目次
こんにちは.高山です.
先日の記事で告知しました手話認識入門記事の第九回になります.
今回は,Transformer [Vaswani'17] を用いた孤立手話単語認識モデルを実装する方法を紹介します.
(やっとたどり着きました...(^^;))
Transformer は自然言語処理分野で一斉を風靡した (している) 手法で,もしかしたら技術畑じゃない方も聞いたことがあるかもしれません.
元々は翻訳タスク向けに提案されましたが,その後各種の自然言語処理 [Radford'18, Devlin'18],および他分野 [Dong'18, Dosovitskiy'21] へと応用を広げています.
手話分野へは,2020年頃に手話翻訳タスク向けの手法として導入され [Camgoz'20],現在でも継続的に改良が続けられています [Zuo'22, Yin'22].
オリジナルのTransformerは,Encoder-Decoderと呼ばれる翻訳向けのアーキテクチャを採用しています.
Encoder-Decoderは少し複雑なので,今回はこれまでの記事と同様に,孤立手話単語認識モデルの特徴抽出ブロックとしてTransformerを用いる構成 (Encoder-onlyアーキテクチャ) を紹介します.
Encoder-Decoderアーキテクチャについては,また別記事で取り上げたいと思います.
(なお,Encoder-Decoderアーキテクチャを孤立手話単語認識に用いることは問題なく可能です)
今回解説するスクリプトはGitHub上に公開しています.
色々な実験を行っている都合で,CPUで動かした場合は結構時間がかるのでご注意ください.
- [Vaswani'17]: A. Vaswani, et al., "Attention Is All You Need," Proc. of the NIPS, available here, 2017.
- [Radford'18]: A. Radford, et al., "Improving Language Understanding by Generative Pre-Training," published in the OpenAI's page, available here, 2018.
- [Devlin'18]: J. Devlin, et al., "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv:1810.04805v2, available here, 2018.
- [Dong'18]: L. Dong, et al., "Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition," Proc. of the ICASSP, available here, 2018.
- [Dosovitskiy'21]: A. Dosovitskiy, et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," Proc. of the ICLR, available here, 2021.
- [Camgoz'20]: N. C. Camgoz, et al., "Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation," Proc. of the IEEE CVPR, available here, 2020.
- [Zuo'22]: R. Zuo, et al., "C2SLR: Consistency-enhanced Continuous Sign Language Recognition," Proc. of the IEEE CVPR, available here, 2022.
- [Yin'22]: A. Yin, et al., "MLSLT: Towards Multilingual Sign Language Translation," Proc. of the IEEE CVPR, available here, 2022.
更新履歴 (大きな変更のみ記載しています)
- 2024/09/18: カテゴリを変更しました
- 2024/09/17: タグを更新しました
- 2024/07/29: Gitスクリプトのダウンロード元を
masterからv0.1タグに変更 - 2024/07/23
- 第1節の構成を見直し
- 記事最終部の実験結果を削除して第3節に統合
1. モデルの改良内容
これまでの記事と同様に,今回も特徴抽出ブロックとGlobal average poolingから成る孤立手話単語認識モデルを用います.
図1に示すように,今回はモデルの特徴抽出ブロックにTransformerのencoderを用いて認識性能の改善を試みます.
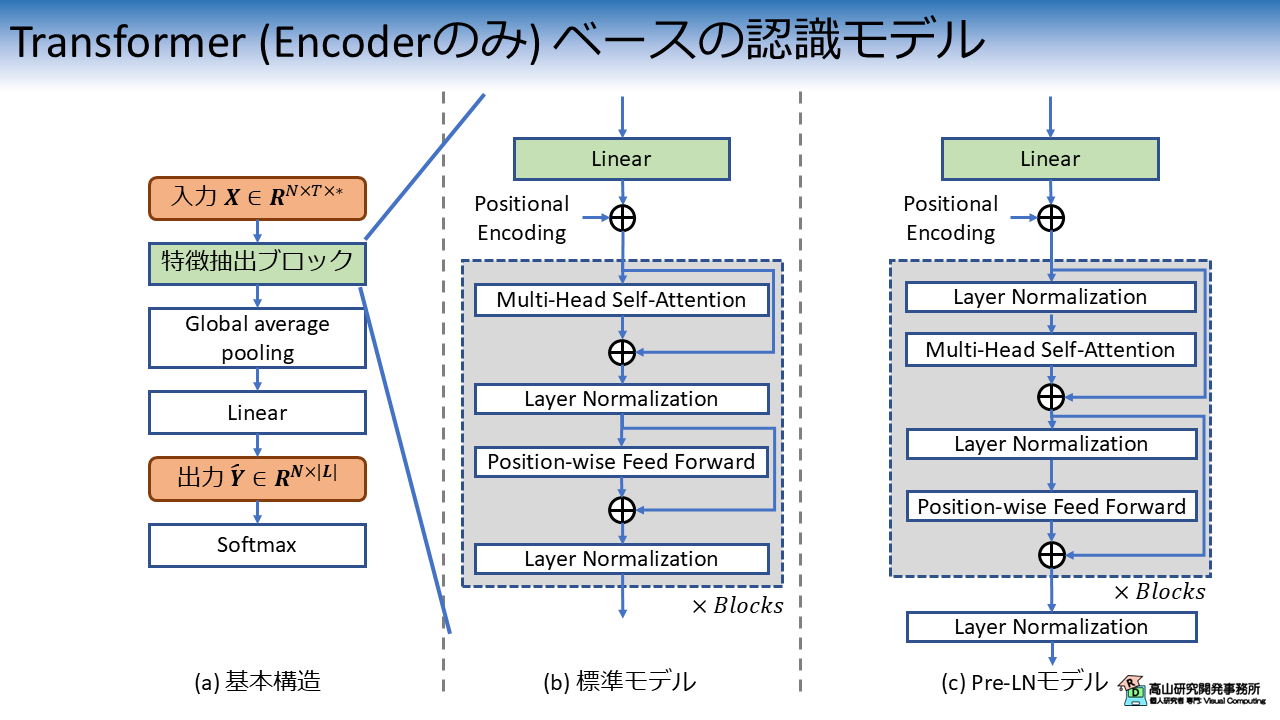
Transformerは継続的に改良が重ねられており,様々な構成のモデルが提案されています.
