こんにちは.高山です.
今回は,以前取り上げた補足記事の検証記事になります.
補足記事では正規化層について役割や特徴を紹介しました.
例えば,画像認識でよく使われている Batch Normalization や,Transformer で使われている Layer Normalization は下記のような特徴があります.
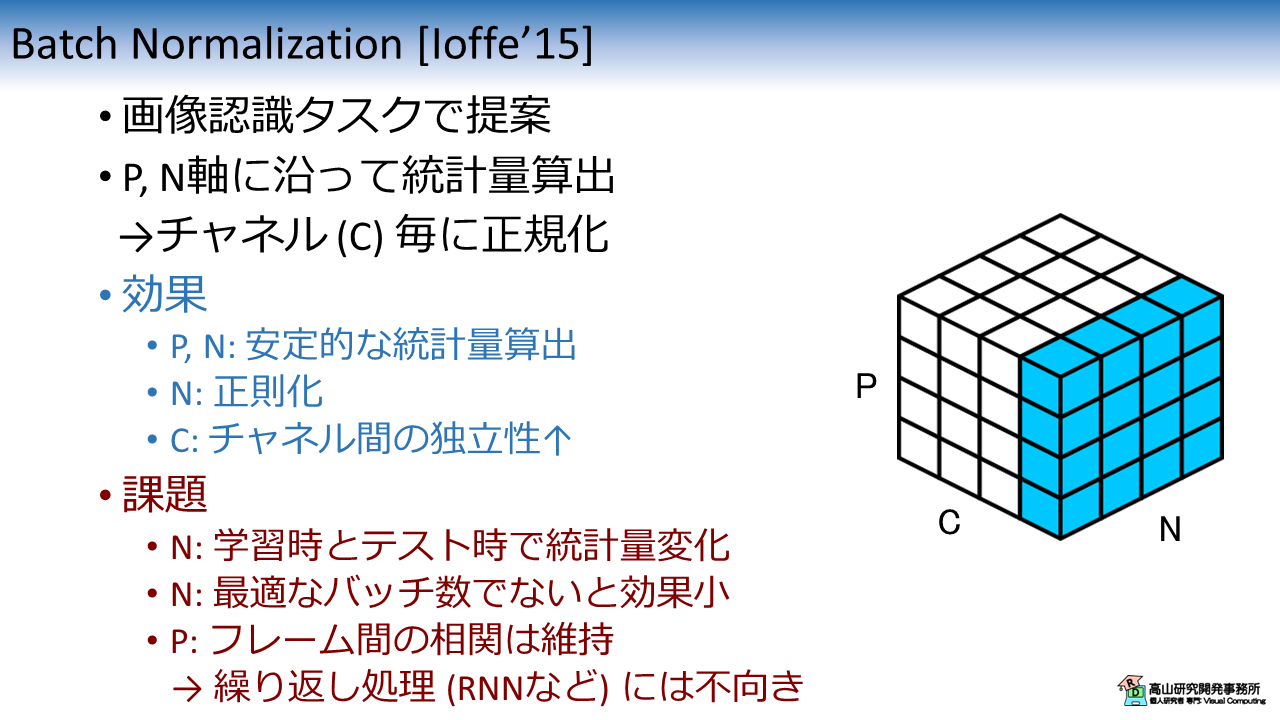
(a): Batch Normalization (BN)
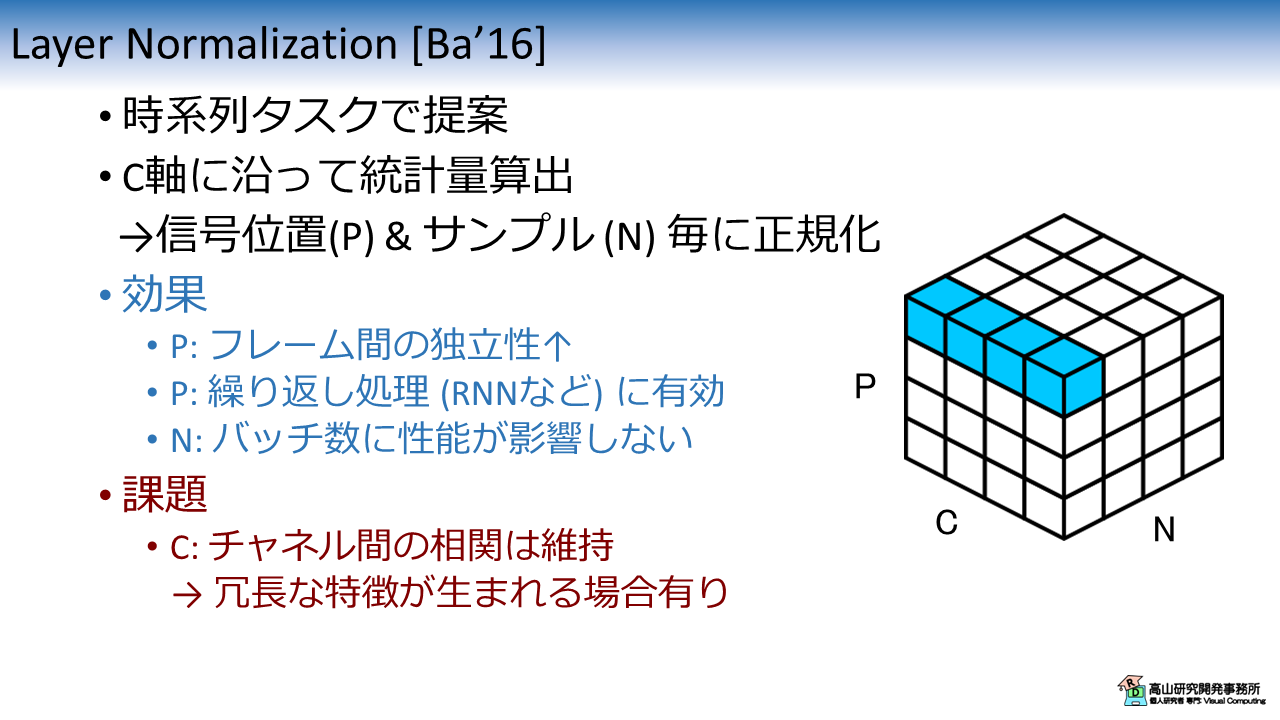
(b): Layer Normalization (LN)
上記の記事を書いている途中で,"結局のところ,GISLR タスクに向いている正規化層は何なのか?" という疑問が出てきてしまいました.
例えば,"LN層は系列データに向いている" という表現はよく目にすると思います.
これは元々は,
- 正規化層を Recurrent Neural Network (RNN) 内に配置して,繰り返し処理の中で正規化を行いたい
- この場合はフレーム毎に異なる値で正規化した方が,フレーム間の独立性が高まるので有効
- 同時に,バッチ数や系列長の影響も受けなくなるので良い
という文脈で出てきていたと思います[Ba'16].
しかしながら,ここまでの記事で利用してきた Transformer-Encoder の処理を考えると,RNN のような繰り返し処理は含まれていないことに気づきます.
この場合,先に述べたフレーム間の独立性はどこまで重要なのか?,という疑問が発生しました.
図にまとめると,下記のようになります.
