目次
こんにちは.高山です.
実践手話認識 - モデル開発編の第五回になります.
第四回に引き続き,今回もGAFS データセットを用いて連続指文字認識モデルを学習してみたいと思います.
具体的には,Transformer Encoder-Decoder [Vaswani'17] を用いた連続指文字認識モデルの実装方法を紹介します.
下記に示すように,Transformer については孤立手話単語認識を題材にして,複数回に分けて解説をしてきました.
- Transformerを用いた孤立手話単語認識モデル
- 補足5: 深掘りTransformer1: Positional encoding の処理について
- 補足6: 深掘りTransformer2: Multi-head self-attention の処理について
- 補足7: 深掘りTransformer3: 正規化層について
- 補足8: 深掘りTransformer4: 欠損値の補間は認識性能を向上させるのか?
- 補足10: 深掘りTransformer5: GISLRタスクに合う正規化層は何か?
Position-wise feed forward (PFFN) や Multi-head self-attention (MHSA) などの Transformer の構成要素は解説済みですので,今回は Encoder-Decoder の実装に注力して解説していきたいと思います.
今回はモデルの実装と実験に注力して説明します.
学習処理全体の実装は,Encoder-Decoder 解説記事をご参照ください.
今回解説するスクリプトはGitHub上に公開しています.
ただし,説明で使用しているデータセットは,配布可能な容量にするために大部分のデータを削除しています.
デバッグには使用できますが,学習は安定しませんのでご注意ください.
- [Vaswani'17]: A. Vaswani, et al., "Attention Is All You Need," Proc. of the NIPS, available here, 2017.
1. Transformer Encoder-Decoderの処理
1.1 全体構成
Transformer Encoder-Decoder を基にした連続指文字認識モデルの構成図を図1に示します.
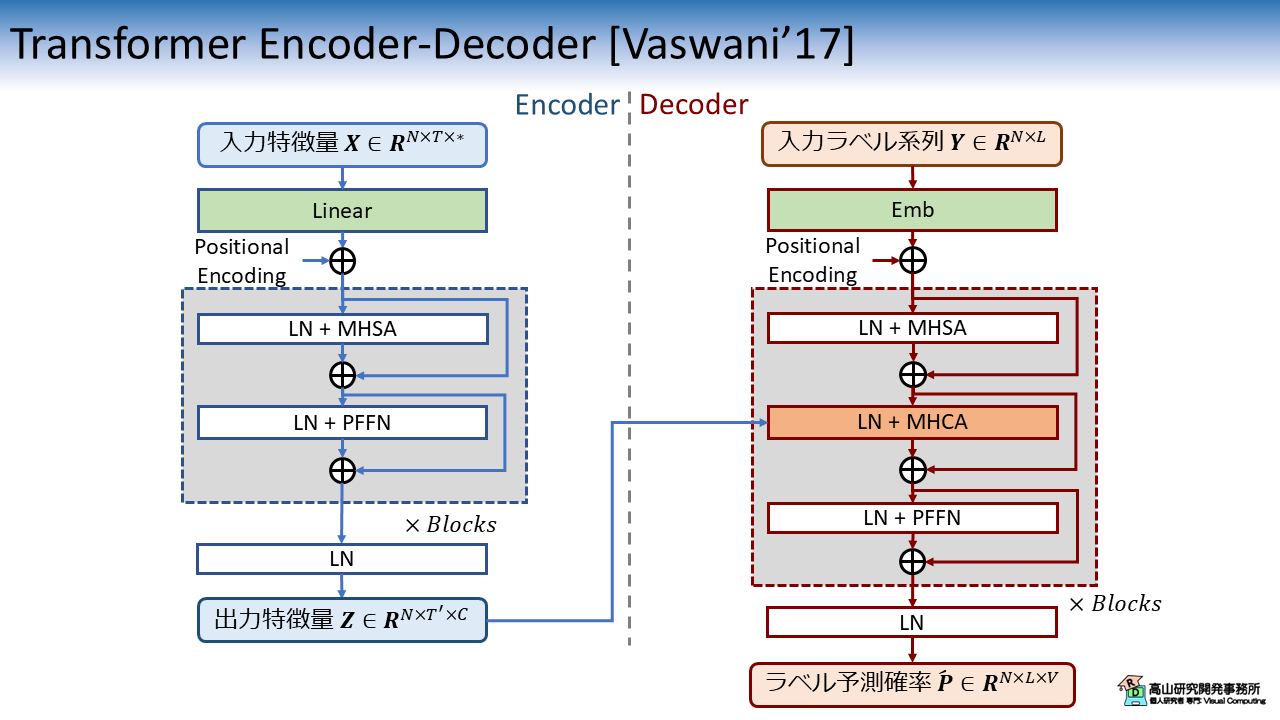
上記のモデルは,Encoder と Decoder の双方を Transformer の処理ブロックで構成します.