今回は図1(b) に示すオリジナルの構成と,図1(c) に示すpre-layer normalization (Pre-LN) 構成 [Xiong'20] を紹介したいと思います.
Pre-LN構成は,特徴量の正規化を行うLayer Normalization [Ba'16] を,各処理ブロックの前とTransformer層の後ろに配置する構成になっており,オリジナルよりも安定した学習が可能であると言われています.
今回は双方の構成を実装して,認識性能の比較をしてみたいと思います.
なお,上記の構成はPyTorchの実装済みのTransformerクラスを利用することで簡単に実装できます.
このクラスは高速な処理を行うことができますが,実装が複雑で拡張性に乏しいため今回は自前で実装したいと思います.
- [Xiong'20]: R. Xiong, et al., "On Layer Normalization in the Transformer Architecture," Proc. of the ICML, available here, 2020.
- [Ba'16]: J. L. Ba, et al., "Layer Normalization," arXiv:1607.06450, available here, 2016.
2. Transformerの構成要素
Transformerではpositional encoding (PE),multi-head attention (MHA),および position-wise feed-forward network (PFFN) の技術が提案されています.
(他には特徴量の正規化を行うLNと,勾配消失を防ぐための residual connection が用いられています)
今回の記事では実装面に注力したいので,ここでは簡単な概要を紹介します.
詳細な説明はまた別記事で行いたいと思います.
2.1 Positional encoding
Transformerには,入力データの位置関係を取り扱う層が存在しません.
(RNNの場合は,繰り返し処理によって "あるフレームが別のフレームよりも後" といった情報を取り扱っています)
PEはこの問題に対処するための技術で,図2に示すような三角関数を用いた位置信号を生成します.

位置信号の生成において重要なのは,
- 位置毎にユニークな信号を生成 (図2の赤枠に示すとおり,各行で異なる値になっていることが重要)
- 位置信号の値が一定の範囲に収まっている([-1, 1])
という特性で,PEはシンプルな手法で上記の要求を達成することができます.
2.2 Multi-head attention
MHAは入力系列間の関係性を捉えながら特徴抽出を行う層です.
特に今回のように1種類の系列を入力して,同系列内におけるフレーム間の関係性を捉えながら特徴抽出を行う場合は multi-head self attention (MHSA) と呼ばれます.
(区別のために,2種類の系列を入力する場合は multi-head cross attention と呼ばれる場合もあります)
図3にMHSAのブロック図とAttention出力例を示します.
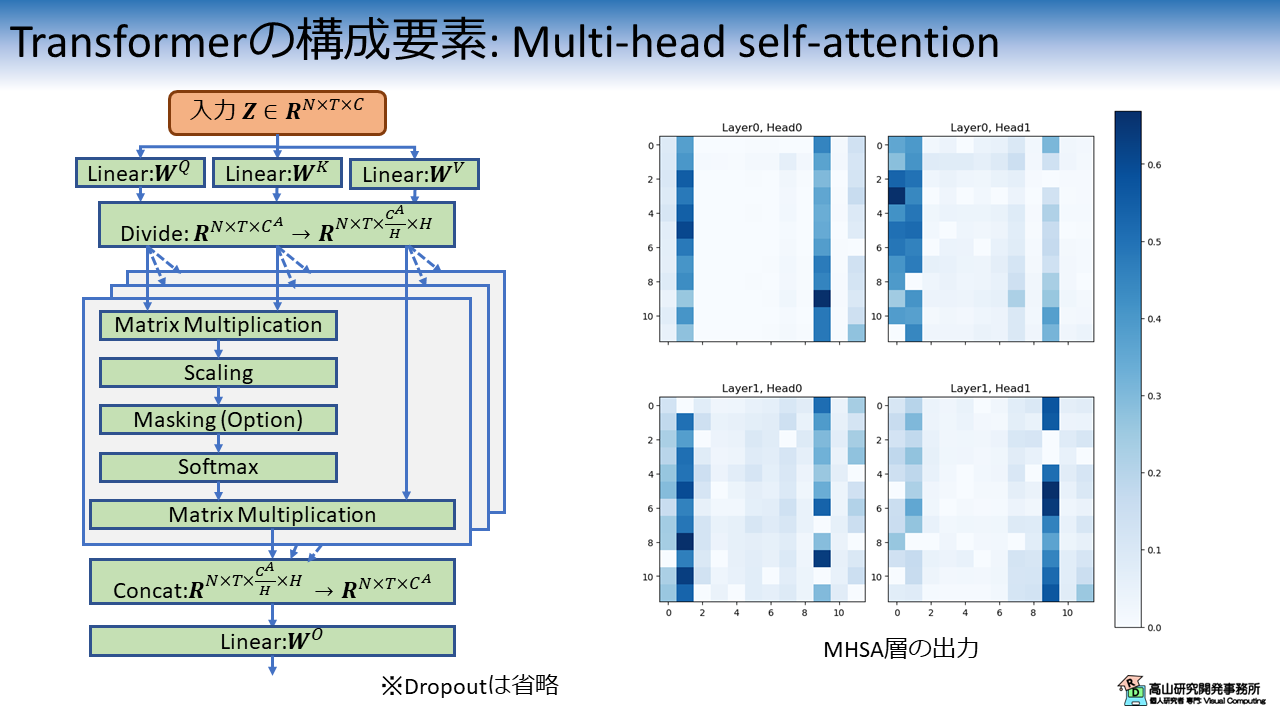
前回紹介したシンプルなAttentionでは (第3.2項をご参照ください),[1, T] 形状の重み (Tは系列長) を生成して,特徴量に対して重み付けだけを行っていました.
