defprint_perf_time(intervals,top_k=None):iftop_kisnotNone:intervals=np.sort(intervals)[:top_k]min=intervals.min()max=intervals.max()mean=intervals.mean()std=intervals.std()smin=get_perf_str(min)smax=get_perf_str(max)mean=get_perf_str(mean)std=get_perf_str(std)iftop_k:print(f"Top {top_k} summary: Max {smax}, Min {smin}, Mean +/- Std {mean} +/- {std}")else:print(f"Overall summary: Max {smax}, Min {smin}, Mean +/- Std {mean} +/- {std}")
defget_affine_matrix_2d_torch(center,trans,scale,rot,skew,dtype=torch.float32):device=center.devicecenter_m=torch.tensor([[1.0,0.0,float(-center[0])],[0.0,1.0,float(-center[1])],[0.0,0.0,1.0]],dtype=dtype,device=device)scale_m=torch.tensor([[float(scale[0]),0.0,0.0],[0.0,float(scale[1]),0.0],[0.0,0.0,1.0]],dtype=dtype,device=device)_cos=torch.cos(rot)_sin=torch.sin(rot)rot_m=torch.tensor([[float(_cos),float(-_sin),0.0],[float(_sin),float(_cos),0.0],[0.0,0.0,1.0]],dtype=dtype,device=device)_tan=torch.tan(skew)skew_m=torch.tensor([[1.0,float(_tan[0]),0.0],[float(_tan[1]),1.0,0.0],[0.0,0.0,1.0]],dtype=dtype,device=device)move=center+transtrans_m=torch.tensor([[1.0,0.0,float(move[0])],[0.0,1.0,float(move[1])],[0.0,0.0,1.0]],dtype=dtype,device=device)# Make affine matrix.mat=torch.eye(3,3,dtype=dtype,device=device)mat=torch.matmul(center_m,mat)mat=torch.matmul(scale_m,mat)mat=torch.matmul(rot_m,mat)mat=torch.matmul(skew_m,mat)mat=torch.matmul(trans_m,mat)returnmat.to(dtype)
# Get affine matrix.center=torch.tensor([638.0,389.0]).to(DEVICE)trans=torch.tensor([100.0,0.0]).to(DEVICE)scale=torch.tensor([2.0,0.5]).to(DEVICE)rot=torch.tensor(np.radians(15.0)).to(DEVICE)skew=torch.tensor(np.radians([15.0,15.0])).to(DEVICE)dtype=torch.float32print("Parameters")print("Center:",center)print("Trans:",trans)print("Scale:",scale)print("Rot:",rot)print("Skew:",skew)
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()mat=get_affine_matrix_2d_torch(center,trans,scale,rot,skew,dtype=dtype)newtrack=apply_affine_torch(testtrack,mat)interval=time.perf_counter()-startprint_perf_time(np.array([interval]))# Evaluate difference.diff=(np.round(newtrack.detach().cpu().numpy())-np.round(refdata)).sum()print(f"Sum of error:{diff}")testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(perf_wrap_func,trackdata=testtrack,center=center,trans=trans,scale=scale,rot=rot,skew=skew,dtype=dtype)pmeasure(target_fn)