Decoder には,Encoder の出力と ラベル系列を基に Attention を計算する,Multi-head cross-attention (MHCA) が備わっています.
Encoder では MHSA と PFFN から成る処理ブロックを適用して,入力系列 \(\boldsymbol{x}_t\) の特徴変換を行います.
変換後の特徴系列 \(\boldsymbol{Z} \in \boldsymbol{R}^{N \times T' \times C}\) は Decoder の MHCA 層へ入力されます.
Decoder では MHSA, MHCA, および PFFN から成る処理ブロックを適用して,現在の入力ラベル \(\boldsymbol{y}_l\) から次のラベル予測確率 \(\hat{\boldsymbol{p}}_{l}\) を出力します.
(正確には確率化前の応答値を出力します)
なお,"Emb" は Embedding 層を指し,離散数値をモデルが扱いやすい多次元特徴量に変換します.
- [Vaswani'17]: A. Vaswani, et al., "Attention Is All You Need," Proc. of the NIPS, available here, 2017.
1.2 Decoder の動作
Encoder の動作は Transformerを用いた孤立手話単語の記事で説明しました.
本項では Decoder の動作を主に説明します.
テスト時の推論処理
テスト時の動作から説明した方が分かりやすいため,まず図2にテスト時の動作概略図を示します.
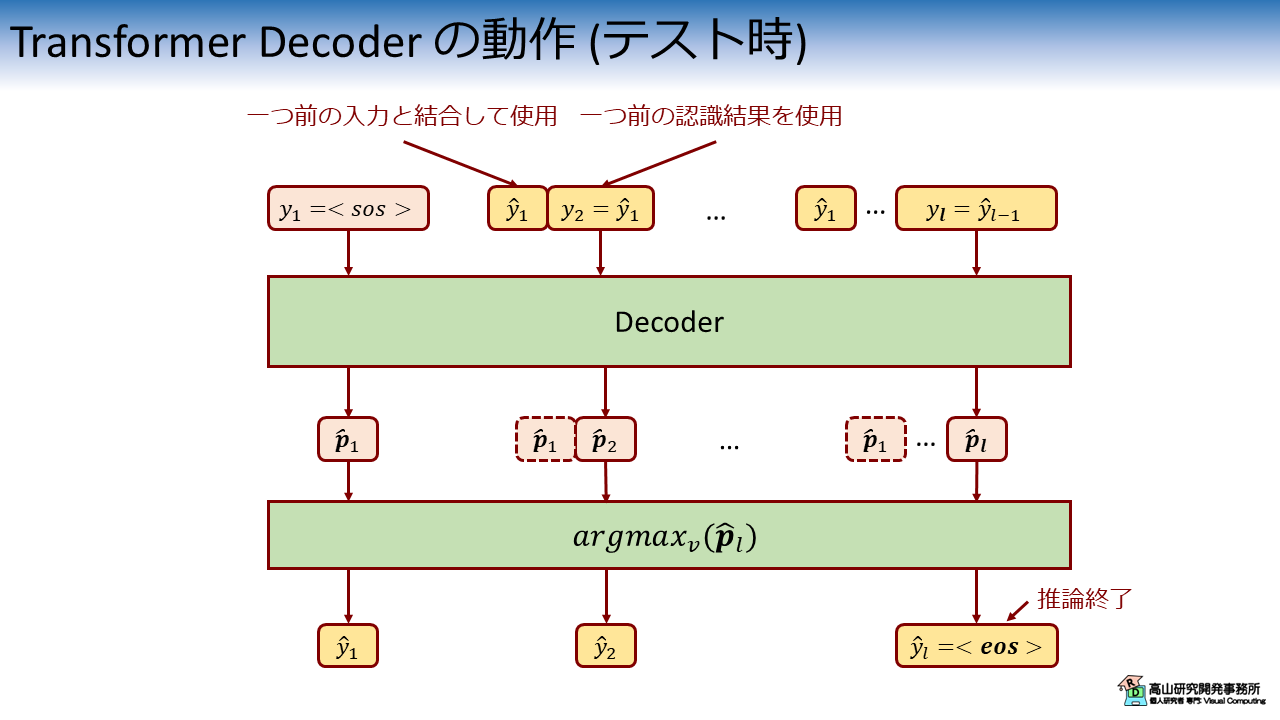
Encoder-Decoder の説明記事で紹介したとおり (第2.1項と第2.2項をご参照ください),Decoder では次のラベルを予測しながらラベルを順次入力していくことで時系列を認識します.