一方MHSAでは,[T, T]形状の重みを生成します.
図3右側に示す出力例では,各行がそれぞれのフレームに対する他のフレームの重みを示しています.
MHSAではこの重み配列と特徴量系列の行列演算を用いて,フレーム間の関係性を捉えながら他のフレームの情報を取り込みます.
MHSAを適用すると各フレームが全フレームの特徴量を持つようになるため,より高度な系列処理を行うことが可能になります.
2.3 Position-wise feed-forward network
図4 に示すPFNNは特徴抽出を行う層で,2個の線形変換層で活性化関数 (通常はReLUタイプ) を挟む構造になっています.
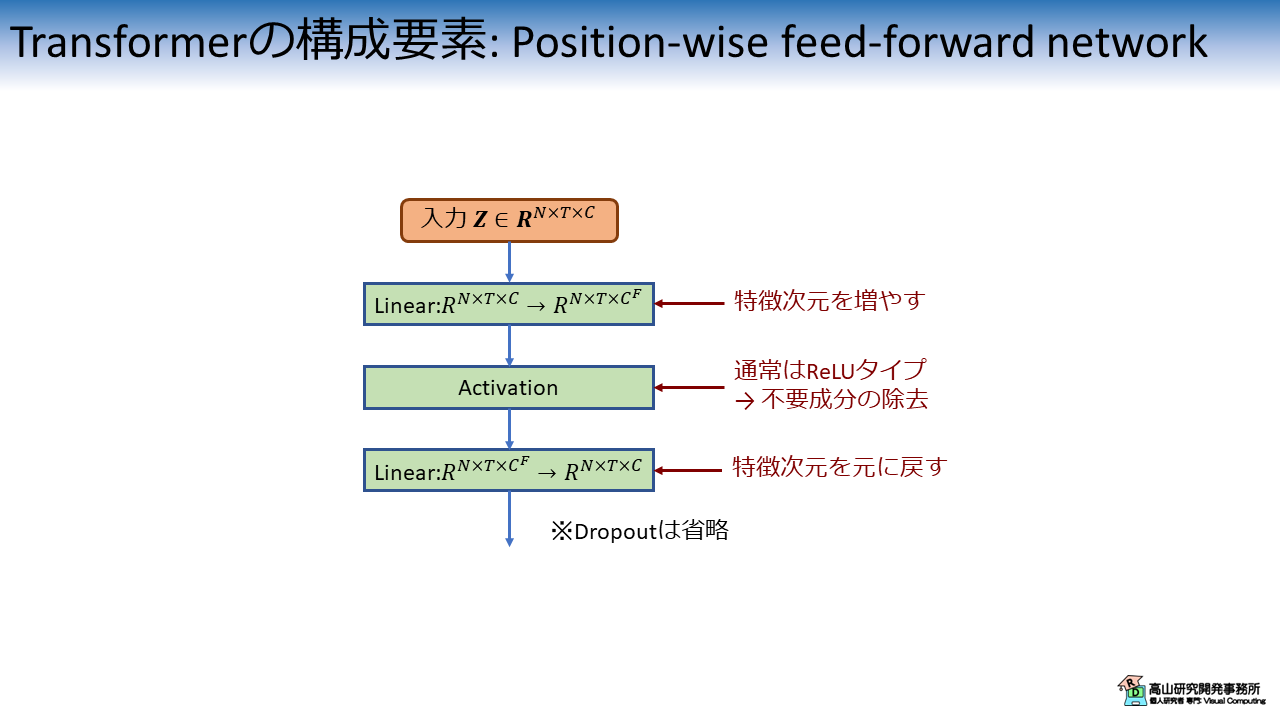
PFNNは入力の位置毎に独立に特徴抽出を行う (position-wise の名前の由来) ため,GPUによる並列処理が可能です.
オリジナルの実装では,最初の線形変換層で特徴量の次元数を増やし,活性化関数を適用後に元の次元数に戻す設計になっています.