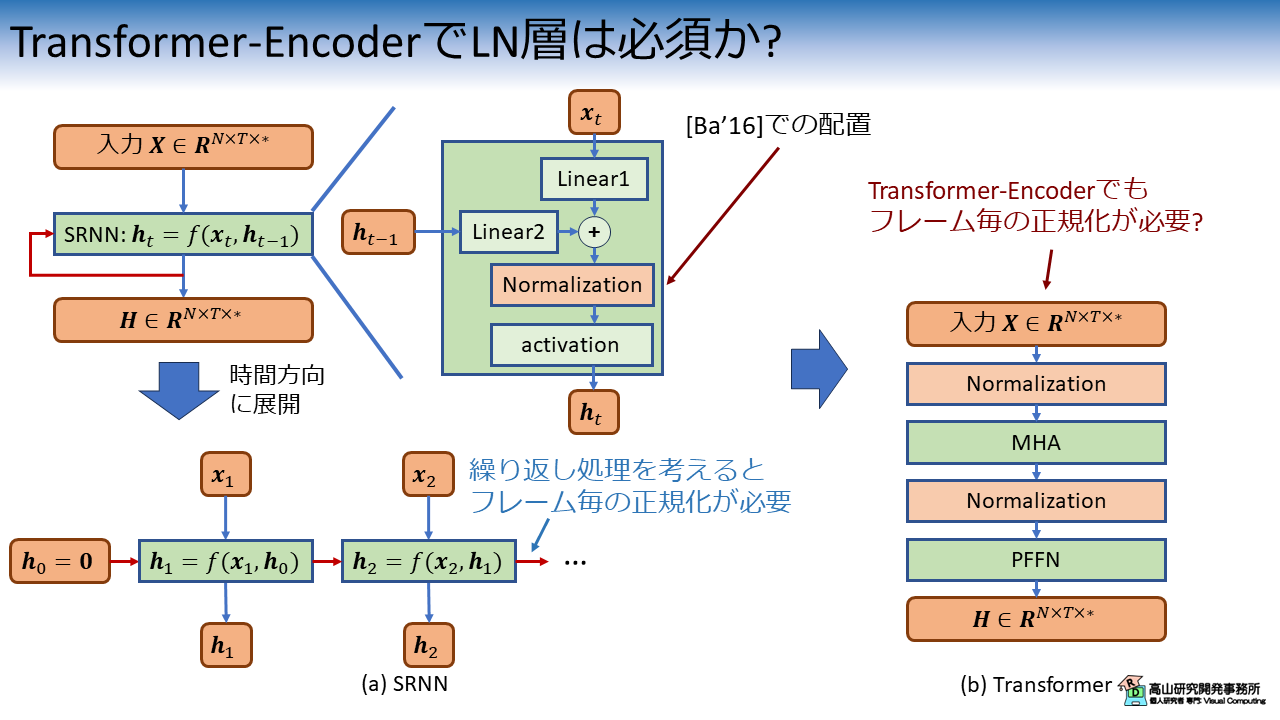
また,GISLRタスクは骨格点座標系列が入力なので特徴量間の相関は高いです (身体部位の追跡点は連動して動くので).
ここから,
- LN層 は特徴量間の相関は維持するので認識性能向上効果が弱まるのでは?
- BN層 で特徴量間の独立性を向上させた方が良いのでは?
との疑問が湧いてきました.
今回はこのような疑問を解消すべく,Transformer の正規化層を変えて認識性能がどのように変化するのかを検証してみました.
- [Ba'16]: J. Ba, et al., "Layer Normalization," arXiV: 1607.06450, available here, 2016.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
1. 先に結論
次節から少し細かな話が出てきますので最初に結論を述べてしまいますと,"結局はデータと処理構成依存" という身も蓋もない結果でした(^^;).
ただし,実験結果から下記のような傾向が観察できました.
- LN層は平均的な結果が得やすい
- BN層はデータ次第では LN層よりも性能が向上する場合がある
実施ではまず最初に LN層を試してみて,チューニングをする余裕があるならば BN層を試してみるという手順が妥当かなと感じました.
では,次節から実験について説明していきたいと思います.
2. 実験概要
図3に今回の実験内容を示します.
