
目次
こんにちは.高山です.
先日の記事で告知しました手話入門記事の第四回になります.
今回は,孤立手話単語認識モデルの改善手法を紹介します.
具体的には,前処理 (特徴量エンジニアリングや学習データのアクセス時など) において追跡点の正規化を行うことで,認識性能を改善します.
正規化はデータを一定の規則で変形し利用しやすくすることを意味し様々な手法が考えられます.
今回は,追跡点に対して位置合わせ,スケーリングを行って認識性能を悪化させる成分を除去する方法を紹介します.
さらに,正規化を部位毎に行うことで部位間の依存性を除去する方法も紹介します.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
- 2024/07/29: Gitスクリプトのダウンロード元を
masterからv0.1タグに変更 - 2024/07/23
- 第1節の構成を見直し
- 記事最終部の実験結果を削除して第3節に統合
- 2024/02/14: データセットのロード方法を変更
1. 機械学習ワークフローとの対応関係
図1は,先日の記事で説明した機械学習モデル構築のワークフローの何処が今回の説明箇所に該当するかを示しています.
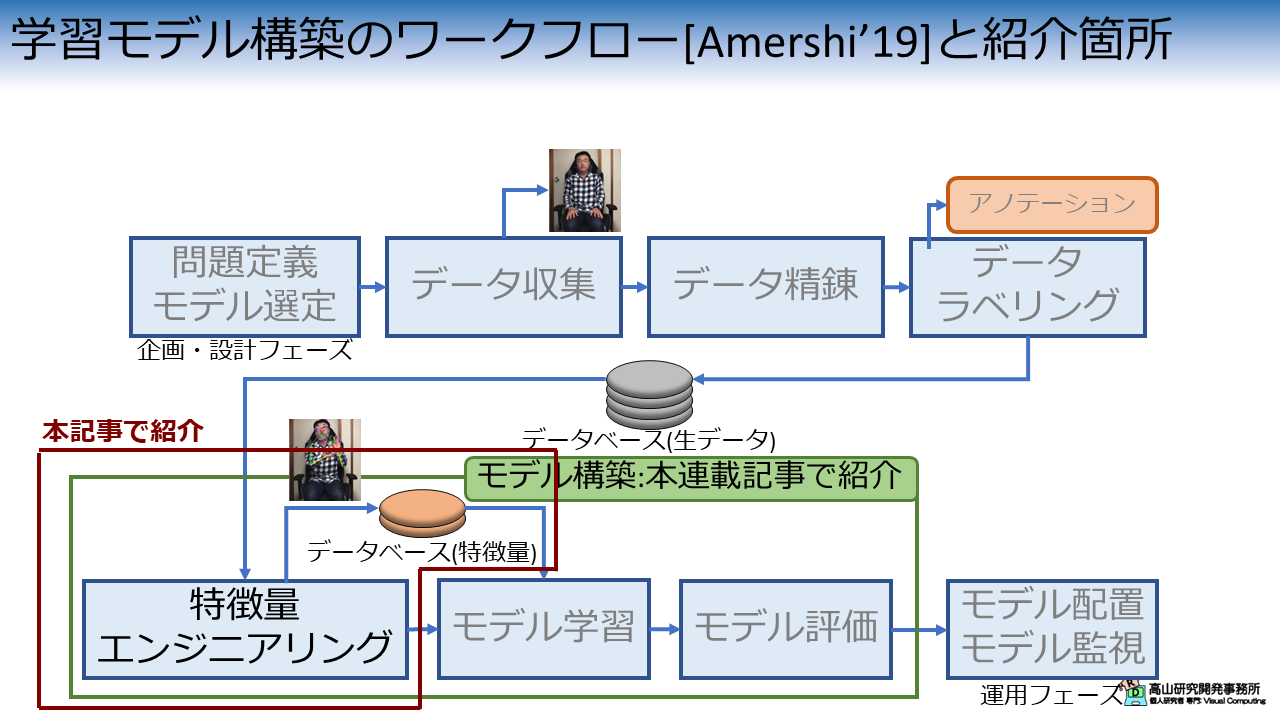
第一回の記事では特徴量エンジニアリングと学習用データセットのアクセス処理について紹介しました.
今回は,これらの前処理に追跡点の正規化処理を加えて認識性能の改善を試みます.
- [Amershi'19]: S. Amershi, et al., "Software Engineering for Machine Learning: A Case Study," Proc. of the IEEE/ACM ICSE-SEIP, available here, 2019.
2. 追跡点の正規化
正規化処理の概略を図2に示します.
