム分短くなっています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
print 処理の結果を示します.
1回目および2回目以降の処理時間は大きくは変わらず,Define-by-run で動かした場合は処理の再トレーシングは起きないことが分かります.
Time of first call.
Overall summary: Max 26.7066ms, Min 26.7066ms, Mean +/- Std 26.7066ms +/- 0s
Time after second call.
Overall summary: Max 86.6408ms, Min 22.0264ms, Mean +/- Std 40.6909ms +/- 13.1015ms
Top 10 summary: Max 28.081ms, Min 22.0264ms, Mean +/- Std 25.3254ms +/- 2.30584ms
4.2. Define-and-run に基づく実装
ここから先は,Define-and-run を用いた場合の挙動について見ていきます.
Tensorflowでは @tf.function デコレータで修飾した関数は Define-and-run で動作します.
今回は元々双方の動作モードで動くように変換処理を実装しているので,コードの変更はほとんどありません.
変換行列の算出処理
次のコードでは,先程紹介した変換行列処理関数を Define-and-run で動作するようにしています.
中身のコードは完全に同じなのでここでは説明を省かさせていただきます.
1 2 3 4 5 6 7 8 | |
アフィン変換の適用処理
次のコードは,追跡点配列に変換行列を適用する関数を実装しています.
この関数では,引数 inputs が信号長と追跡点数が事前に決定できません.
そのため単純に @tf.function デコレータでラップした場合は,入力形状が変化するたびに関数の再トレーシングが発生してしまいます.
再トレーシングを抑制するには,@tf.function デコレータの引数として型情報を明示的に与えてあげればよいです.
次のコードでは,@tf.function デコレータの input_signature 引数に対して, tf.TensorSpec() を与えています.
tf.TensorSpec() は入力のメタ情報を記述するためのクラスで,ここでは入力配列の形状と型を記述しています.
shape=[None, None, 4] の None は入力毎にサイズが変化する次元を示しています.
今回は時間軸と追跡点軸に対して None を指定しています.
また,mat に対しても tf.TensorSpec() を定義していますが,mat は形状が shape=[3, 3] であることが事前に決定できます.
中身のコードは完全に同じなのでここでは説明を省かさせていただきます.
1 2 3 4 5 | |
アフィン変換の実行
アフィン変換を実行します.
まず次のコードで処理時間計測クラスに入力するためのラッパー関数を定義します.
1 2 3 | |
次のコードで変換処理を実行しています.
先程と同じく,1回目の処理呼び出しでは,処理のコンパイルが行われるため個別に時間を計測し,2回目以降に処理時間計測クラスを用いて平均時間を表示しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
print 処理の結果を示します.
1回目の処理では895.8ミリ秒程度かかっていますが,2回目以降の処理では20.7ミリ秒程度で処理が完了していることが分かります.
Time of first call.
Overall summary: Max 895.778ms, Min 895.778ms, Mean +/- Std 895.778ms +/- 0s
Sum of error:0.0
Time after second call.
Overall summary: Max 73.0112ms, Min 16.8224ms, Mean +/- Std 29.15ms +/- 7.81842ms
Top 10 summary: Max 22.767ms, Min 16.8224ms, Mean +/- Std 20.7323ms +/- 1.64511ms
入力データ形状が変わった場合の挙動
次に,先程と同じく入力データの形状が変わった場合の挙動を示します.
次のコードは先程の変換実行処理とほぼ同じですが,入力データの時間長が1フレーム分短くなっています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
print 処理の結果を示します.
1回目の処理では82.4ミリ秒程度,2回目以降の処理では19.6ミリ秒程度で処理が完了しています.
Define-and-run で実行する際も入力データの型情報を明記することで再トレーシングを抑制することができることが分かります.
Time of first call.
Overall summary: Max 82.4818ms, Min 82.4818ms, Mean +/- Std 82.4818ms +/- 0s
Time after second call.
Overall summary: Max 69.1991ms, Min 17.3533ms, Mean +/- Std 30.7778ms +/- 8.9923ms
Top 10 summary: Max 22.3045ms, Min 17.3533ms, Mean +/- Std 19.5941ms +/- 1.71975ms
5. データ拡張用途として,ランダムな変換を行う方法
第5節では,アフィン変換をデータ拡張に応用する方法を紹介します.
処理の流れを図1に示します.