この設計の効果や意図はあまり明確ではありませんが,拡張した次元においてReLUを適用することでイイカンジに不要成分を除去できるようなイメージはあります.
(高山の個人的感想です(^^;))
3. 実験結果
次節以降では,いつも通り実装の紹介をしながら実験結果をお見せします.
コード紹介記事の方針として記事単体で全処理が分かるように書いており,少し冗長な展開が続きますので結果を先にお見せしたいと思います.
3.1 頻度の多い10単語を用いた実験結果
図5は,Transformer層の構成毎のValidation Lossと認識率の推移を示しています.
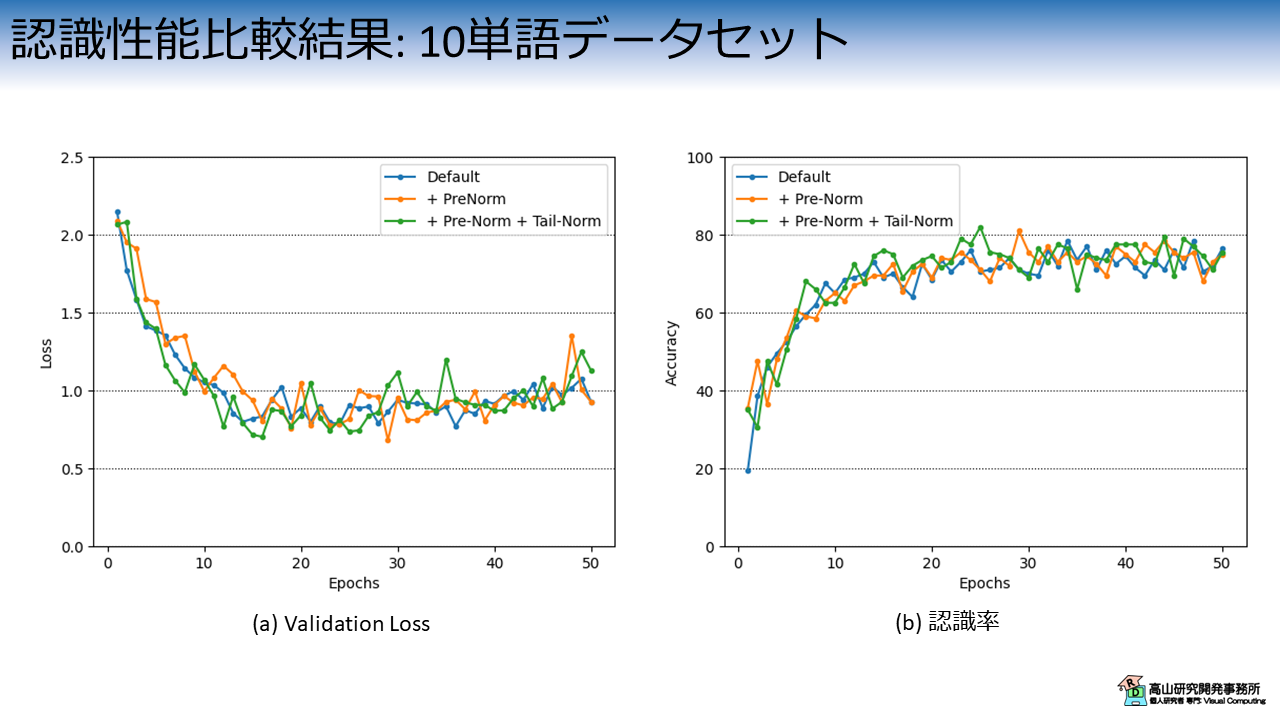
横軸は学習・評価ループの繰り返し数 (Epoch) を示します.
縦軸はそれぞれの評価指標を示します.
各線の色と実験条件の関係は次のとおりです.
- 青線 (Default): 標準構成のTransformer
- 橙線 (+ PreNorm): Pre-LN構成のTransformerで末尾のLNを抜いた構成
- 緑線 (+ PreNorm + Tail-Norm): Pre-LN構成
文献[Xiong'20]では,Transformer層の後ろにもLNを配置する構成が採用されていますが,PyTorchのTransformerクラスでは末尾のLNはオプション扱いですので,末尾のLNを外した構成 (+ PreNorm) も試しました.
波形上では分かりにくいですが,Pre-LN構成が標準構成よりも少し性能が良い結果になりました.
図5(a) の橙線と緑線を比べると,末尾のLN層がある場合の方が少し早く収束しているようです.
- [Xiong'20]: R. Xiong, et al., "On Layer Normalization in the Transformer Architecture," Proc. of the ICML, available here, 2020.
3.2 頻度の多い30単語を用いた実験結果
図6は同様の実験を30単語分のデータを使用して行った際の,Validation Lossと認識率の推移を示しています.
(今回は実験時間の短縮のためにこちらの結果はローカル環境で出しています)

こちらも同様に,Pre-LN構成が標準構成よりも少し性能が良い結果になりました.
図6(b) に示した認識率の推移を見ると,各結果ともに性能は収束していないようです.
学習時間を増やしたり,さらなる工夫を入れることで認識性能はまだ伸ばせそうですね.
なお,今回の実験では話を簡単にするために,実験条件以外のパラメータは固定にし,乱数の制御もしていません.
