目次
こんにちは.高山です.
以前の記事で,アフィン変換を用いて骨格追跡点を変形する方法を紹介しました.
今回は,Pythonの行列演算用ライブラリNumpyを用いてアフィン変換を実装する方法を紹介します.
動作認識の分野では,アフィン変換はデータを変形して学習データを水増しする,所謂データ拡張としてよく用いられます.
本記事の後半では,アフィン変換のパラメータをランダムに変更することでデータ拡張を行う方法も紹介していますので,ご一読いただければ幸いです.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/17: タイトル,タグ,サマリを更新しました
- 2023/10/30: 処理時間の計測方法を更新しました
1. モジュールのインストールとロード
第1節ではモジュールのインストールとロードを行います.
第1節と第2節では入力データを確認するために,全身追跡で紹介した内容と同様の処理を行っています.
アフィン変換の具体的な処理については第4節から説明しますのでそちらから読み進めていただいても構いません.
1.1 MediaPipeのインストール
追跡点の描画のために,MediaPipeから追跡点接続関係の定義をインポートします.
初期状態のColab環境にはMediaPipeがインストールされていませんので,Colab環境にMediaPipeをインストールします.
Colab環境では,先頭に"!"付けるとその行はShellコマンドとみなされます.
下のコードでは,Pythonのパッケージ管理ツール pip を呼び出してMediaPipeのバージョン"0.10.0"をインストールしています.
!pip3 install mediapipe==0.10.0
1.2 利用モジュールのインポート
次のコードでは使用するモジュールをインポートしています.
この操作によって,各モジュールに実装されている機能を利用できるようになります.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
【コード解説】
- 標準モジュール
- gc: ガベージコレクション用ライブラリ
処理時間計測クラスの内部処理で用います.
- sys: Pythonシステムを扱うライブラリ
今回はバージョン情報を取得するために使用しています.
- time: 時刻データを取り扱うためのライブラリ
今回は処理時間を計測するために使用しています.
- functools: 関数オブジェクトを操作するためのライブラリ
処理時間計測クラスに渡す関数オブジェクト作成に使用しています.
- pathlib: オブジェクト指向のファイルパスクラス.ファイルの作成・削除操作のために使用
- 画像処理・機械学習向けモジュール
- cv: 画像処理ライブラリOpenCVのPython版
- numpy: 行列演算ライブラリ
- 描画処理向けモジュール
- FACEMESH_CONTOURS: MediaPipe向け顔追跡点の接続関係を定義したデータ
- HAND_CONNECTIONS: MediaPipe向け手追跡点の接続関係を定義したデータ
- POSE_CONNECTIONS: MediaPipe向け身体追跡点の接続関係を定義したデータ
- HTML: 生データをロードしてHTML形式に変換する機能.今回は動画を描画するために使用
- b64encode: データをbase64形式に変換する機能.
base64はデータをアルファベット,数字,記号の64文字で表すデータ形式
- io: データやファイルに対する入出力機能.標準モジュールだが今回は動画を読み込むために使用
記事執筆時点のPythonと主要モジュールのバージョンは下記のとおりです.
1 2 3 | |
Python:3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0]
OpenCV:4.8.0
Numpy:1.23.5
2. データのロードと確認
2.1 データのダウンロード
第2節では,変換前の追跡点データをダウンロードしています.
!wget https://github.com/takayama-rado/trado_samples/raw/main/test_data/finger_far0_non_static.npy
ls コマンドでデータがダウンロードされているか確認します.
!ls
finger_far0_non_static.npy sample_data
2.2 追跡点を描画して確認
追跡点の描画処理
まずは,変換前の追跡点を描画して確認してみます.
次のコードは,描画ウィンドウに対して追跡点を描画しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
【コード解説】
- 引数
- draw: 描画領域.背景は既に描画済みの想定です.
- landmarks: 追跡点配列
- connections: 追跡点間の接続関係
接続関係は `[[0, 1], [1, 2], ...]` のように追跡点インデクスのペアの配列になっています.