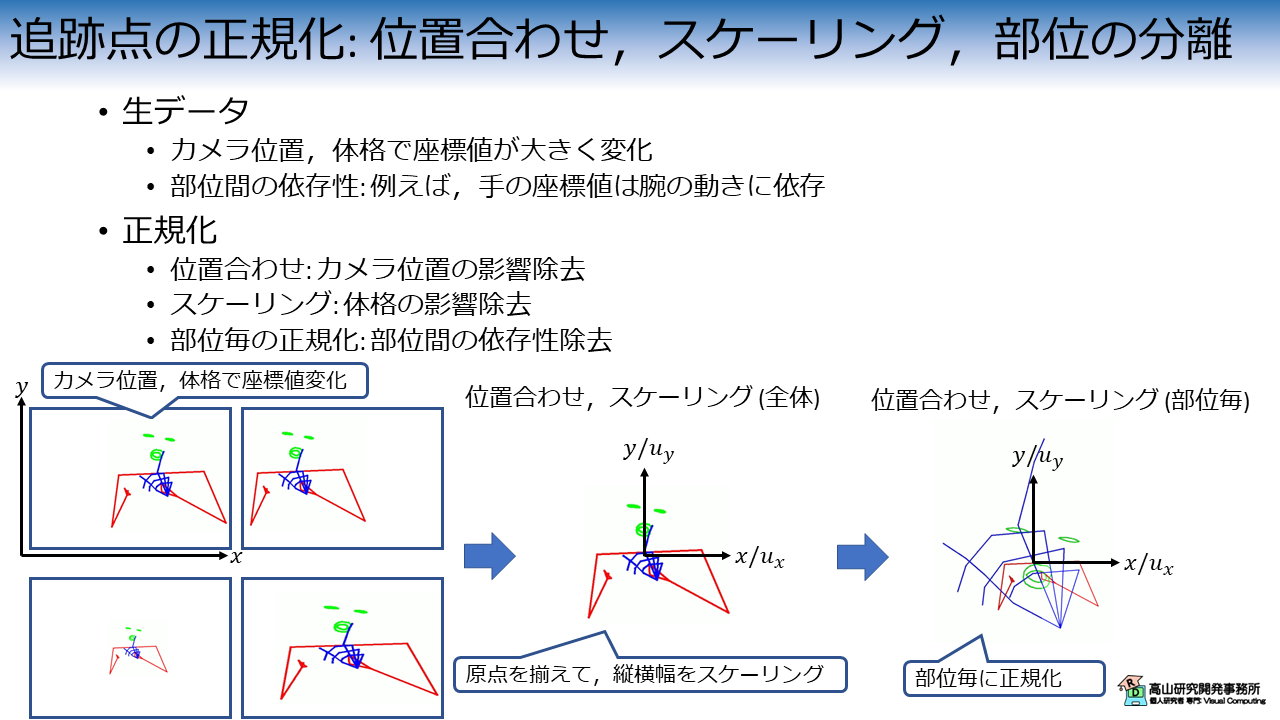
生データの追跡座標は,人体とカメラの位置関係や体格で値が大きく変化します.
これらの要素は手話に関係が無いため,座標値への影響を除去することが望ましいです.
そこで,各追跡座標系列で追跡点の特定位置が原点になるように位置合わせをし,かつ,単位長で座長値をスケーリングすることでこれらの影響を除去します.
手話では顔,身体,および手は,それぞれ独立した構成要素と考えられます.
例えば,腕や身体の動きは似ていても,顔や手の動作・形が違う場合は異なる意味の単語になります.
一方,純粋に信号処理の観点で考えると顔は首,手は手首で身体と接続しており,顔・手の座標値は身体の姿勢・動作に強く依存しています.
身体の方が顔や手よりもサイズが大きいため,顔・手の細かな変化は腕の動きなどの大きな変化に紛れてしまいます.
結果として,認識モデルが顔や手の特徴を捉えることが難しくなり,認識性能が悪化します.
そこで,上で述べた位置合わせとスケーリングを部位毎に行うことで各部位を分離します.
部位の分離により顔・手は身体の影響を受けなくなり,さらにサイズの違いによる認識への影響も除去できるようになります.
3. 実験結果
次節以降では,いつも通り実装の紹介をしながら実験結果をお見せします.
今回は正規化の効果を見るために複数の実験条件を実装しており,少し冗長な展開が続きますので結果を先にお見せしたいと思います.
3.1 認識性能の比較
図3は今回紹介する正規化処理を適用した場合のValidation Lossと認識率の推移を示しています.