必ずしも同様の結果になるわけではないので,ご了承ください.
- [Xiong'20]: R. Xiong, et al., "On Layer Normalization in the Transformer Architecture," ICML, available here, 2020.
4. 前準備
4.1 データセットのダウンロード
ここからは実装方法の説明をしていきます.
まずは,前準備としてGoogle Colabにデータセットをアップロードします.
以前までは,gdown を用いてダウンロードしていたのですが,このやり方ですと多数の方がアクセスした際にトラブルになるようなので (多数のご利用ありがとうございます!),セットアップの方法を少し変えました.
まず最初に,データセットの格納先からデータをダウンロードし,ご自分のGoogle driveへアップロードしてください.
次のコードでGoogle driveをColabへマウントします.
Google Driveのマウント方法については,補足記事にも記載してあります.
1 2 3 | |
ドライブ内のファイルをColabへコピーします.
パスはアップロード先を設定する必要があります.
# Copy to local.
!cp [path_to_dataset]/gislr_dataset_top10.zip gislr_top10.zip
データセットはZIP形式になっているので unzip コマンドで解凍します.
!unzip gislr_top10.zip
Archive: gislr_top10.zip
creating: dataset_top10/
inflating: dataset_top10/16069.hdf5
...
inflating: dataset_top10/sign_to_prediction_index_map.json
成功すると dataset_top10 以下にデータが解凍されます.
HDF5ファイルはデータ本体で,手話者毎にファイルが別れています.
JSONファイルは辞書ファイルで,TXTファイルは本データセットのライセンスです.
!ls dataset_top10
16069.hdf5 25571.hdf5 29302.hdf5 36257.hdf5 49445.hdf5 62590.hdf5
18796.hdf5 26734.hdf5 30680.hdf5 37055.hdf5 53618.hdf5 LICENSE.txt
2044.hdf5 27610.hdf5 32319.hdf5 37779.hdf5 55372.hdf5 sign_to_prediction_index_map.json
22343.hdf5 28656.hdf5 34503.hdf5 4718.hdf5 61333.hdf5
単語辞書には単語名と数値の関係が10単語分定義されています.
!cat dataset_top10/sign_to_prediction_index_map.json
{
"listen": 0,
"look": 1,
"shhh": 2,
"donkey": 3,
"mouse": 4,
"duck": 5,
"uncle": 6,
"hear": 7,
"pretend": 8,
"cow": 9
}
ライセンスはオリジナルと同様に,CC-BY 4.0 としています.
!cat dataset_top10/LICENSE.txt
The dataset provided by Natsuki Takayama (Takayama Research and Development Office) is licensed under CC-BY 4.0.
Author: Copyright 2024 Natsuki Takayama
Title: GISLR Top 10 dataset
Original licenser: Deaf Professional Arts Network and the Georgia Institute of Technology
Modification
- Extract 10 most frequent words.
- Packaged into HDF5 format.
次のコードでサンプルを確認します.
サンプルは辞書型のようにキーバリュー形式で保存されており,下記のように階層化されています.
- サンプルID (トップ階層のKey)
|- feature: 入力特徴量で `[C(=3), T, J(=543)]` 形状.C,T,Jは,それぞれ特徴次元,フレーム数,追跡点数です.
|- token: 単語ラベル値で `[1]` 形状.0から9の数値です.
1 2 3 4 5 6 7 8 9 | |
['1109479272', '11121526', ..., '976754415']
<KeysViewHDF5 ['feature', 'token']>
(3, 23, 543)
[1]
4.2 モジュールのダウンロード
次に,過去の記事で実装したコードをダウンロードします.
本項は前回までに紹介した内容と同じですので,飛ばしていただいても構いません.
コードはGithubのsrc/modules_gislrにアップしてあります (今後の記事で使用するコードも含まれています).
まず,下記のコマンドでレポジトリをダウンロードします.
(目的のディレクトリだけダウンロードする方法はまだ調査中です(^^;))
!wget https://github.com/takayama-rado/trado_samples/archive/refs/tags/v0.1.zip -O master.zip
--2024-01-21 11:01:47-- https://github.com/takayama-rado/trado_samples/archive/master.zip
Resolving github.com (github.com)... 140.82.112.3
...
2024-01-21 11:01:51 (19.4 MB/s) - ‘master.zip’ saved [75710869]
ダウンロードしたリポジトリを解凍します.
!unzip -o master.zip -d master
Archive: master.zip
641b06a0ca7f5430a945a53b4825e22b5f3b8eb6
creating: master/trado_samples-main/
inflating: master/trado_samples-main/.gitignore
...
モジュールのディレクトリをカレントディレクトリに移動します.
!mv master/trado_samples-main/src/modules_gislr .
他のファイルは不要なので削除します.
!rm -rf master master.zip gislr_top10.zip
!ls
dataset_top10 drive modules_gislr sample_data
4.3 モジュールのロード
主要な処理の実装に先立って,下記のコードでモジュールをロードします.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
【コード解説】
- 標準モジュール
- copy: データコピーライブラリ.Transformerブロック内でEncoder層をコピーするために使用します.
- json: JSONファイル制御ライブラリ.辞書ファイルのロードに使用します.