図2に示すとおり,テスト時の推論ではまず Decoder にラベル系列の始まりを示すキーワードラベルを入力します.
(ここでは"\(\text{<sos>}\): start of sequence" としています)
Decoder の出力 \(\hat{\boldsymbol{p}_1}\) は次のラベルの予測確率を示しており,内部には各ラベルへの応答値が並んでいます.
\(argmax(\cdot)\) は最大値を与えるインデクスを返す関数です.
この処理を \(\hat{\boldsymbol{p}}_l\) に適用すると,最大の応答値を与えるラベル (ラベルの数値とインデクスを揃えるので) \(\hat{y}_l\) が得られます.
得られた結果を 2番目以降の入力で用います.
RNN Encoder-Decoder では,RNN の隠れ状態が過去のラベル情報を保持していますが,Transformer にはそのような機構は組み込まれていません.
そこで Transformer では,過去から現在までのラベル系列を結合して同時に推論することで,過去の情報を参照しながら次のラベルを予測できるようにしています.
なお,このとき Decoder は過去のラベル系列のラベル予測値も改めて算出しますが,次のラベル予測値だけを残して残りは棄却します.
上記の処理を繰り返して,Decoder が終了キーワード "\(\text{<eos>}\)" を出力したら,推論を終了します (そのように処理を組みます).
学習時の推論処理
図3に学習時の推論処理の概略図を示します.

学習時は推論時間短縮のために,ラベル系列 \(\boldsymbol{Y}\) をまとめて入力し,予測確率の系列 \(\boldsymbol{P}\) を得ます.
このとき,図3右側に示す Causal mask を同時に入力します.
Causal mask は各時点のラベルが推論に利用できる過去ラベルの箇所を指定するマスク配列です.
例えば,1 番目のラベルは自身の値だけを推論に利用でき,2番目のラベルは自身と 1個前のラベルを推論に利用できます.
実装上は,MHSA 内で Softmax 関数を適用する前の Attention score に対してマスキングを行うことで,各時点のラベルは指定した箇所だけを参照するようになります.
MHSA の計算処理については,MHSA の解説記事をご参照ください (第3.3項の処理内でマスキングを行います).
上記の処理によって,1度の推論でテスト時の推論動作をシミュレートすることができます.
1.3 Decoder attention の出力例
図4に Decoder の MHSA と MHCA の Attention 出力例を示します.
各層の細かな処理内容については,MHSA 解説記事 と MHCA 解説記事にそれぞれまとめましたので,併せてご一読いただければうれしいです.