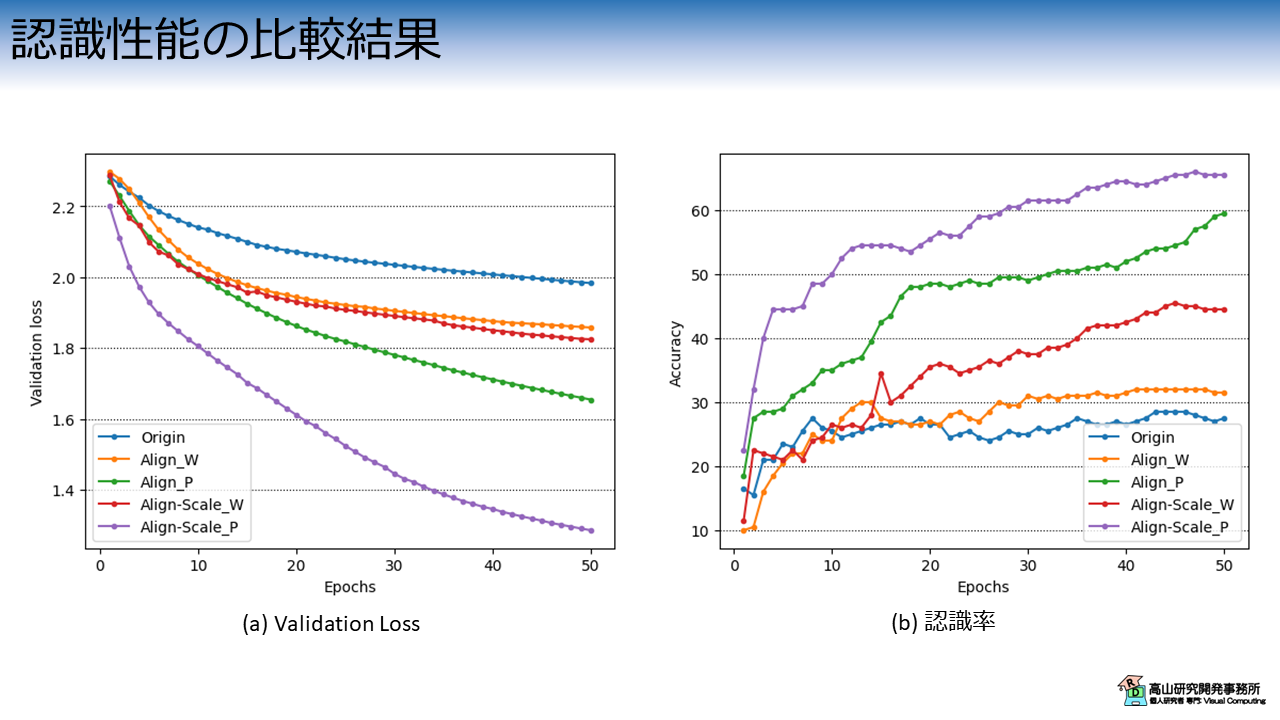
横軸は学習・評価ループの繰り返し数 (Epoch) を示します.
縦軸はそれぞれの評価指標を示します.
各線の色と実験条件の関係は次のとおりです.
- 青線 (Origin): オリジナルの追跡点
- 橙線 (Align_W): 位置合わせ後の追跡点 (追跡点全体に適用)
- 緑線 (Align_P): 位置合わせ後の追跡点 (部位毎に適用)
- 赤線 (Align-Scale_W): 位置合わせとスケーリング後の追跡点 (追跡点全体に適用)
- 紫線 (Align-Scale_P): 位置合わせとスケーリング後の追跡点 (部位毎に適用)
グラフから一目瞭然ですが,正規化を施すことで認識性能は大きく向上しており,特に部位の分離 (紫線と緑線) の効果が大きいことが分かります.
赤線と橙線の結果からは,追跡点全体に適用する場合でもスケーリングは効果があるように見えますが,複数回試すとこの結果は逆転する場合があります.
図3(b) と図3(d) に示したように,追跡点全体にスケーリングを行った場合は部位間の相対的な関係は変わらないため,認識性能への効果は無かったようです.
3.2 正規化パラメータ算出方法の比較
正規化パラメータの算出方法毎 (原点と単位長をフレーム毎に求めるか,フレーム全体から単一値を求めるか) の評価指標の推移を図4に示します.