- math: 数学計算処理ライブラリ
- sys: Pythonインタプリタの制御ライブラリ.
今回はローカルモジュールに対してパスを通すために使用します.
- functools: 関数オブジェクトを操作するためのライブラリ.
今回はDataLoaderクラスに渡すパディング関数に対して設定値をセットするために使用します.
- inspect.signature: オブジェクトの情報取得ライブラリ.
- pathlib.Path: オブジェクト指向のファイルシステム機能.
主にファイルアクセスに使います.osモジュールを使っても同様の処理は可能です.
高山の好みでこちらのモジュールを使っています(^^;).
- typing: 関数などに型アノテーションを行う機能.
ここでは型を忘れやすい関数に付けていますが,本来は全てアノテーションをした方が良いでしょう(^^;).
- 3rdパーティモジュール
- numpy: 行列演算ライブラリ
- torch: ニューラルネットワークライブラリ
- torchvision: PyTorchと親和性が高い画像処理ライブラリ.
今回はDatasetクラスに与える前処理をパッケージするために用います.
- ローカルモジュール: sys.pathにパスを追加することでロード可能
- dataset: データセット操作用モジュール
- defines: 各部位の追跡点,追跡点間の接続関係,およびそれらへのアクセス処理を
定義したモジュール
- layers: ニューラルネットワークのモデルやレイヤモジュール
- transforms: 入出力変換処理モジュール
- train_functions: 学習・評価処理モジュール
5. 認識モデルの実装
5.1 Positional encoding
ここから先は,認識モデルを実装していきます.
まずは,次のコードでPE層を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
【コード解説】
- 引数
- dim_model: 入力特徴量の次元数
- dropout: Dropout層の欠落率
- max_len: 位置信号を生成する長さ (入力可能な最大長)
- 6-17行目: 初期化処理
- 9-15行目: 位置信号を事前生成して記憶.
学習/推論時は計算処理をスキップできますので高速に動作します.
11行目の処理は長い系列が入力された場合のオーバーフロウを避けるためです.
一旦対数空間で計算を行い,その後指数関数を適用して望む値に変換しています.
- 19-23行目: 推論処理
5.2 Multi-head attention
次のコードでMHA層を実装します.
下記のコードでは,軸の入れ替えなどの煩雑な操作を減らすために,行列積を einsum() 関数で実装しています.
einsum() 関数についてはこちらに簡単な解説記事を用意しています.
ご一読いただければうれしいです.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | |
【コード解説】
- 引数:
- key_dim: Key値の入力次元数.Self-attentionでは `query_dim` と同じ値にします.
Cross-attentionでは主要入力 (Decoder側の入力) の次元数を設定します.
- query_dim: Query値の入力次元数.Self-attentionでは `key_dim` と同じ値にします.
Cross-attentionでは補助入力 (Encoder側の出力) の次元数を設定します.
- att_dim: 内部処理の特徴量次元数.`num_heads` で割り切れる値なければなりません.
- out_dim: 出力次元数
- num_heads: 異なるアテンション重みを計算するためのヘッド数
- dropout: Dropout層の欠落率
- add_bias: Trueの場合,線形変換層にバイアス項を導入する
- 10-25行目: 初期化処理.基本的には内部で使用する変数と層を準備しています.
- 27-36行目: 線形変換層のパラメータ初期化処理.Fairseqの初期化処理を参考にしています.
https://github.com/facebookresearch/fairseq/blob/main/fairseq/modules/multihead_attention.py
- 38-79行目: 推論処理
- 43-45行目: マスキング値の初期化.
Softmax関数は通常のマスキング値 (0など) を有効な数値に変換してしまうので,
計算後の重みが0になるように,負の最小値を設定します.
入力の型をハードコーディングすると移植性が悪くなるので,最初の入力の時に型を
判定するように実装しています.
- 53-55行目: `key`, `value`, `query` それぞれに線形変換を適用
- 58行目: `query` と `key` の行列積を計算.通常の計算だと軸の入れ替えで処理が
煩雑になるため,einsum()で実装しています.
- 61-67行目: Paddin箇所などマスキングを行う部分に対して,`neg_inf` を代入しています.
代入箇所はsoftmax()処理内で0に変換されます.
- 69-70行目: Attention重みを計算してDropoutを適用
- 74行目: Attention重みと `value` の行列積を計算.通常の計算だと軸の入れ替え
で処理が煩雑になるため,einsum()で実装しています.
- 75-76行目: 出力特徴量の形状を整えて線形変換を適用
- 78-79行目: Attention重みの形状を整えて結果を返す
5.3 Position-wise feed-forward
本項ではPFFN層を実装します.
まず,次のコードでReLUタイプの活性化関数を選択できるようにします.
ReLUタイプの活性化関数は数多く提案されていますが,本記事ではパラメータが要らない手法を実装しています.
(なお,本記事では活性化関数毎の比較実験は行いません)
1 2 3 4 5 6 7 8 9 10 11 12 | |
次のコードでPFFN層を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
【コード解説】
- 引数
- dim_model: 入力特徴量の次元数
- dim_ffw: 1層目の線形変換後の特徴量次元数
- dropout: Dropout層の欠落率
- activation: 活性化関数の種別を指定 [relu/gelu/swish/silu/mish]
- add_bias: Trueの場合,線形変換層にバイアス項を導入する
- 8-15行目: 初期化処理
- 17-21行目: 推論処理
5.4 Transformer encoder layer
本項と次項では,Transformerのencoderを実装します.