- pt_color: 追跡点の描画色 (BGR)形式
- line_color: 追跡点間の描画色 (BGR)形式
- pt_size: 追跡点の描画サイズ
- line_size: 追跡点間の描画サイズ
- do_remove_error: `True` の場合,追跡に失敗している点は無視する
- 5-7行目: 追跡点間の接続関係と,対応関係になっている2点を抽出
追跡点の描画には $(x, y)$ 座標だけを用います.
- 8-12行目: 追跡に失敗した点をスキップ
`Nan` や座標値が `0` になっている場合は描画をスキップします.
- 13-17行目: 追跡点の接続関係を直線で描画し,追跡点を円で描画しています.
追跡点描画のメイン処理
次のコードは,描画メイン処理を実装しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | |
【コード解説】
- 引数:
- videofile: 入力動画のパス.動画は背景画像を描画するために用います.
- trackfile: 追跡データファイルのパス
- outvideo: 結果動画の出力パス
- 2-11行目: 追跡点ファイルと動画ファイルをロード
動画ファイルのオープンに成功した場合は,読み込み位置を先頭フレームに設定し,画像幅と画像高さを読み込みます.
- 13-23行目: 追跡点座標の最大値と最小値を算出
この値はウィンドウサイズと描画位置の調整に用います.
また,先の追跡処理でスケーリングをしていない場合は,19-21行目で再度スケーリングを行います.
- 25-39行目: ウィンドウサイズと描画位置の調整
この処理によって追跡点座標が負の値や画面外の値になっている場合でも描画できるようになります.
- 41-47行目: 出力用の動画ファイルをオープン
オープンに失敗した場合は例外を投げて中断します.
- 50-76行目: メインループ
- 50行目: 時間次元に沿ってループ処理を行うために,追跡点配列の第1次元と第2次元を入れ替え
- 52-61行目: 画像フレームを読み込み,背景を描画
入力動画をオープンしていない場合は白背景を設定します.
- 63行目: 人物毎に追跡点を描画
全身追跡モードは複数名の追跡に未対応なためここでのループは不要なのですが,他の追跡処理と互換性をもたせるためにこのような処理になっています.
- 64-75行目: 部位毎に追跡点を描画
追跡点の接続関係は部位毎に定義されているため,一旦追跡点を部位毎に分割して,それぞれ異なる色で描画しています.
- 76行目: 描画フレームを動画ファイルに書き出し
- 77-79行目: 動画の保存および終了処理
次のコードはColab上で動画を描画する機能を実装しています.
1 2 3 4 5 6 7 8 | |
【コード解説】
- 引数
- video_path: 入力動画のパス
- video_width: 動画表示領域の幅
- video_height: 動画表示領域の高さ
- 2行目: 動画ファイルをオープン
- 3-4行目: 生データを一旦base64形式に変換し,さらにASCII文字列に変換
- 5-7行目: HTMLのvideoタグを表す文字列を定義
- 8行目: dataをHTML形式に変換して返す
追跡点描画の実行
次のコードで追跡データを描画しています.
この処理は特に難しいことはなく,最初に引数を設定して描画関数に渡しているだけです.
drawing() の第1引数には背景となる動画ファイルを指定しますが,今回は空文字を指定して背景が白地になるようにしています.
1 2 3 4 | |
描画結果を表示して確認をします.
OpenCVを使って作成した動画ファイルはColab環境上では上手く表示できなかったため,FFMPEGを使用して変換を行います.
!ffmpeg -i finger_far0_track_orig.mp4 -vcodec vp9 -y finger_far0_track_orig.webm
その後,次のコードで動画ファイルの描画を行います.
show_video() の返り値はHTMLオブジェクトのため(videoタグ),埋め込み動画が表示されます.
show_video(outvideo.stem + ".webm")
3. 実験用処理の実装
実験に先立って,処理時間計測用の関数と実験用定数を定義します.