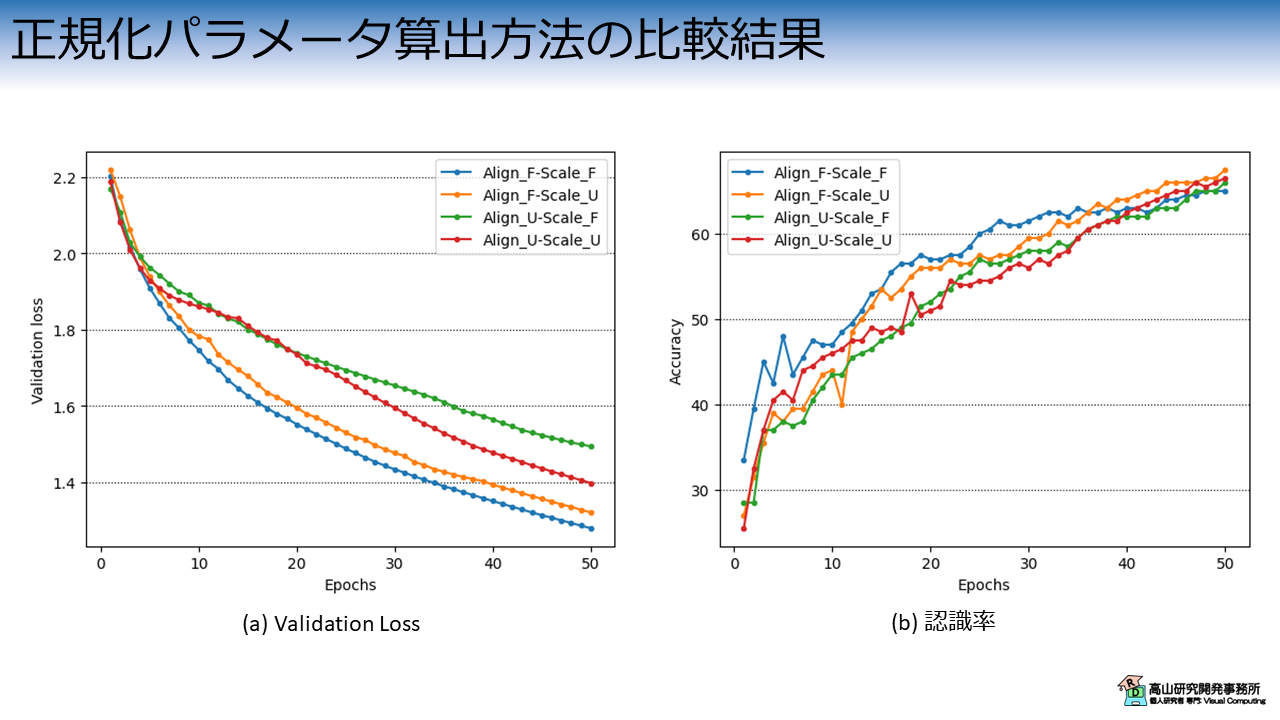
グラフの構成は図3と同様です.
Validation Lossの挙動は若干差がありますが,認識率についてはほぼ近い値に収束しており,明確な性能差は確認できませんでした.
なお,今回の実験では話を簡単にするために,実験条件以外のパラメータは固定にし,乱数の制御もしていません.
複数回試して認識性能の傾向は確認していますが,必ずしも同様の結果になるわけではないので,ご了承ください.
4. 前準備
4.1 データセットのダウンロード
ここからは実装方法の説明をしていきます.
まずは,前準備としてGoogle Colabにデータセットをアップロードします.
以前までは,gdown を用いてダウンロードしていたのですが,このやり方ですと多数の方がアクセスした際にトラブルになるようなので (多数のご利用ありがとうございます!),セットアップの方法を少し変えました.
まず最初に,データセットの格納先からデータをダウンロードし,ご自分のGoogle driveへアップロードしてください.
次のコードでGoogle driveをColabへマウントします.
Google Driveのマウント方法については,補足記事にも記載してあります.
1 2 3 | |
ドライブ内のファイルをColabへコピーします.
パスはアップロード先を設定する必要があります.
# Copy to local.
!cp [path_to_dataset]/gislr_dataset_top10.zip gislr_top10.zip
データセットはZIP形式になっているので unzip コマンドで解凍します.
!unzip gislr_top10.zip
Archive: gislr_top10.zip
creating: dataset_top10/
inflating: dataset_top10/16069.hdf5
...
inflating: dataset_top10/sign_to_prediction_index_map.json
成功すると dataset_top10 以下にデータが解凍されます.
HDF5ファイルはデータ本体で,手話者毎にファイルが別れています.
JSONファイルは辞書ファイルで,TXTファイルは本データセットのライセンスです.