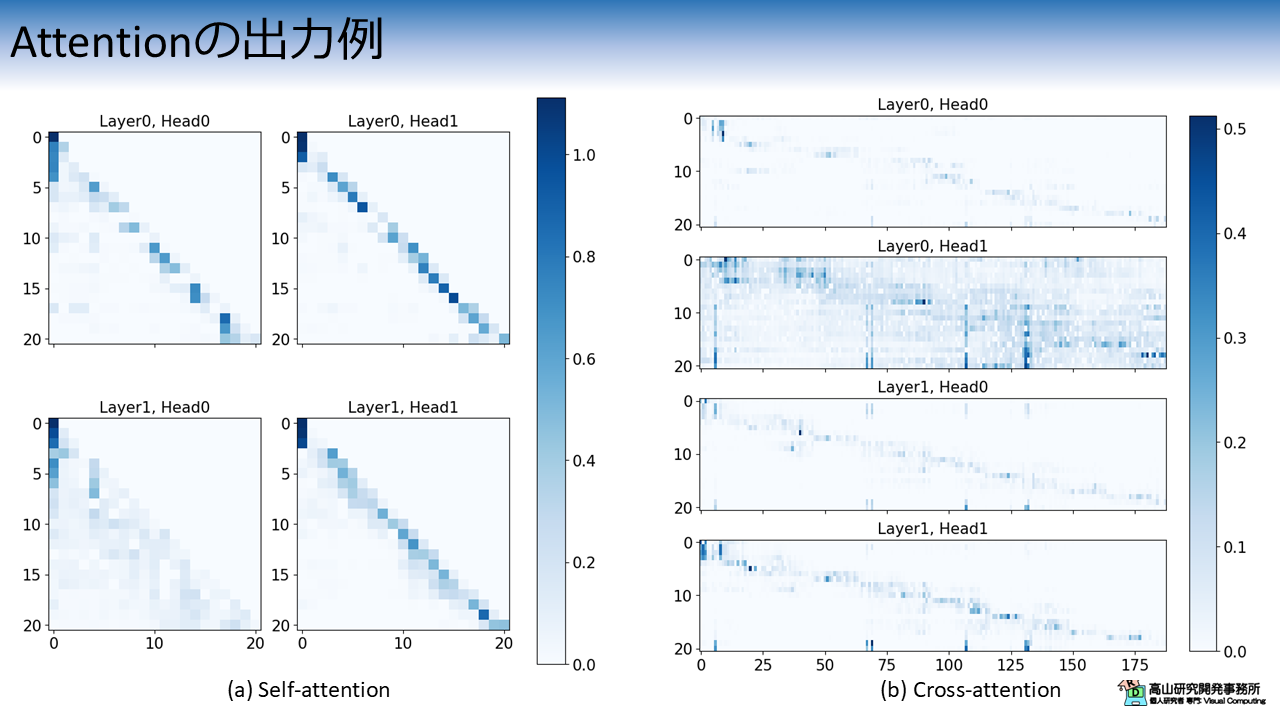
MHSA の出力結果から,Causal mask によって処理対象よりも後の時点のラベルについては,重みがゼロクリアされていることが分かります.
MHCA の出力結果からは,推論の進行に伴って重みのピークが後ろフレームにずれていっていることが見て取れます.
また,各層とヘッドの重みから分かるように,Multi-head 機構を用いることでそれぞれ異なる箇所に重み付けを行うことができます.
Bahdanaru attention [Bahdanau'15] などの Single-head の attention よりも入力の関係性を柔軟にとらえることができるため,認識性能の向上が期待できます.
- [Bahdanau'15]: D. Bahdanau, et al., "Neural Machine Translation by Jointly Learning to Align and Translate," Proc. of the ICLR, available here, 2015.
1.4 実装上の注意点
Neural network の学習結果は,各層のパラメータ初期値に大きく左右されます.
PyTorch に実装済みのレイヤの多くは標準的な初期化処理が自動で適用されるようになっているため,今までの解説記事では取り上げませんでした.
しかし今回使用する Embedding 層は,手動で設定しない場合は標準正規分布で初期化する仕様になっています.
予備実験の結果から,この初期化処理を用いた場合は学習結果が不安定になる傾向があったため,今回は Fairseq という時系列処理用ライブラリで採用されているパラメータ初期化方法を用います.
2. 実験結果
次節以降では,実装の紹介をしていきます.
実装部分はかなり長いので結果を先にお見せしたいと思います.
説明で使用しているデータセットは容量をかなり削っていて学習が不安定ですので,ここでは全データセットを用いた結果だけ示します.