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()mat=get_affine_matrix_2d_torch(center,trans,scale,rot,skew,dtype=dtype)newtrack=apply_affine_torch(testtrack[:-1],mat)interval=time.perf_counter()-startprint_perf_time(np.array([interval]))testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(perf_wrap_func,trackdata=testtrack[:-1],center=center,trans=trans,scale=scale,rot=rot,skew=skew,dtype=dtype)pmeasure(target_fn)
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)withtorch.jit.optimized_execution(JIT_OPT):# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()mat=get_affine_matrix_2d_torch_jit(center,trans,scale,rot,skew,dtype=dtype)newtrack=apply_affine_torch_jit(testtrack,mat)interval=time.perf_counter()-startprint_perf_time(np.array([interval]))# Evaluate difference.diff=(np.round(newtrack.detach().cpu().numpy())-np.round(refdata)).sum()print(f"Sum of error:{diff}")testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(perf_wrap_func,trackdata=testtrack,center=center,trans=trans,scale=scale,rot=rot,skew=skew,dtype=dtype)pmeasure(target_fn)
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)withtorch.jit.optimized_execution(JIT_OPT):# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()mat=get_affine_matrix_2d_torch_jit(center,trans,scale,rot,skew,dtype=dtype)newtrack=apply_affine_torch_jit(testtrack[:-1],mat)interval=time.perf_counter()-startprint_perf_time(np.array([interval]))# Evaluate difference.diff=(np.round(newtrack.detach().cpu().numpy())-np.round(refdata[:-1])).sum()print(f"Sum of error:{diff}")testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(perf_wrap_func,trackdata=testtrack[:-1],center=center,trans=trans,scale=scale,rot=rot,skew=skew,dtype=dtype)pmeasure(target_fn)
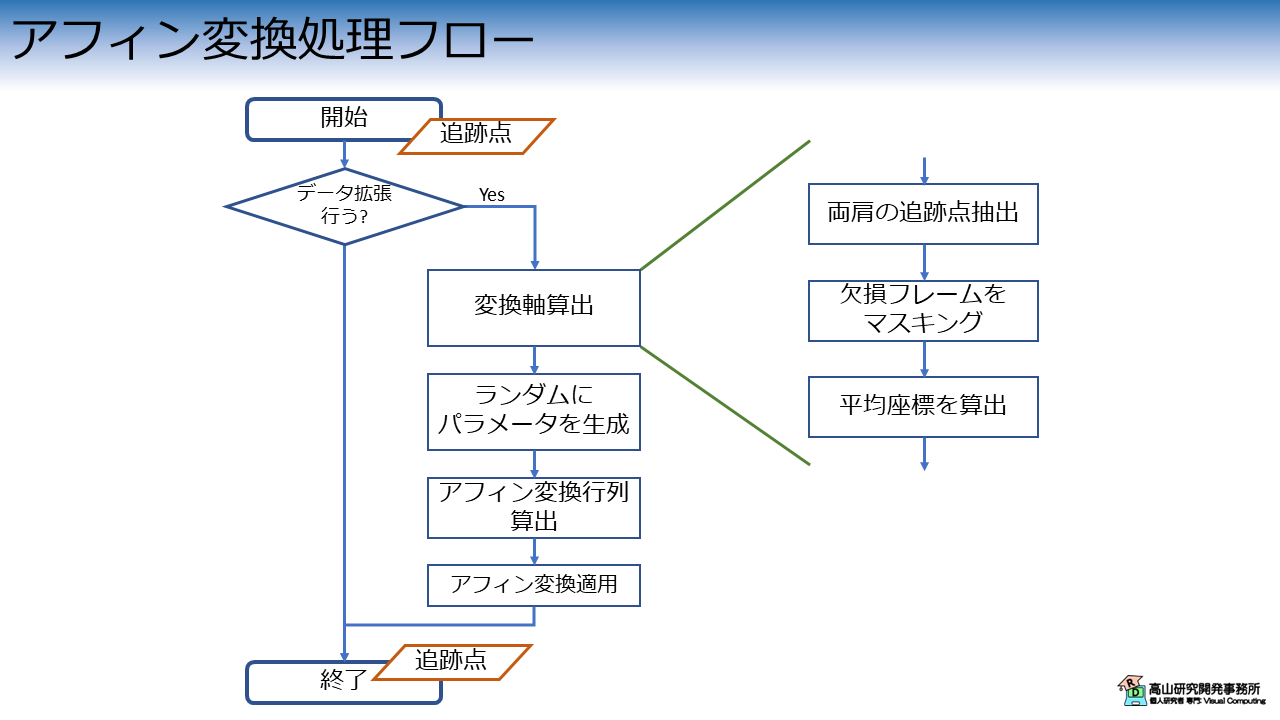
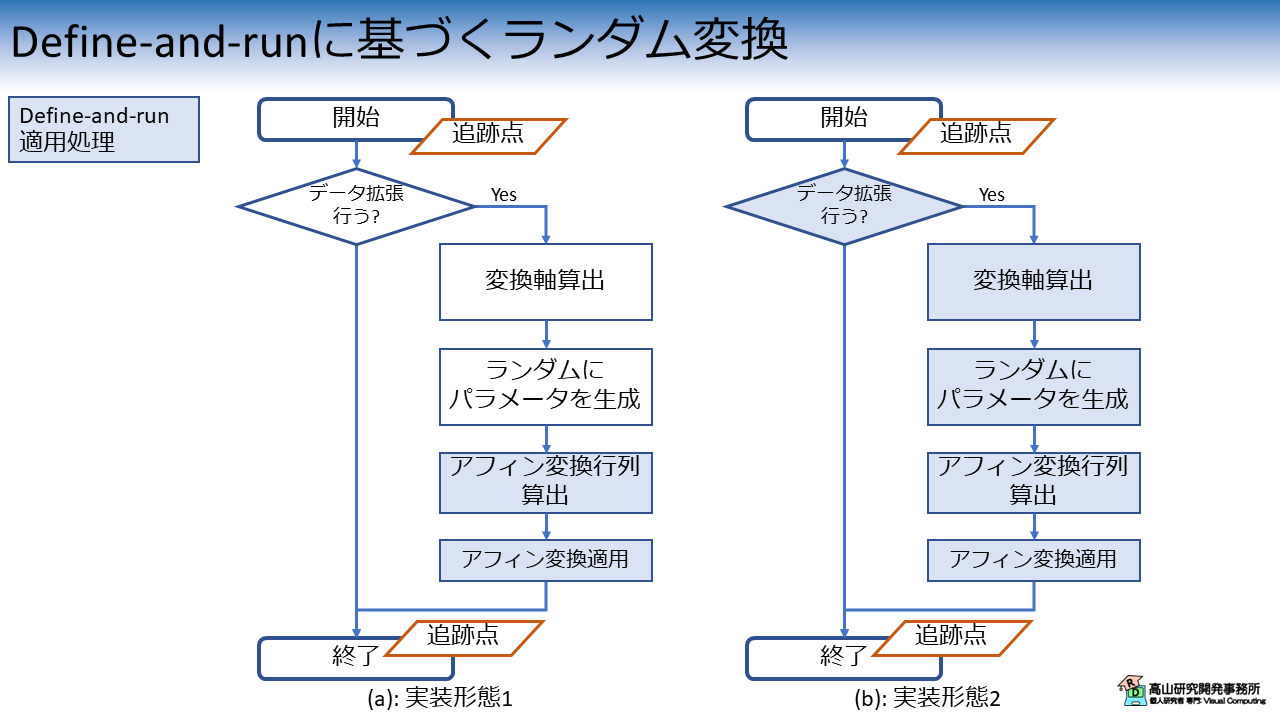