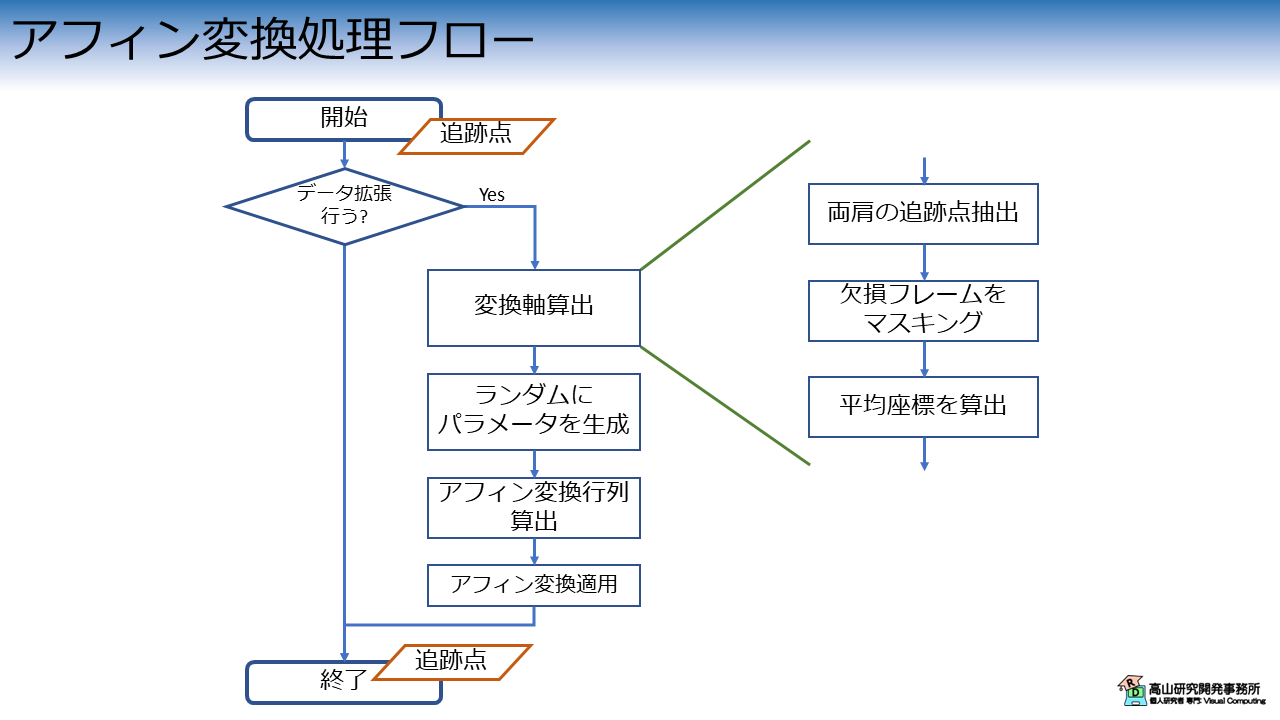
変換処理自体は,次の3個の処理から構成されます.
- 変換軸算出と変換パラメータの生成
- 変換行列の算出
- アフィン変換の適用
また,データ拡張に応用する場合は,変換を適用するかどうかを確率的に決める処理が入る場合が多いです.
今回はTensorflowを用いているので,より高速な動作が期待できる Define-and-run を用いた実装形態を紹介したいと思います.
具体的には,次の図2に示す2種類の実装形態を紹介します.
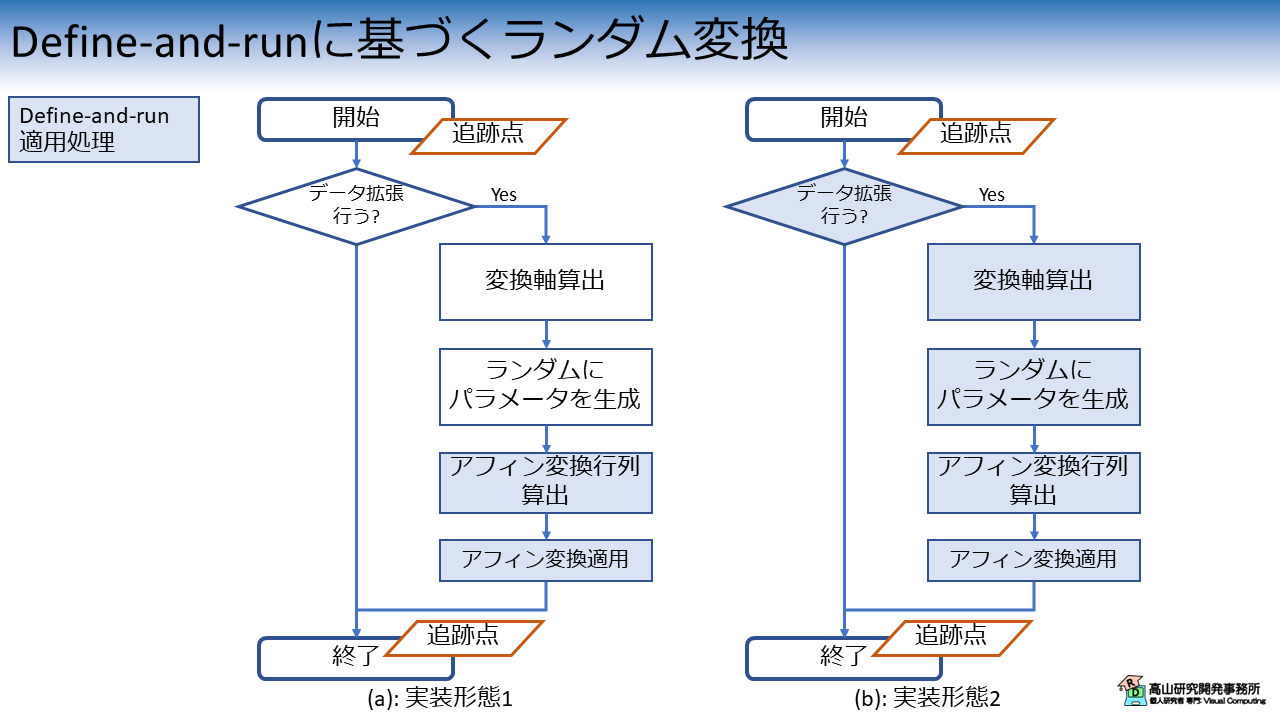
図2(a) に示す一つ目の実装形態では,全体の処理は通常のPythonプロセスを用いて組み,PythonプロセスからJITコンパイルをした関数を読み出します.
こちらの実装は比較的単純で,Numpy版の実装と同様の処理構成が維持できます.
図2(b) に示す2つ目の実装形態では,分岐やランダムパラメータの生成を含んだ処理全体をJITコンパイルします.
こちらの実装では,コンパイル可能な形に処理構成を変更する必要があります.
では,次項から具体的な処理を説明していきます.
5.1 実装形態1: PythonプロセスからJITコンパイルをした関数を呼び出す
データ拡張クラス
図2(a) に示した処理を実装したクラスが次のコードになります.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | |
- 引数
- center_joints: 変換軸座標算出に使用する追跡点インデクス.
ここで指定した追跡点の重心 (の全フレーム平均) が変換軸になります.
- apply_ratio: 変換を適用する確率,[0.0, 1.0]で指定
- trans_range: 平行移動量の範囲 `(minimum, maximum)`
- scale_range: 拡大縮小量の範囲 `(minimum, maximum)`
- rot_range: 回転量の範囲,度数で指定 `(minimum, maximum)`
- skew_range: せん断量の範囲,度数で指定 `(minimum, maximum)`