今回の実験では学習を安定させるために,ラベルスムージングと各種のデータ拡張処理を導入しています.
これらの処理については「手話認識入門」の記事で解説しているので,よろしければご一読ください.
学習エポック数は 50,バッチ数は 128 に設定しています.
図5は,Validation Loss と単語誤り率の推移を示しています.
連続指文字認識のような時系列認識タスクの評価には,単語誤り率 (WER: Word error rate) がよく用いられます.
WER については WERに関する補足記事で説明していますので,併せてご一読いただたらうれしいです.
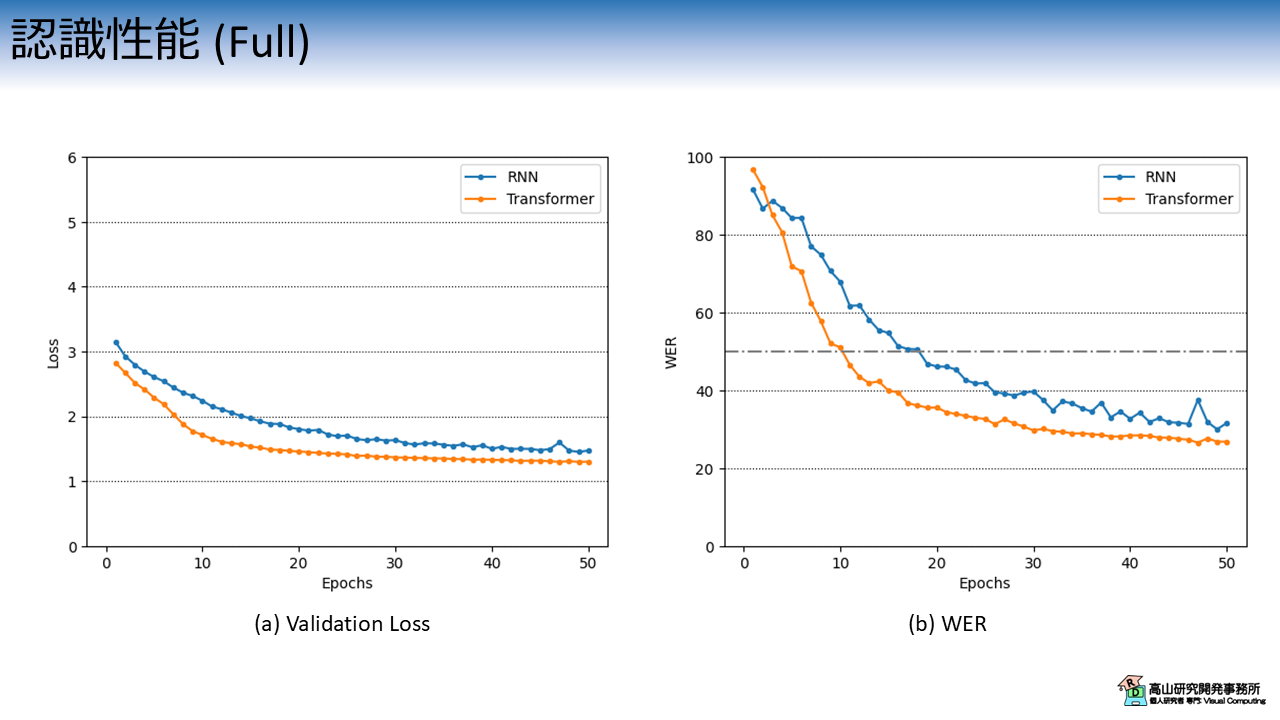
横軸は学習・評価ループの繰り返し数 (Epoch) を示し,縦軸は評価指標を示します.
各線の色と実験条件の関係は次のとおりです.
- 青線 (RNN): RNN Encoder-Decoder with attention
- 橙線 (Transformer): Transformer Encoder-Decoder
RNN と Transformer の学習パラメータ数が比較的近くなるように,Transformer の内部特徴次元数は \(80\) に設定しています.
実験結果から,Transformer の方が RNN よりも良い認識性能であることが分かります.
最終的な性能は \(\text{WER}=26.6\%\) 程度でしたので,約 \(73.4\%\) 程度は正しい指文字が認識できていることになります.