classRandomAffineTransform2D_Torch():def__init__(self,center_joints,apply_ratio,trans_range,scale_range,rot_range,skew_range,random_seed=None,device="cpu",dtype=torch.float32):self.center_joints=center_jointsifisinstance(self.center_joints,int):self.center_joints=[self.center_joints]self.apply_ratio=apply_ratioself.trans_range=trans_rangeself.scale_range=scale_rangeself.rot_range=np.radians(rot_range).tolist()self.skew_range=np.radians(skew_range).tolist()self.dtype=dtypeself.device=deviceself.rng=torch.Generator(device=device)ifrandom_seedisnotNone:self.rng.manual_seed(random_seed)def__call__(self,inputs):iftorch.rand(1,generator=self.rng,device=self.device)>=self.apply_ratio:returninputstemp=inputs[:,self.center_joints,:]temp=temp.reshape([inputs.shape[0],-1,inputs.shape[-1]])mask=temp.sum(dim=(1,2))!=0# Use x and y only.center=temp[mask].mean(dim=0).mean(dim=0)[:2]# Random value in [0, 1].trans=torch.rand(2,generator=self.rng,device=self.device)scale=torch.rand(2,generator=self.rng,device=self.device)rot=torch.rand(1,generator=self.rng,device=self.device)skew=torch.rand(2,generator=self.rng,device=self.device)# Scale to target range.trans=(self.trans_range[1]-self.trans_range[0])*trans+self.trans_range[0]scale=(self.scale_range[1]-self.scale_range[0])*scale+self.scale_range[0]rot=(self.rot_range[1]-self.rot_range[0])*rot+self.rot_range[0]skew=(self.skew_range[1]-self.skew_range[0])*skew+self.skew_range[0]# Calculate matrix.mat=get_affine_matrix_2d_torch_jit(center,trans,scale,rot,skew,dtype=self.dtype)# Apply transform.inputs=apply_affine_torch_jit(inputs,mat)returninputs
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)withtorch.jit.optimized_execution(JIT_OPT):# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()temp=aug_fn(testtrack)interval=time.perf_counter()-startprint_perf_time(np.array([interval]))testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(aug_fn,inputs=testtrack)pmeasure(target_fn)
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)withtorch.jit.optimized_execution(JIT_OPT):# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()temp=aug_fn(testtrack[:-1])interval=time.perf_counter()-startprint_perf_time(np.array([interval]))testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(aug_fn,inputs=testtrack[:-1])pmeasure(target_fn)