次のコードは処理時間の値から,適切なSI接頭辞を設定し,文字列にして返します.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
- 引数
- val: 処理時間を示す値 (秒)
- 2-6行目: 変数の初期化
- 7-11行目: 接頭辞を選択して,表示値を調整
- 12行目: 表示文字列を作成
次のコードは,処理時間を格納した配列から統計量を求めて表示します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
- 引数:
- intervals: 処理時間のNumpy配列
- top_k: intervalsから,処理時間が短いサンプルをk個取り出して統計量を算出
- 2-3行目: Top K個のサンプル抽出
- 4-7行目: 統計量算出
- 9-16行目: 表示文字列を作成して表示
次のクラスは,入力した関数を複数回呼び出して,処理時間の統計量を表示します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
- 引数:
- trials: 入力関数の実行回数
- top_k: 値が定義されている場合,全体の処理時間配列から処理時間が短いサンプルをk個取り出して統計量を算出
- 9-10行目: 計測中はガベージコレクションをしないように設定
- 11-20行目: 処理時間計測処理
- 21-22行目: ガベージコレクションの設定を元に戻す
最後に,次のコードで実験用の定数を定義して処理時間計測クラスをインスタンス化しています.
1 2 3 | |
実際の所,Colabの様な複雑な処理環境で他のプロセスの影響を排除して純粋な処理時間を計測するのはかなり難しいです.
そこでここでは,処理の繰り返し数を \(100\) とし全体の統計量に加えて,処理時間の短い代表値 \(10\) 試行からも統計量を表示するようにしています.
4. アフィン変換の実装
第4節では,アフィン変換の実装方法を紹介します.
以前の記事の後半で紹介した,対象物内の特定位置を変換軸とする変換を今回は実装していきます.
変換行列の算出処理
次のコードは,入力パラメータに応じた変換行列を算出する関数を実装しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | |
- 引数
- center: 変換軸座標 `(center_x, center_y)`
通常は物体中心位置や特定の追跡点位置を指定します.
- trans: 平行移動量 `(trans_x, trans_y)`
- scale: 拡大縮小量 `(scale_x, scale_y)`
- rot: 回転量
この値のみスカラーです.
- skew: せん断量 `(skew_x, skew_y)`
- to_radians: `True`の場合,内部で`rot`と`skew`をラジアンに変換します.
この設定の場合は,`rot`と`skew`は度数で指定する必要があります.
逆に,`False`の場合は,`rot`と`skew`はラジアンで指定する必要があります.
- order: 変換の適用順番
デフォルトでは,物体中心を原点に移動 -> 拡大縮小 -> 回転 -> せん断 -> 平行移動
の順で変換が適用されます.
- dtype: 出力データ型
- 9-11行目: 処理を簡単にするために,引数の型をnp.array型で統一 (`rot`と`skew`は内部処理の過程で変換される)
- 12-31行目: 各変換行列を算出
`center_m` の算出では,指定座標を原点に移動するためにマイナスをかけた値を移動量として設定しています.
回転とせん断はラジアン値を入力として,それぞれ対応する三角関数を適用した値を設定しています.
平行移動では,最初に行う指定座標の原点への移動をオフセットとして加えた値を移動量として設定しています.
- 32-43行目: 初めに`mat` を単位行列で初期化し,`order` で指定した順番で変換行列を適用
- 44行目: `dtype` で指定した型に変換して値を返す
アフィン変換の適用処理
次のコードは,追跡点配列に変換行列を適用する関数を実装しています.
1 2 3 4 5 6 | |
- 引数:
- inputs: 追跡点配列 `[T, J, C]`
- T: 動画フレームインデクス
- J: 追跡点インデクス
- C: 特徴量インデクス.今回は $(x, y, z, c)$ の4次元特徴量を用いています.