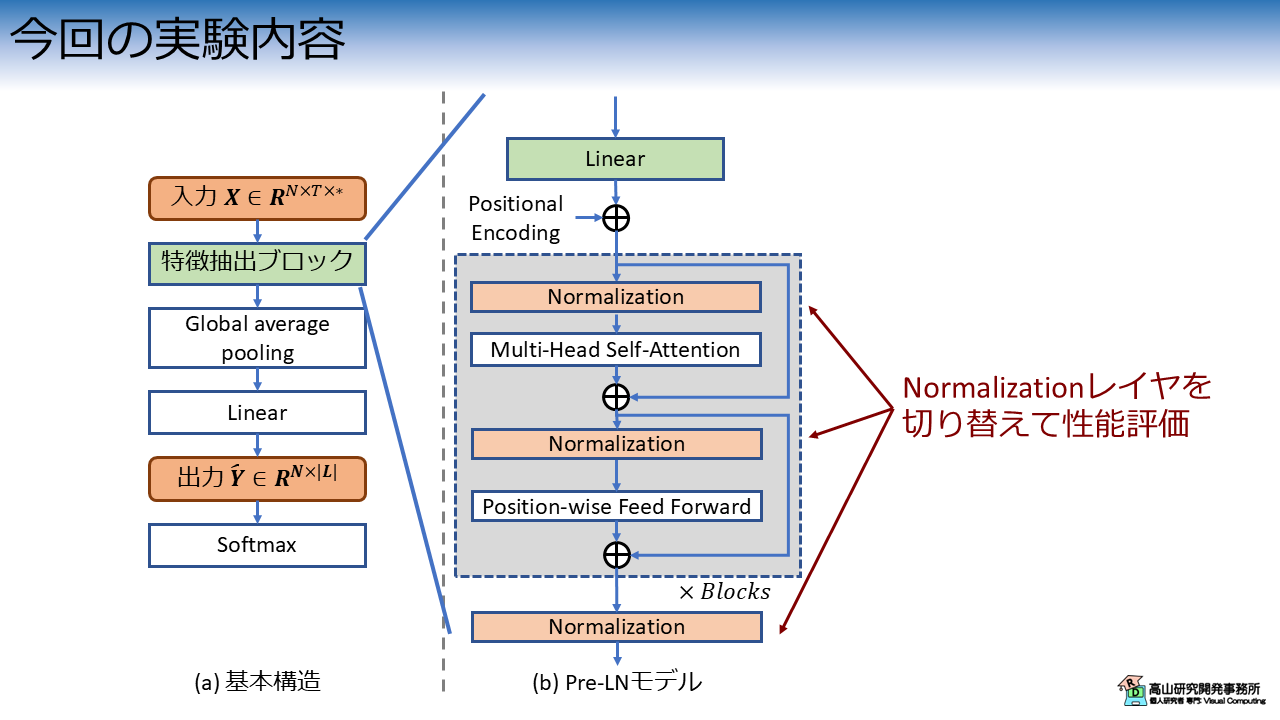
第九回の記事で紹介したPre-LN 構成の Transformer をベースとして,正規化層を変更して認識性能を比較します.
全ての正規化層を試すと大変なので,今回は BN と LN に対象を絞って実験を行います.
3. 実験結果
3.1 欠損値の補間をしない場合
図4は,正規化層の設定毎のValidation Loss と認識率の推移を示しています.
今回の実験では,全て全データ(250単語) を学習させて検証を行いました.
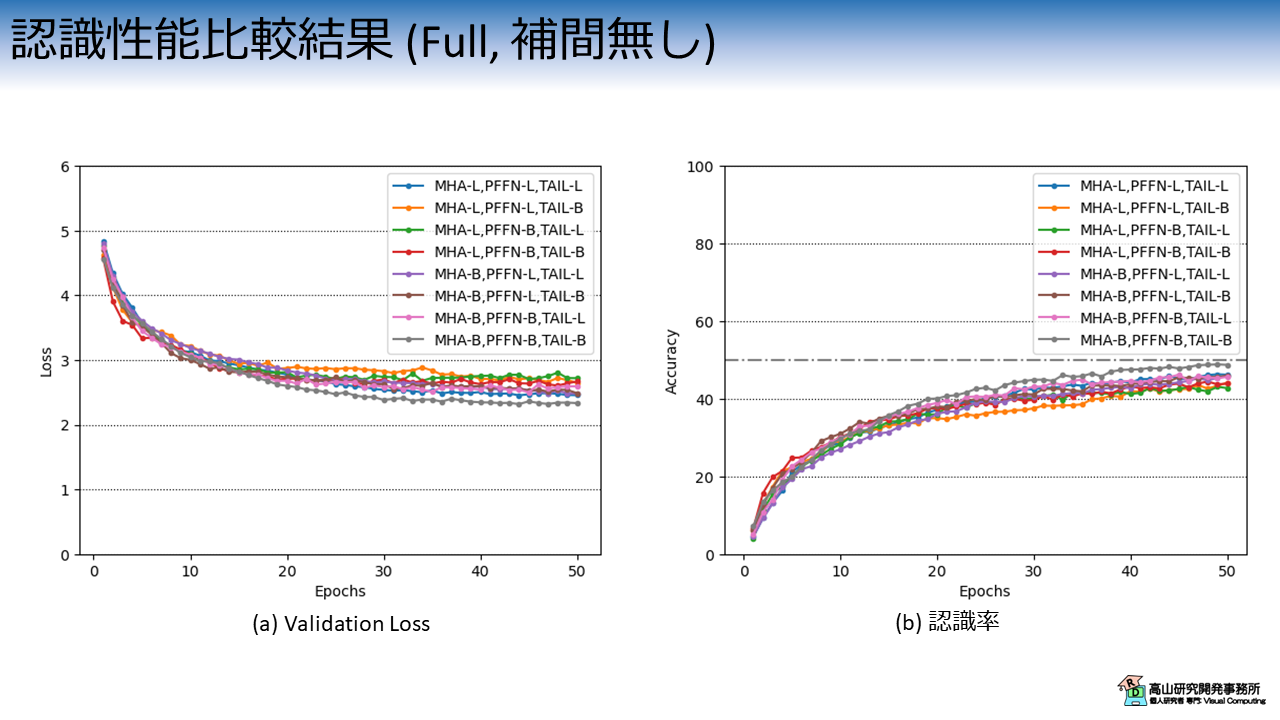
横軸は学習・評価ループの繰り返し数 (Epoch) を示します.
縦軸はそれぞれの評価指標を示します.
各線の色と実験条件の関係は次のとおりです.
MHA, PFFN, TAIL は,それぞれ Multi-head self-attention, Positionwise Feed Forward Network, 末尾の正規化層を指しており,接尾辞の L と B は LN層とBN層を表します.
- 青線 MHA-L, PFFN-L, TAIL-L: 全て LN層 (Pre-LN構成のTransformerと同様)
- 橙線 MHA-L, PFFN-L, TAIL-L: 末尾だけ BN層
- 緑線 MHA-L, PFFN-B, TAIL-L: PFFN だけ BN層
- 赤線 MHA-L, PFFN-B, TAIL-B: PFFN と末尾が BN層