なお,今回の実験では話を簡単にするために,実験条件以外のパラメータは固定にし,乱数の制御もしていません.
必ずしも同様の結果になるわけではないので,ご了承ください.
3. 前準備
3.1 データセットのダウンロード
ここからは実装方法の説明をしていきます.
まずは,前準備として Google Colab にデータセットをアップロードします.
まず最初に,データセットの格納先からデータをダウンロードし,ご自分の Google drive へアップロードしてください.
次のコードで Google drive を Colab へマウントします.
Google Drive のマウント方法については,補足記事にも記載してあります.
1 2 3 | |
ドライブ内のファイルを Colab へコピーします.
パスはアップロード先を設定する必要があります.
# Copy to local.
!cp ./drive/MyDrive/Datasets/gafs_dataset_very_small.zip gafs_dataset.zip
データセットは ZIP 形式になっているので unzip コマンドで解凍します.
!unzip -o gafs_dataset.zip
Archive: gafs_dataset.zip
creating: gafs_dataset_very_small/
inflating: gafs_dataset_very_small/0.hdf5
...
inflating: gafs_dataset_very_small/LICENSE.txt
成功すると gafs_dataset_very_small 以下にデータが解凍されます.
HDF5 ファイルはデータ本体で,手話者毎にファイルが別れています.
JSON ファイルは辞書ファイルで,TXT ファイルは本データセットのライセンスです.
!ls gafs_dataset_very_small
0.hdf5 135.hdf5 ... character_to_prediction_index.json LICENSE.txt
辞書には指文字名と数値の関係が 59 種類分定義されています.
!cat gafs_dataset_very_small/character_to_prediction_index.json
{
" ":0,
"!":1,
...
"~":58
}
ライセンスはオリジナルと同様に,CC-BY 4.0 としています.
!cat gafs_dataset_very_small/LICENSE.txt
The dataset provided by Natsuki Takayama (Takayama Research and Development Office) is licensed under CC-BY 4.0.
Author: Copyright 2024 Natsuki Takayama
Title: GASF very small dataset
Original licenser: Google LLC
Modification
- Extract only 3 parquet file.
- Packaged into HDF5 format.
次のコードでサンプルを確認します.
サンプルは辞書型のようにキーバリュー形式で保存されており,下記のように階層化されています.
- サンプルID (トップ階層のKey)
|- feature: 入力特徴量で `[C(=2), T, J(=543)]` 形状.C,T,Jは,それぞれ特徴次元,フレーム数,追跡点数です.
|- token: 指文字ラベル系列で `[L]` 形状.0から58の数値です.
なお,データ量削減のため,入力特徴は \((x, y)\) 座標になっており \(z\) 座標は含んでいません.
1 2 3 4 5 6 7 8 9 10 | |
['1720198121', '1722303176', '1723157122', '1731934631', '1737624109', '1739256200', '1743069372', '1743412187', '1744795751', '1746320345']
<KeysViewHDF5 ['feature', 'token']>
(2, 271, 543)
[14 38 32 45 44 36 40 32 43 43 36 56 14 43 40 45 32 12 34 32 49 50 51 36
45 50]
3.2 モジュールのダウンロード
次に,過去の記事で実装したコードをダウンロードします.
コードは Githubのsrc/modules_gislr にアップしてあります (今後の記事で使用するコードも含まれています).
まず,下記のコマンドでレポジトリをダウンロードします.
今後のアップデートを考慮してバージョン指定をしていますので注意してください.
!wget https://github.com/takayama-rado/trado_samples/archive/refs/tags/v0.3.6.zip -O master.zip
--2024-09-21 02:16:50-- https://github.com/takayama-rado/trado_samples/archive/refs/tags/v0.3.6.zip
...
2024-09-21 02:16:57 (12.4 MB/s) - ‘master.zip’ saved [80305369]
ダウンロードしたリポジトリを解凍します.
!unzip -o master.zip -d master
Archive: master.zip
5b1307e0c758e696f5e99e0c804b29b32d061333
creating: master/trado_samples-0.3.6/
inflating: master/trado_samples-0.3.6/.gitignore
...