Transformer-Encoderでは,encoder層を指定数分カスケード接続します.
本記事では,まず本項でencoder層のクラスを実装し,次項でencoder層をカスケード接続して処理ブロックとして仕上げるクラスを実装します.
次のコードでは,self-attention用にマスキング配列を拡張しています.
1 2 3 4 5 6 7 | |
具体的には,Padding用のマスキング配列を [N, T] -> [N, T, T] 形状に拡張した上で,causal_mask との論理積を計算します.
causal_mask は各フレームに対してAttentionの計算対象となる他フレーム箇所を指定するためのマスキング配列です.
causal_mask を使用すると,未来のフレームに対してはAttentionの計算から除外するなどの処理ができます.
(翻訳やオンライン認識などで必要な機能です.本記事では使用しません)
次に,下記のコードでencoder層を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 | |
【コード解説】
- 引数
- dim_model: 入力特徴量の次元数
- num_heads: MHAのヘッド数
- dim_ffw: PFFNの内部特徴次元数
- dropout: Dropout層の欠落率
- activation: 活性化関数の種別を指定 [relu/gelu/swish/silu/mish]
- layer_norm_eps: LN層内で0除算を避けるための定数
- norm_first: Trueの場合,Pre-LN構成を用いる
- add_bias: Trueの場合,線形変換層とLN層にバイアス項を適用.
ただし,LN層がバイアス項に対応していない場合 (古いPyTorch) は無視します.
- 11-44行目: 初期化処理.
基本的には各層をインスタンス化するだけですが,36-41行目では,LayerNormの
インスタンス化処理で `bias` 引数が入力できるかを調べて処理を切り替えています.
- 46-75行目: Pre-LN構成の推論処理. 処理の流れについては図2(c) をご参照ください.
- 77-104行目: 標準構成の推論処理. 処理の流れについては図2(b) をご参照ください.
- 106-123行目: 推論処理
- 111-116行目: MHSA用のマスキング配列を作成
- 118-121行目: `norm_first` の値によって推論処理を切り替え
5.5 Transformer encoder block
次のコードで,Transformer-Encoderブロックを実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |
【コード解説】
- 引数
- encoder_layer: インスタンス化済みのTransformerEncoderLayerオブジェクト.
このオブジェクトは内部で `num_layers` 分コピーされて,カスケード接続されます.
- num_layers: encoder層の数を指定
- dim_model: 入力特徴量の次元数
- dropout_pe: PE層で使用するDropout層の欠落率
- layer_norm_eps: LN層内で0除算を避けるための定数
- norm_first: この変数がTrueで,かつ,`add_tailnorm`がTrueの場合は末尾に
LN層を追加 (実装中は気づきませんでしたが,この変数はいりませんでしたね(^^;))
- add_bias: Trueの場合,末尾のLN層にバイアス項を適用する
- add_tailnorm: この変数がTrueで,かつ,`norm_first`がTrueの場合は末尾に
LN層を追加 (実装中は気づきませんでしたが,この変数だけでよかったです(^^;))
- 11-29行目: 初期化処理
基本的には各層をインスタンス化するだけですが,23-27行目では,LayerNormの
インスタンス化処理で `bias` 引数が入力できるかを調べて処理を切り替えています.
- 31-41行目: 推論処理
5.6 認識モデル
次のコードで,認識モデル全体を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | |
【コード解説】
- 引数
- in_channels: 入力特徴量の次元数
- inter_channels: 内部特徴量の次元数
- out_channels: 出力特徴量の次元数.単語応答値を出力したいので,全単語数と同じにします.
- activation: 活性化関数の種別を指定 [relu/gelu/swish/silu/mish]
- tren_num_layers: Transformerの層数
- tren_num_heads: Transformer内部で使用するMHSA層のヘッド数
- tren_dim_ffw: Transformer内部で使用するPFFN層の内部特徴次元数
- tren_dropout_pe: Transformer内部で使用するPE層のDropout層欠落率
- tren_dropout: Transformer内部で使用する各encoder層のDropout層欠落率
- tren_layer_norm_eps: Transformer内部で使用するLN層の,0除算を避けるための定数
- tren_norm_first: Trueの場合,Pre-LN構成でencoder層を作成
- tren_add_bias: Trueの場合,線形変換層とLN層でバイアス項を適用.
ただし,LN層がバイアス項に対応していない場合 (古いPyTorch) は無視します.
- tren_add_tailnorm: この変数がTrueで,かつ,`tren_norm_first`がTrueの場合は末尾に
LN層を追加
- 16-42行目: 初期化処理
- 44-72行目: 推論処理.
大量の`isnan()` は実装間違いを発見するために入れておいたのを削除し忘れただけです(^^;).
5.7 動作チェック
認識モデルの実装ができましたので,動作確認をしていきます.
次のコードでデータセットからHDF5ファイルとJSONファイルのパスを読み込みます.