!ls dataset_top10
16069.hdf5 25571.hdf5 29302.hdf5 36257.hdf5 49445.hdf5 62590.hdf5
18796.hdf5 26734.hdf5 30680.hdf5 37055.hdf5 53618.hdf5 LICENSE.txt
2044.hdf5 27610.hdf5 32319.hdf5 37779.hdf5 55372.hdf5 sign_to_prediction_index_map.json
22343.hdf5 28656.hdf5 34503.hdf5 4718.hdf5 61333.hdf5
単語辞書には単語名と数値の関係が10単語分定義されています.
!cat dataset_top10/sign_to_prediction_index_map.json
{
"listen": 0,
"look": 1,
"shhh": 2,
"donkey": 3,
"mouse": 4,
"duck": 5,
"uncle": 6,
"hear": 7,
"pretend": 8,
"cow": 9
}
ライセンスはオリジナルと同様に,CC-BY 4.0 としています.
!cat dataset_top10/LICENSE.txt
The dataset provided by Natsuki Takayama (Takayama Research and Development Office) is licensed under CC-BY 4.0.
Author: Copyright 2024 Natsuki Takayama
Title: GISLR Top 10 dataset
Original licenser: Deaf Professional Arts Network and the Georgia Institute of Technology
Modification
- Extract 10 most frequent words.
- Packaged into HDF5 format.
次のコードでサンプルを確認します.
サンプルは辞書型のようにキーバリュー形式で保存されており,下記のように階層化されています.
- サンプルID (トップ階層のKey)
|- feature: 入力特徴量で `[C(=3), T, J(=543)]` 形状.C,T,Jは,それぞれ特徴次元,フレーム数,追跡点数です.
|- token: 単語ラベル値で `[1]` 形状.0から9の数値です.
1 2 3 4 5 6 7 8 9 | |
['1109479272', '11121526', ..., '976754415']
<KeysViewHDF5 ['feature', 'token']>
(3, 23, 543)
[1]
4.2 モジュールのダウンロード
次に,過去の記事で実装したコードをダウンロードします.
本項は前回までに紹介した内容と同じですので,飛ばしていただいても構いません.
コードはGithubのsrc/modules_gislrにアップしてあります (今後の記事で使用するコードも含まれています).
まず,下記のコマンドでレポジトリをダウンロードします.
(目的のディレクトリだけダウンロードする方法はまだ調査中です(^^;))
!wget https://github.com/takayama-rado/trado_samples/archive/refs/tags/v0.1.zip -O master.zip
--2024-01-21 11:01:47-- https://github.com/takayama-rado/trado_samples/archive/master.zip
Resolving github.com (github.com)... 140.82.112.3
...
2024-01-21 11:01:51 (19.4 MB/s) - ‘master.zip’ saved [75710869]
ダウンロードしたリポジトリを解凍します.
!unzip -o master.zip -d master
Archive: master.zip
641b06a0ca7f5430a945a53b4825e22b5f3b8eb6
creating: master/trado_samples-main/
inflating: master/trado_samples-main/.gitignore
...
モジュールのディレクトリをカレントディレクトリに移動します.
!mv master/trado_samples-main/src/modules_gislr .
他のファイルは不要なので削除します.
!rm -rf master master.zip gislr_top10.zip
!ls
dataset_top10 drive modules_gislr sample_data
4.3 モジュールのロード
主要な処理の実装に先立って,下記のコードでモジュールをロードします.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | |
【コード解説】
- 標準モジュール
- json: JSONファイル制御ライブラリ.辞書ファイルのロードに使用します.
- math: 数学計算処理ライブラリ
- sys: Pythonインタプリタの制御ライブラリ.
今回はローカルモジュールに対してパスを通すために使用します.
- functools: 関数オブジェクトを操作するためのライブラリ.
今回はDataLoaderクラスに渡すパディング関数に対して設定値をセットするために使用します.
- pathlib.Path: オブジェクト指向のファイルシステム機能.
主にファイルアクセスに使います.osモジュールを使っても同様の処理は可能です.
高山の好みでこちらのモジュールを使っています(^^;).
- typing: 関数などに型アノテーションを行う機能.
ここでは型を忘れやすい関数に付けていますが,本来は全てアノテーションをした方が良いでしょう(^^;).
- 3rdパーティモジュール
- numpy: 行列演算ライブラリ
- torch: ニューラルネットワークライブラリ
- torchvision: PyTorchと親和性が高い画像処理ライブラリ.
今回はDatasetクラスに与える前処理をパッケージするために用います.