- random_seed: 疑似乱数生成器のシード,Noneの場合はNumpyのグローバル設定が用いられる
- dtype: 出力データ型
- 12-25行目: クラスのインスタンス化処理
22-25行目では疑似乱数生成器を生成しています.`random_seed` が指定されている場合は
その値を用いて生成し,`None` の場合はTensorflowのグローバル設定を用いるようにしています.
- 27-54行目: ランダム変換処理
- 28-29行目: 乱数を生成し,`apply_ratio` 以上だった場合は何もせずに値を返す
- 31-43行目: 変換軸を算出
まず初めに,`center_joints` で指定した追跡点配列を抽出します.
次に,欠損フレームを除去するための `mask` を生成します.
最後に,`mask` を適用した上で平均座標 (x, y) を算出し `center` としています.
Numpyとは異なり,TensorflowではBoolean配列を入力として部分配列を抽出することはできません.
そこで,37-41行目に示す処理で平均座標を算出しています.
- 45-48行目: 指定した範囲で各変換パラメータをランダムに生成
- 50行目: アフィン変換行列を算出
ここでは先程実装した `get_affine_matrix_2d_tf()` をクラスから呼び出すようにしています.
- 53行目: アフィン変換適用
ここでは先程実装した `apply_affine_tf` をクラスから呼び出すようにしています.
データ拡張処理の実行
必要な処理が実装できましたので,処理を適用してみます.
まず,次のコードで変換クラスをインスタンス化します.
1 2 3 4 5 6 7 8 | |
ここでは,center_joints に両肩の追跡点を指定しています.
この場合,変換軸は両肩の中央,つまり首元の座標になります.
次のコードでは,trackdata (のコピー) に対してランダムなパラメータで変換を施しています.
先程と同じく,1回目の処理呼び出しでは処理のコンパイルが行われるため個別に時間を計測し,2回目以降に処理時間計測クラスを用いて平均時間を表示しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
print 処理の結果を示します.