- 紫線 MHA-B, PFFN-L, TAIL-L: MHA だけ BN層
- 茶線 MHA-B, PFFN-L, TAIL-B: MHA と末尾が BN層
- 桃線 MHA-B, PFFN-B, TAIL-L: MHA と PFFN
- 灰線 MHA-B, PFFN-B, TAIL-B: 全て BN層
実験結果から,全て BN層に変える (灰線) と性能が向上することが分かります.
全て LN層のケース (青線) もそれなりに高い性能を出していることから,下記のような仮説を立ててみました.
- GISLRタスクでは,チャネル間およびフレーム間の双方で高い相関があると考えられる.
- チャネル間の独立性を高める (BN層) vs フレーム間の独立性を高める (LN層) ,どちらがより効果があるかという問題に帰着される.
- 今回はチャネル間の独立性を高める方が効果があった.
- GISLRタスクには欠落フレームが多く含まれるため,フレーム間の独立性がある程度担保されているのでは?
この仮説を確かめるために行った実験結果を次項で説明します.
3.2 欠損値の補間をする場合
前項で出た仮説を確かめるために,補足記事8で紹介した欠損値の補間を適用した上で再度実験を行ってみました.
欠損値の補間をすると欠落フレームは隣接フレームと類似した特徴量になり,フレーム間の相関が高まります.
結果的に LN層の効果が出やすいデータになると予想できます.
実験結果を図5に示します.