- ローカルモジュール: sys.pathにパスを追加することでロード可能
- dataset: データセット操作用モジュール
- defines: 各部位の追跡点,追跡点間の接続関係,およびそれらへのアクセス処理を
定義したモジュール
- draw_functions: 追跡点描画モジュール
- layers: ニューラルネットワークのモデルやレイヤモジュール
- transforms: 入出力変換処理モジュール
- train_functions: 学習・評価処理モジュール
get_parts_connections() と draw_functions は初出ですが,今回の本筋には無関係な処理であることと,基本的にはMediaPipeの解説記事で紹介した追跡点描画処理の応用ですので,説明は割愛させていただきます.
5. 前処理の実装
5.1 正規化処理クラス
下記のコードで正規化を行います.
特徴変換処理の一部として,Datasetクラスから呼び出す想定で実装しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 | |
【コード解説】
- 引数
- ***_head: 各部位の先頭インデクス.
追跡点抽出処理後のインデクスを指定する必要があります.
- ***_num: 各部位の追跡点数.
追跡点抽出処理後の追跡点数を指定する必要があります.
`***_num = 0` の場合は,対象部位の正規化をスキップします.
- ***_origin: 位置合わせ用の原点を算出するための追跡点インデクス.
複数インデクスを指定した場合,平均座標が原点になります.
- ***_unit[1/2]: スケーリング用の単位長を算出するための追跡点インデクス.
unit1,unit2は直線の端点を示し,直線の長さがスケーリングの単位長になります.
unit1またはunit2に複数インデクスを指定した場合,平均座標が,それぞれの端点になります.
- align_mode: 位置合わせ用原点の算出方法
- framewise: フレーム毎に異なる原点を算出
- unique: フレーム全体から単一の原点を算出
- scale_mode: スケーリング用単位長の算出方法
- framewise: フレーム毎に異なる原点を算出
- unique: フレーム全体から単一の原点を算出
- none: スケーリング処理をスキップ
- 8-35行目: 初期化処理.
- 37-41行目: 時系列マスクの算出関数
特徴量が全て `0` のフレームをFalse,その他をTrueとするマスクを生成します.
- 43-54行目: 位置合わせ用原点算出関数
53行目は例外処理で,単一原点算出時に全フレームが追跡に失敗している場合は,
`0` を原点として返します.
- 56-84行目: スケーリング用単位長算出関数
例外処理として,エラー値 (`unit <= 0` や `unit == nan`) は `1.0` で置き換えています.
- 86-95行目: 正規化処理関数
94行目で検出失敗フレームをマスクアウトしています.
これは,位置合わせの結果,検出失敗フレームの値が `0` で無くなるためです.
- 97-121行目: 正規化処理メイン
`***_num > 0` の場合,部位毎に正規化を適用します.
正規化パラメータ (原点と単位長) は,フレーム毎に異なる値を計算する方法と,フレーム全体から単一の値を計算する方法を実装しており,インスタンス化時の引数で切り替えられるようにしています.
今回の実験では,原点はフレーム毎に計算し,単位長はフレーム全体から単一の値を計算して処理を行います.
なお,正規化パラメータ算出方法による認識性能の違いは後半にお見せしますが,今回の実験ではあまり差が出ずこれがベストとは言えませんでした(^^;).
5.2 動作チェック
共通処理の実装
正規化処理の実装ができましたので,動作確認をしていきます.
次のコードでデータセットからHDF5ファイルとJSONファイルのパスを読み込みます.
1 2 3 4 5 6 7 8 | |
dataset_top10/sign_to_prediction_index_map.json
[PosixPath('dataset_top10/2044.hdf5'), PosixPath('dataset_top10/32319.hdf5'), PosixPath('dataset_top10/18796.hdf5'), PosixPath('dataset_top10/36257.hdf5'), PosixPath('dataset_top10/62590.hdf5'), PosixPath('dataset_top10/16069.hdf5'), PosixPath('dataset_top10/29302.hdf5'), PosixPath('dataset_top10/34503.hdf5'), PosixPath('dataset_top10/37055.hdf5'), PosixPath('dataset_top10/37779.hdf5'), PosixPath('dataset_top10/27610.hdf5'), PosixPath('dataset_top10/53618.hdf5'), PosixPath('dataset_top10/49445.hdf5'), PosixPath('dataset_top10/30680.hdf5'), PosixPath('dataset_top10/22343.hdf5'), PosixPath('dataset_top10/55372.hdf5'), PosixPath('dataset_top10/26734.hdf5'), PosixPath('dataset_top10/28656.hdf5'), PosixPath('dataset_top10/61333.hdf5'), PosixPath('dataset_top10/4718.hdf5'), PosixPath('dataset_top10/25571.hdf5')]
次のコードで辞書ファイルをロードして,認識対象の単語数を格納します.