- mat: アフィン変換行列 `[3, 3]`
- 2-3行目: 追跡点配列から $(x, y)$ 座標列を取り出して,特徴量次元の末尾に $1$ を加えて同次座標形式に変換
- 4行目: `xy` の特徴量次元に対してアフィン変換行列を適用
- 5行目: 変換後の$(x, y)$ 座標列を `inputs` に代入して返す
4行目の変換行列の適用では,アインシュタインの縮約表記を用いた演算を行っています.
for文で \(T, J\) 軸に沿って値を取り出して計算するのは理解しやすいのですが,Pythonのループ処理は一般的に遅いです.
また,他のライブラリ (TensorflowやTorchなど) では同様の実装ができない場合があります (特にDefine-and-run適用時).
上記の理由から,ここでは他のライブラリと処理が統一できる np.einsum() を用いて実装しています.
と言っても,アインシュタインの縮約表記に関しては馴染みの無い方が多い (私は初めて見たとき何だこりゃ? となりました) と思います.
こちらに簡単な解説記事を用意しましたので,ご一読いただければうれしいです.
アフィン変換の実行
次のコードでは,追跡点を trackdata にロードして,関数の仕様に合わせて形状を変更しています.
今回用いるデータは [P, T, J, C] 形状 ( P は人物インデクス) の配列ですが,動画に映っている人物は1名だけですので P 軸は除去しています.
1 2 3 4 5 6 | |
次のコードでは,アフィン変換行列の設定パラメータを次のように指定し,変換行列を計算しています.
- 変換軸座標: \((C_x, C_y) = (638.0, 389.0)\),おおよそ両肩の中心になる座標を指定しています.
- 平行移動量: \((T_x, T_y) = (100.0, 0.0)\)
- 拡大縮小量: \((S_x, S_y) = (2.0, 0.5)\)
- 回転量: \(R = 15.0^{\circ}\)
- せん断量: \((K_x, K_y) = (15.0^{\circ}, 15.0^{\circ})\)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
print処理の結果を示します.
Parameters
Center: (638.0, 389.0)
Trans: (100.0, 0.0)
Scale: (2.0, 0.5)
Rot: 15.0
Skew: (15.0, 15.0)
Affine matrix: [[ 2.07055236e+00 9.69385328e-18 -5.83012406e+02]
[ 1.03527618e+00 4.48287736e-01 -4.45890132e+02]
[ 0.00000000e+00 0.00000000e+00 1.00000000e+00]]
変換行列が計算できましたので,追跡点配列に適用します.
次のコードでは,追跡点配列にアフィン変換を適用して,描画関数の仕様に合わせて形状を調整した上で保存しています.
1 2 3 4 5 6 7 8 | |
動画に描画して確認
変換ができましたので,動画に書き出して確認したいと思います.
第2節の処理と同じく,次のコードで変換後の追跡点配列を描画して動画ファイルに保存します.
1 2 3 4 | |
第2節の処理と同じく,Colab上で表示できるように動画ファイルを変換します.
!ffmpeg -i newtrack.mp4 -vcodec vp9 -y newtrack.webm
その後,次のコードで動画ファイルの描画を行います.
show_video(outvideo.stem + ".webm")
最後に,アフィン変換にかかる処理時間を示します.
まず次のコードで処理時間計測クラスに入力するためのラッパー関数を定義します.
1 2 3 | |
次のコードで処理時間を計測します.
1 2 3 4 5 6 | |
最初に,partial() でperf_wrap_func() に入力を指定して関数オブジェクトにしています.
次に,上で実装した処理時間計測クラスに関数オブジェクトを渡して処理時間を計測しています.
print処理の結果を示します.
(他のプロセスの影響が少ない場合は) アフィン変換は平均して3.1ミリ秒程度かかることが分かります.
Overall summary: Max 6.54465ms, Min 2.99026ms, Mean +/- Std 3.77009ms +/- 967.613µs
Top 10 summary: Max 3.18122ms, Min 2.99026ms, Mean +/- Std 3.12526ms +/- 55.0925µs
5. データ拡張用途として,ランダムな変換を行う方法
第4節では,アフィン変換をデータ拡張に応用する方法を紹介します.