1回目の処理では532.9ミリ秒程度かかっていますが,2回目以降の処理では36.5ミリ秒程度で処理が完了していることが分かります.
Time of first call.
Overall summary: Max 532.927ms, Min 532.927ms, Mean +/- Std 532.927ms +/- 0s
Time after second call.
Overall summary: Max 131.862ms, Min 30.534ms, Mean +/- Std 54.5549ms +/- 20.7024ms
Top 10 summary: Max 39.0679ms, Min 30.534ms, Mean +/- Std 36.5016ms +/- 2.63933ms
入力データ形状が変わった場合の挙動
第4節と同じく入力データの形状が変わった場合の挙動を示します.
次のコードは上の変換実行処理とほぼ同じですが,入力データの時間長が1フレーム分短くなっています.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
print 処理の結果を示します.
1回目の処理は66.7ミリ秒程度で,2回目以降の処理では22.8ミリ秒程度でした.
第4節で示したとおり,JITコンパイルした関数は入力の型と形状を明示的に与えているので再トレースを抑制できています.
Time of first call.
Overall summary: Max 66.6588ms, Min 66.6588ms, Mean +/- Std 66.6588ms +/- 0s
Time after second call.
Overall summary: Max 126.075ms, Min 22.4291ms, Mean +/- Std 32.7429ms +/- 18.0349ms
Top 10 summary: Max 22.9823ms, Min 22.4291ms, Mean +/- Std 22.7506ms +/- 172.265µs
5.2 実装形態2: JITコンパイルを変換プロセス全体に適用
データ拡張クラス
次に,図2(b) に示した処理を実装したクラスを示します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | |
まず,__call__() を input_signature 付きの @tf.function デコレータでラップしています.
これにより処理全体を Define-and-run で動作させることが可能になります.
内部の処理の流れは概ね前項と同じですが,30行目で即座に関数を出ずに retval = inputs としている点に注意してください.
Define-and-run 適用時は if 文は tf.cond() 関数に変換されます.
そのため,30行目で return inputs とした場合は if ブロックと else ブロックで同種の値を返していない,としてエラーになります.
データ拡張処理の実行
必要な処理が実装できましたので,処理を適用してみます.
まず,前項と同様に次のコードで変換クラスをインスタンス化します.
1 2 3 4 5 6 7 8 | |
次のコードでは,trackdata (のコピー) に対してランダムなパラメータで変換を施しています.
前項と同じく,1回目の処理呼び出しでは処理のコンパイルが行われるため個別に時間を計測し,2回目以降に同じ処理を10回適用して平均時間を表示しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
print 処理の結果を示します.
1回目の処理では409.1ミリ秒程度で,2回目以降の処理では22.2ミリ秒程度でした.
処理全体をコンパイルした結果か,傾向としてはわずかに速度が向上しているように見えます.
Time of first call.
Overall summary: Max 409.075ms, Min 409.075ms, Mean +/- Std 409.075ms +/- 0s
Time after second call.
Overall summary: Max 28.6829ms, Min 17.5935ms, Mean +/- Std 24.8284ms +/- 1.49898ms
Top 10 summary: Max 24.0776ms, Min 17.5935ms, Mean +/- Std 22.1906ms +/- 2.34517ms
入力データ形状が変わった場合の挙動
前項と同じく入力データの形状が変わった場合の挙動を示します.
次のコードは上の変換実行処理とほぼ同じですが,入力データの時間長が1フレーム分短くなっています.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
print 処理の結果を示します.
1回目の処理は16.3ミリ秒程度で,2回目以降の処理では13.5ミリ秒程度でした.
第4節の例と同様に,JITコンパイルした関数は入力の型と形状を明示的に与えているので再トレースを抑制できています.
Time of first call.
Overall summary: Max 16.2957ms, Min 16.2957ms, Mean +/- Std 16.2957ms +/- 0s
Time after second call.
Overall summary: Max 20.75ms, Min 13.231ms, Mean +/- Std 14.4953ms +/- 1.39201ms
Top 10 summary: Max 13.628ms, Min 13.231ms, Mean +/- Std 13.4536ms +/- 126.572µs
今回はアフィン変換処理をTensorflowで実装する方法を紹介しましたが,如何でしょうか?
Tensorflowに限らず Define-and-run を用いた実装はつまずく箇所が多いですが,高速化の恩恵を受けられる場合が多いです.
学習時などの前処理で時間がかかっている場合は,Define-and-run の実装を試してみると改善するかもしれません.
今回紹介した話が,動作認識のデータ拡張などでお悩みの方に何か参考になれば幸いです.