1 2 3 4 5 | |
今回は正規化処理の設定の違いで挙動がどう変わるかを見てきます.
違いが分かりやすいように,設定毎の正規化クラスを下記のコードで予めインスタンス化します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
上の各インスタンスは下記のような設定になっています.
trans_align_whole: 位置合わせ (追跡点全体に適用)trans_align_parts: 位置合わせ (部位毎に適用)trans_align_scale_whole: 位置合わせとスケーリング (追跡点全体に適用)trans_align_scale_parts: 位置合わせとスケーリング (部位毎に適用)
追跡点全体に変換を適用する場合は,身体のインデクス範囲を追跡点全体に拡張し,他の部位の処理をスキップしています (7-13行目,17-22行目参照).
次のコードで,前処理をインスタンス化します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
変換の適用
次のコードで,前処理を適用したHDF5DatasetとDataLoaderをインスタンス化し,データを取り出します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
torch.Size([2, 2, 27, 130])
10行目のHDF5Datasetのインスタンス化時に pre_transforms に与える変数を切り替えることで,異なる設定の正規化処理を適用します.
他の設定でもコード構成は同じですので,ここでは説明を割愛させていただきます.
変換結果の描画
正規化処理結果を確認するために,変換後の追跡点を描画します.
まず,次のコードで変換後の追跡点をnumpy型に変換し,その後描画設定を格納します.
1 2 3 4 5 6 7 8 9 10 11 | |
次のコードで,追跡点を動画に描画します.
1 2 3 4 5 6 7 | |
Window size: 739 747
Offsets: 0 0
OpenCVを使って作成した動画ファイルはColab環境上では上手く表示できなかったため,FFMPEGを使用して変換を行います.
1 2 3 | |
次のコードで,描画結果を表示して確認します.
1 | |
他の設定でもコード構成は同じですので,ここでは説明を割愛させていただきます.
結果を図4に示します.
(データロード時にデータ順をソートしていないので,実行時は異なる追跡点が描画される場合があります)
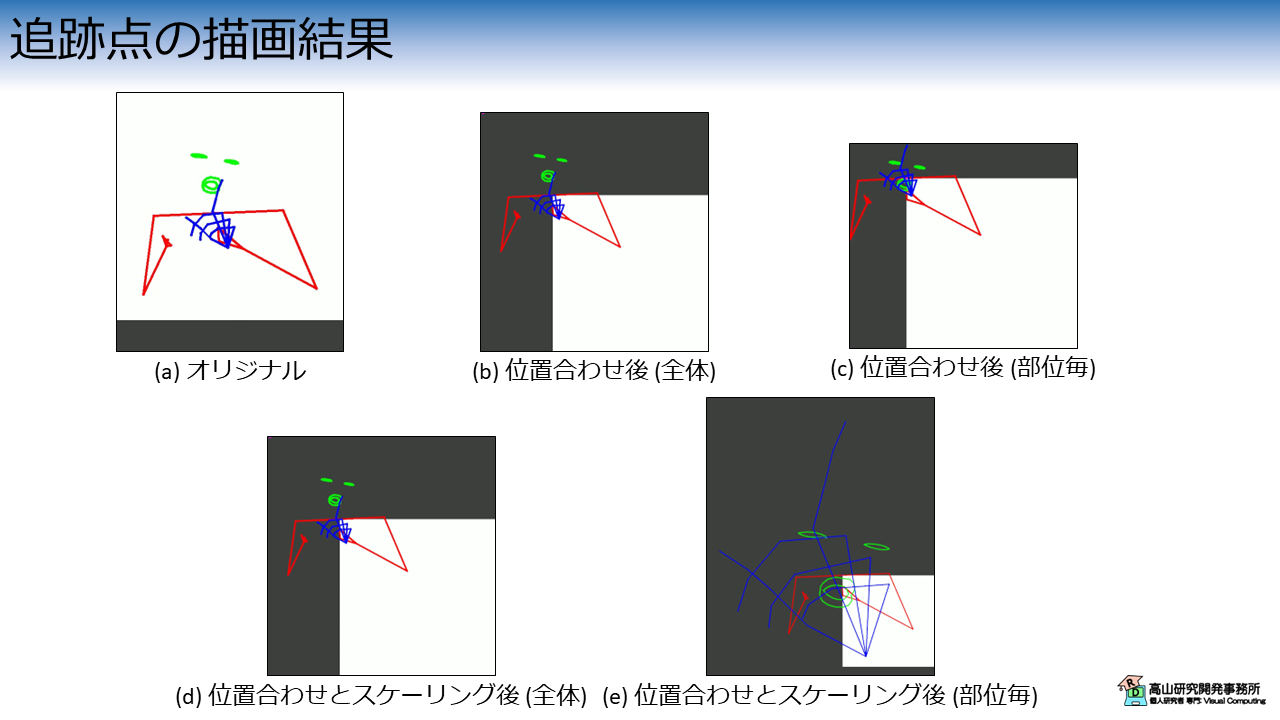
灰色部分は,[0, 1] の範囲外の座標を示しています.