classRandomAffineTransform2D_TorchModule(nn.Module):def__init__(self,center_joints,apply_ratio,trans_range,scale_range,rot_range,skew_range,random_seed=None,device="cpu",dtype=torch.float32):super().__init__()self.center_joints=center_jointsifisinstance(self.center_joints,int):self.center_joints=[self.center_joints]self.apply_ratio=apply_ratioself.trans_range=trans_rangeself.scale_range=scale_rangeself.rot_range=np.radians(rot_range).tolist()self.skew_range=np.radians(skew_range).tolist()self.dtype=dtypeself.device=device# self.rng = torch.Generator(device=device)# if random_seed is not None:# self.rng.manual_seed(random_seed)self.rng=Nonedefforward(self,inputs):iftorch.rand(1,generator=self.rng,device=self.device)>=self.apply_ratio:returninputstemp=inputs[:,self.center_joints,:]temp=temp.reshape([inputs.shape[0],-1,inputs.shape[-1]])mask=temp.sum(dim=(1,2))!=0# Use x and y only.center=temp[mask].mean(dim=0).mean(dim=0)[:2]# Random value in [0, 1].trans=torch.rand(2,generator=self.rng,device=self.device)scale=torch.rand(2,generator=self.rng,device=self.device)rot=torch.rand(1,generator=self.rng,device=self.device)skew=torch.rand(2,generator=self.rng,device=self.device)# Scale to target range.trans=(self.trans_range[1]-self.trans_range[0])*trans+self.trans_range[0]scale=(self.scale_range[1]-self.scale_range[0])*scale+self.scale_range[0]rot=(self.rot_range[1]-self.rot_range[0])*rot+self.rot_range[0]skew=(self.skew_range[1]-self.skew_range[0])*skew+self.skew_range[0]# Calculate matrix.mat=get_affine_matrix_2d_torch_jit(center,trans,scale,rot,skew,dtype=self.dtype)# Apply transform.inputs=apply_affine_torch_jit(inputs,mat)returninputs
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)withtorch.jit.optimized_execution(JIT_OPT):# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()temp=aug_fn(testtrack)interval=time.perf_counter()-startprint_perf_time(np.array([interval]))testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(aug_fn,inputs=testtrack)pmeasure(target_fn)
testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)withtorch.jit.optimized_execution(JIT_OPT):# The 1st call may be slow because of the computation graph construction.print(f"Time of first call.")start=time.perf_counter()temp=aug_fn(testtrack[:-1])interval=time.perf_counter()-startprint_perf_time(np.array([interval]))testtrack=torch.tensor(trackdata.copy().astype(np.float32)).to(DEVICE)print("Time after second call.")target_fn=partial(aug_fn,inputs=testtrack[:-1])pmeasure(target_fn)