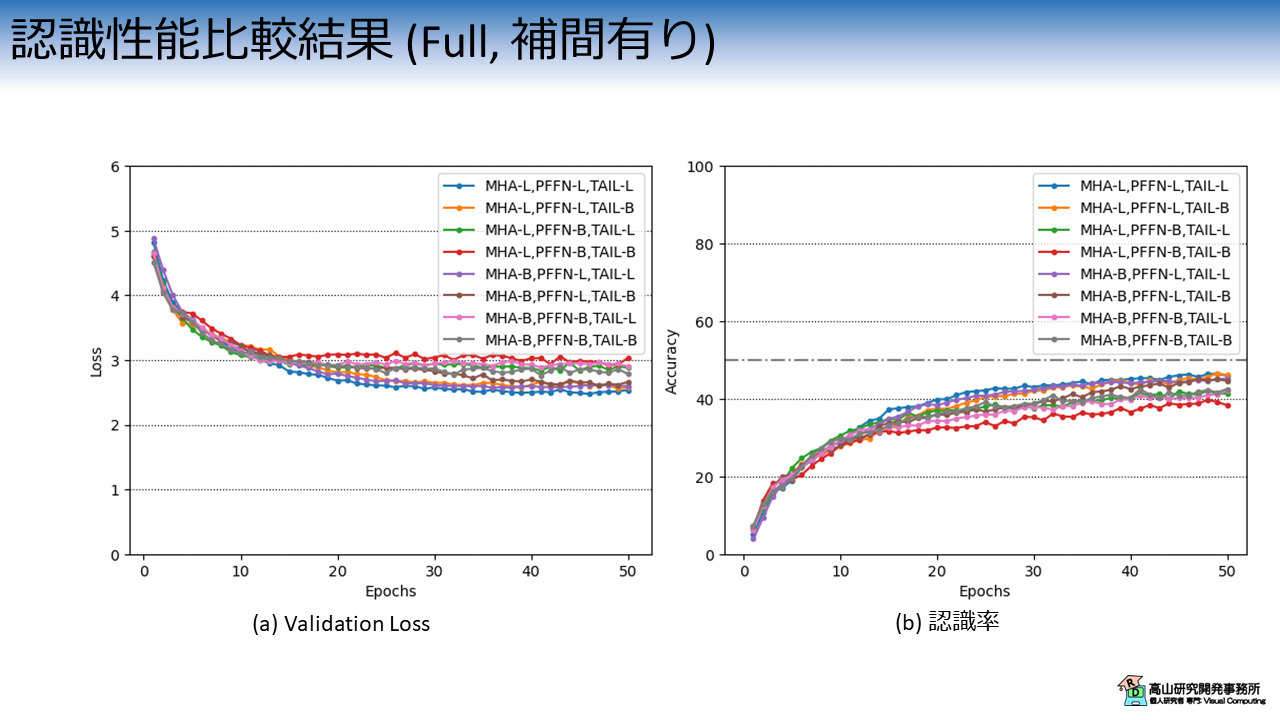
欠損値の補間をしたケースでは,BN層を用いると (特にPFFN層に適用すると) 認識性能が落ちていることが分かります.
全てLN層を用いた場合は性能変化が少なく,結果として最も良い認識性能となりました.
ここから,フレーム間の相関が高いことが予想されるケースでは LN層を用いてフレーム間の独立性を向上させた方が認識性能が向上しやすいことが分かります.
今回は,Transformer-Encoder の正規化層を変更して認識性能が向上するのかを検証してみましたが,如何でしたでしょうか?
ふと思いつきで初めてみた実験ですが,中々興味深い結果が得られて楽しめました.
(比較数が多くて実験には時間がかかりましたが(^^;))
広く使われている標準的な手法でも,発表された当時の背景や前提条件に着目してみると,改善の余地は結構見つかるものですね.
別のアーキテクチャでは異なる結果が得られそうですし,機会があればまた実験をしてみたいと思います.
今回紹介した話が,これから手話認識や深層学習を勉強してみようとお考えの方に何か参考になれば幸いです.