(b) の結果から,位置合わせ後は原点 (両肩の中点) が \((x, y)=(0, 0)\) になるように移動していることが分かります.
(c) の結果から,部位毎に位置合わせをすると,顔や手が身体から分離されることが分かります.
(d) の結果は (b) と見た目上では違いがありません.
これは,スケーリングを追跡点全体に適用しても各部位の相対的な位置関係やサイズは変わらないからです.
一方,(e) に示されるように,位置合わせとスケーリングを部位毎に行った場合は,顔や手のサイズが他とは大きく異なることが分かります.
6. 学習と評価の実行
共通処理
では,実際に学習・評価を行います.
まずは,実験全体で共通して用いる設定値を次のコードで実装します.
今回は認識性能の差が出やすいように,学習・評価ループを50回繰り返します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Using cpu for computation.
学習・評価処理
次のコードでモデルをインスタンス化して,動作チェックをします.
追跡点抽出の結果,入力追跡点数は130で,各追跡点はXY座標値を持っていますので,入力次元数は260になります.
出力次元数は単語数なので10になります.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
SimpleISLR(
(linear): Linear(in_features=260, out_features=64, bias=True)
(activation): ReLU()
(head): GPoolRecognitionHead(
(head): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([2, 10])
次のコードで学習・バリデーション・評価処理それぞれのためのDataLoaderクラスを作成します.
1 2 3 4 5 6 7 8 9 10 11 | |
次のコードで学習・評価処理を行います.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Start training.
--------------------------------------------------------------------------------
Epoch 1
Start training.
loss:2.397505 [ 0/ 3881]
loss:2.293054 [ 3200/ 3881]
Done. Time:3.210748345000013
Start validation.
Done. Time:0.2671058600000151
Validation performance:
Avg loss:2.284921
Start evaluation.
Done. Time:0.8380756489999897
Test performance:
Accuracy:16.5%
--------------------------------------------------------------------------------
...
--------------------------------------------------------------------------------
Epoch 50
Start training.
loss:1.818054 [ 0/ 3881]
loss:1.575389 [ 3200/ 3881]
Done. Time:3.115006970999957
Start validation.
Done. Time:0.27557992300000933
Validation performance:
Avg loss:1.982963
Start evaluation.
Done. Time:0.8766784900000175
Test performance:
Accuracy:27.5%
Minimum validation loss:1.9829625061580114 at 50 epoch.
Maximum accuracy:28.499999999999996 at 43 epoch.
以後,同様の処理を正規化設定値毎に繰り返します.
コード構成は同じですので,ここでは説明を割愛させていただきます.
今回は前処理で追跡点の正規化をすることで,認識性能を改善する方法を紹介しましたが,如何でしたでしょうか?
記事を執筆している間に色々と追加実験をしたくなり,最終的にかなり長文になってしまいました(^^;).
部位毎に特徴量を取り出して認識性能を向上させるアプローチは,手話認識でよく使われるアプローチの一つです (例えば[Koller'20]や[Zhou'21]).
最新の手法では複雑な認識モデルの内部で行うことが多いのですが,今回示したようなシンプルな前処理でも大きな効果があります.
今回紹介した話が,これから手話認識を勉強してみようとお考えの方に何か参考になれば幸いです.
- [Koller'20]: O. Koller, et al., "Weakly Supervised Learning with Multi-Stream CNN-LSTM-HMMs to Discover Sequential Parallelism in Sign Language Videos," IEEE Trans. PAMI, Vol.42, Issue 9, pp.2306-2320, available here, 2020.
- [Zhou'21]: H. Zhou, et al., "Spatial-Temporal Multi-Cue Network for Sign Language Recognition and Translation," IEEE Trans. Multimedia, Vol.24, pp.768-779, available here, 2021.