処理の流れを図1に示します.
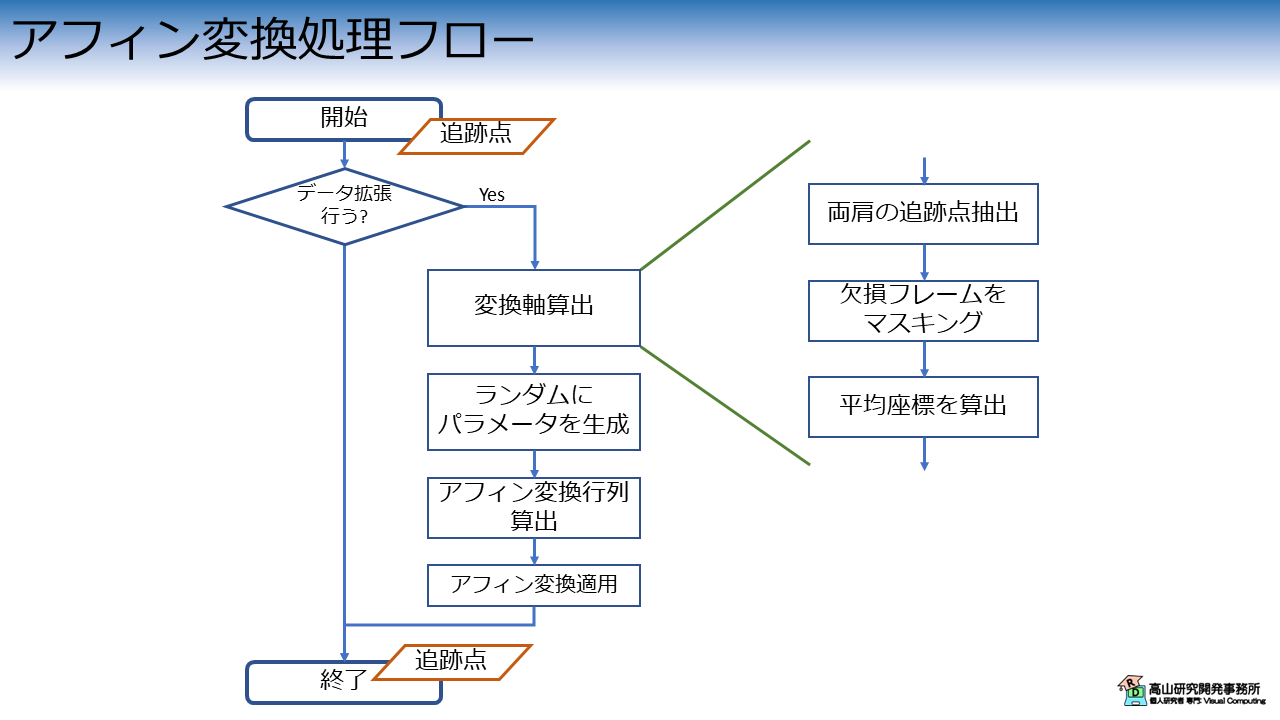
変換処理自体は,次の3個の処理から構成されます.
- 変換軸算出と変換パラメータの生成
- 変換行列の算出
- アフィン変換の適用
また,データ拡張に応用する場合は,変換を適用するかどうかを確率的に決める処理が入る場合が多いです.
データ拡張クラス
上で述べた説明を基に,処理を実装したクラスが次のコードになります.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
- 引数
- center_joints: 変換軸座標算出に使用する追跡点インデクス.
ここで指定した追跡点の重心 (の全フレーム平均) が変換軸になります.