1 2 3 4 5 6 7 8 | |
dataset_top10/sign_to_prediction_index_map.json
[PosixPath('dataset_top10/2044.hdf5'), PosixPath('dataset_top10/32319.hdf5'), PosixPath('dataset_top10/18796.hdf5'), PosixPath('dataset_top10/36257.hdf5'), PosixPath('dataset_top10/62590.hdf5'), PosixPath('dataset_top10/16069.hdf5'), PosixPath('dataset_top10/29302.hdf5'), PosixPath('dataset_top10/34503.hdf5'), PosixPath('dataset_top10/37055.hdf5'), PosixPath('dataset_top10/37779.hdf5'), PosixPath('dataset_top10/27610.hdf5'), PosixPath('dataset_top10/53618.hdf5'), PosixPath('dataset_top10/49445.hdf5'), PosixPath('dataset_top10/30680.hdf5'), PosixPath('dataset_top10/22343.hdf5'), PosixPath('dataset_top10/55372.hdf5'), PosixPath('dataset_top10/26734.hdf5'), PosixPath('dataset_top10/28656.hdf5'), PosixPath('dataset_top10/61333.hdf5'), PosixPath('dataset_top10/4718.hdf5'), PosixPath('dataset_top10/25571.hdf5')]
次のコードで辞書ファイルをロードして,認識対象の単語数を格納します.
1 2 3 4 5 | |
次のコードで前処理を定義します.
今回は,以前に説明した追跡点の選定と,追跡点の正規化を前処理として適用して実験を行います.
1 2 3 4 5 6 7 8 9 10 | |
次のコードで,前処理を適用したHDF5DatasetとDataLoaderをインスタンス化し,データを取り出します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
torch.Size([2, 2, 89, 130])
次のコードでモデルをインスタンス化して,動作チェックをします.
追跡点抽出の結果,入力追跡点数は130で,各追跡点はXY座標値を持っていますので,入力次元数は260になります.
出力次元数は単語数なので10になります.
また,Transformer層の入力次元数は64に設定し,PFFN内部の拡張次元数は256に設定しています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
TransformerEnISLR(
(linear): Linear(in_features=260, out_features=64, bias=True)
(activation): ReLU()
(tr_encoder): TransformerEncoder(
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(ffw): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(dropout): Dropout(p=0.1, inplace=False)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
)
(norm): Identity()
)
(head): GPoolRecognitionHead(
(head): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([2, 10])
(2, 2, 88, 88) (2, 2, 88, 88)
6. 学習と評価
6.1 共通設定
では,実際に学習・評価を行います.
まずは,実験全体で共通して用いる設定値を次のコードで実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Using 2 cores for data loading.
Using cpu for computation.
次のコードで学習・バリデーション・評価処理それぞれのためのDataLoaderクラスを作成します.
1 2 3 4 5 6 7 8 9 10 11 | |
6.2 学習・評価の実行
次のコードでモデルをインスタンス化します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
TransformerEnISLR(
(linear): Linear(in_features=260, out_features=64, bias=True)
(activation): ReLU()
(tr_encoder): TransformerEncoder(
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(ffw): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(dropout): Dropout(p=0.1, inplace=False)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
)
(norm): Identity()
)
(head): GPoolRecognitionHead(
(head): Linear(in_features=64, out_features=10, bias=True)
)
)
次のコードで学習・評価処理を行います.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Start training.
--------------------------------------------------------------------------------
Epoch 1
Start training.
loss:3.698159 [ 0/ 3881]
loss:2.050613 [ 3200/ 3881]
Done. Time:62.87062674399999
Training performance:
Avg loss:2.281008
Start validation.
Done. Time:3.945381327000007
Validation performance:
Avg loss:2.086610
Start evaluation.
Done. Time:1.8634476569999947
Test performance:
Accuracy:21.5%
--------------------------------------------------------------------------------
...
--------------------------------------------------------------------------------
Epoch 50
Start training.
loss:0.142570 [ 0/ 3881]
loss:0.179582 [ 3200/ 3881]
Done. Time:62.715259724000134
Training performance:
Avg loss:0.266712
Start validation.
Done. Time:3.6063792339996326
Validation performance:
Avg loss:0.612470
Start evaluation.
Done. Time:1.7318391850003536
Test performance:
Accuracy:76.0%
Minimum validation loss:0.605905430657523 at 43 epoch.
Maximum accuracy:82.0 at 47 epoch.
以後,同様の処理をレイヤ構成毎に繰り返します.
コード構成は同じですので,ここでは説明を割愛させていただきます.
また,この後グラフ等の描画も行っておりますが,本記事の主要点ではないため説明を割愛させていただきます.
今回はTransformer層を用いた孤立手話単語認識モデルを紹介しましたが,如何でしたでしょうか?
いやー長いですね.すみません(^^;).
これでも結構端折ったつもりなんですが,今までと違って全ての処理を一度に実装する都合上,どうしても削りづらい箇所が多くなってしまいました.
それでも何とかTransformerの記事を書くことができて,一安心です.
やっと現在の研究開発現場で取り組まれているアプローチ (の入口) まで辿り着くことができました(^^).
Transformerは現在の手話認識/翻訳分野で中心的な位置を占めるアプローチの一つで,毎年様々な改良手法が提案されています.
今回は標準的なTransformerを単純に適用しただけですが,今後色々な改良手法も紹介していければと思っています.
今回紹介した話が,これから手話認識を勉強してみようとお考えの方に何か参考になれば幸いです.