- apply_ratio: 変換を適用する確率,[0.0, 1.0]で指定
- trans_range: 平行移動量の範囲 `(minimum, maximum)`
- scale_range: 拡大縮小量の範囲 `(minimum, maximum)`
- rot_range: 回転量の範囲,度数で指定 `(minimum, maximum)`
- skew_range: せん断量の範囲,度数で指定 `(minimum, maximum)`
- random_seed: 疑似乱数生成器のシード,Noneの場合はNumpyのグローバル設定が用いられる
- order: 変換の適用順番
デフォルトでは,物体中心を原点に移動 -> 拡大縮小 -> 回転 -> せん断 -> 平行移動
の順で変換が適用されます.
- dtype: 出力データ型
- 12-23行目: クラスのインスタンス化処理
20-23行目では疑似乱数生成器を生成しています.`random_seed` が指定されている場合は
その値を用いて生成し,`None` の場合はNumpyのグローバル設定を用いるようにしています.
- 25-47行目: ランダム変換処理
- 26-27行目: 乱数を生成し,`apply_ratio` 以上だった場合は何もせずに値を返す
- 29-34行目: 変換軸を算出
まず初めに,`center_joints` で指定した追跡点配列を抽出します.
次に,欠損フレームを除去するための `mask` を生成します.
最後に,`mask` を適用した上で平均座標 (x, y) を算出し `center` としています.
- 36-39行目: 指定した範囲で各変換パラメータをランダムに生成
- 42-43行目: アフィン変換行列を算出
ここでは先程実装した `get_affine_matrix_2d()` をクラスから呼び出すようにしています.
- 46行目: アフィン変換適用
ここでは先程実装した `apply_affine` をクラスから呼び出すようにしています.
データ拡張処理の実行
必要な処理が実装できましたので,処理を適用してみます.
まず,次のコードで変換クラスをインスタンス化します.
1 2 3 4 5 6 7 | |
ここでは,center_joints に両肩の追跡点を指定しています.
この場合,変換軸は両肩の中央,つまり首元の座標になります.
次のコードでは,trackdata (のコピー) に対して変換を施して,augtracks に格納しています.
1 2 3 | |
動画に描画して確認
変換ができましたので,動画に書き出して確認したいと思います.
第2節の処理と同じく,次のコードで変換後の追跡点配列を描画して動画ファイルに保存します.
1 2 3 4 5 6 7 8 | |
第2節の処理と同じく,Colab上で表示できるように動画ファイルを変換します.
!ffmpeg -i newtrack_0.mp4 -vcodec vp9 -y newtrack_0.webm
!ffmpeg -i newtrack_1.mp4 -vcodec vp9 -y newtrack_1.webm
!ffmpeg -i newtrack_2.mp4 -vcodec vp9 -y newtrack_2.webm
その後,次のコードで動画ファイルの描画を行います.
Colab上で動かすと,それぞれ異なった変換がされていることが確認できると思います.
show_video("./newtrack_0.webm")
show_video("./newtrack_1.webm")
show_video("./newtrack_2.webm")
処理時間の計測
最後に,次のコードで処理時間を計測します.
1 2 3 | |
print処理の結果を示します.
Overall summary: Max 91.7504ms, Min 22.5217ms, Mean +/- Std 42.0113ms +/- 17.8009ms
Top 10 summary: Max 24.1266ms, Min 22.5217ms, Mean +/- Std 23.4392ms +/- 571µs
(他のプロセスの影響が少ない場合は) データ拡張は平均して23.4ミリ秒程度かかることが分かります.
今回はNumpyを用いてアフィン変換を追跡点配列に適用するプログラムの解説を行いましたが,如何でしょうか?
アフィン変換を用いた追跡点配列の変形は,動作認識分野ではデータ拡張としてよく用いられます.
また,アフィン変換はコンピュータグラフィックス分野でもよく用いられる手法ですので,身につけておくとどこかで役に立つ可能性は高いと思います.
今回紹介した話が,動作認識のデータ拡張などでお悩みの方に何か参考になれば幸いです.