モジュールのディレクトリをカレントディレクトリに移動します.
!mv master/trado_samples-0.3.6/src/modules_gislr .
他のファイルは不要なので削除します.
!rm -rf master master.zip gafs_dataset_very_small.zip
!ls
drive gafs_dataset_very_small gafs_dataset.zip modules_gislr sample_data
3.3 モジュールのロード
主要な処理の実装に先立って,下記のコードでモジュールをロードします.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | |
【コード解説】
- 標準モジュール
- copy: データコピーライブラリ.Macaron Netブロック内でEncoder層をコピーするために使用します.
- json: JSONファイル制御ライブラリ.辞書ファイルのロードに使用します.
- math: 数学処理ライブラリ.
- os: システム処理ライブラリ.
- sys: Pythonインタプリタの制御ライブラリ.
今回はローカルモジュールに対してパスを通すために使用します.
- time: 時刻処理ライブラリ.処理時間計測に使用します.
- functools: 関数オブジェクトを操作するためのライブラリ.
今回はDataLoaderクラスに渡すパディング関数に対して設定値をセットするために使用します.
- inspect.signature: オブジェクトの情報取得ライブラリ.
- pathlib.Path: オブジェクト指向のファイルシステム機能.
主にファイルアクセスに使います.osモジュールを使っても同様の処理は可能です.
高山の好みでこちらのモジュールを使っています(^^;).
- 3rdパーティモジュール
- numpy: 行列演算ライブラリ
- nltk: 自然言語処理ライブラリ.WERを計算するために使用します.
- torch: ニューラルネットワークライブラリ
- torchvision: PyTorchと親和性が高い画像処理ライブラリ.
今回はDatasetクラスに与える前処理をパッケージするために用います.
- ローカルモジュール: sys.pathにパスを追加することでロード可能
- dataset: データセット操作用モジュール
- defines: 各部位の追跡点,追跡点間の接続関係,およびそれらへのアクセス処理を
定義したモジュール
- layers: ニューラルネットワークのモデルやレイヤモジュール
- transforms: 入出力変換処理モジュール
- train_functions: 学習・評価処理モジュール
- utils: 汎用処理関数モジュール
次に,学習処理に関するモジュールをロードします.
実装の都合で,学習処理が呼び出す推論関数はここで実装し,モジュールに対してパッチを当てて置き換えます.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
コード末尾でロードしている train_functions は学習・評価処理モジュールで,内部で上記の forward() と inference() を呼び出します.
モジュールと上記関数の関係については,Encoder-Decoder 解説記事の第4.3項をご参照ください.
基本的には,学習とテスト時に併せてモデルの各推論関数を呼び出すだけですが,学習時は Causal mask を生成している点に注意してください (5-8行目).
Causal mask は時系列長が同じ場合は同一ですので,冗長なデータ生成を避ける処理をいれています.
4. 認識モデルの実装
4.1 Transformer Decoder layer
第1.2項で説明した Transformer decoder を実装します.
Encoder と同じく Transformer Decoder では,decoder 層を指定数分カスケード接続します.
まず本項で decoder 層のクラスを実装し,次項で decoder 層をカスケード接続して処理ブロックとして仕上げるクラスを実装します.
まずは,下記のコードで 1層分の Decoder 層を実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 | |
【コード解説】
- 引数
- dim_model: 入力特徴量の次元数
- num_heads: MHAのヘッド数
- dim_ffw: PFFNの内部特徴次元数
- dropout: Dropout層の欠落率
- activation: 活性化関数の種別を指定 [relu/gelu/swish/silu/mish]
- norm_type_sattn: MHSAブロックの正規化層種別を指定 [batch/layer]
- norm_type_cattn: MHCAブロックの正規化層種別を指定 [batch/layer]
- norm_type_ffw: PFFNブロックの正規化層種別を指定 [batch/layer]
- norm_eps: LN層内で0除算を避けるための定数
- norm_first: Trueの場合,Pre-LN構成を用いる
- add_bias: Trueの場合,線形変換層とLN層にバイアス項を適用.
ただし,LN層がバイアス項に対応していない場合 (古いPyTorch) は無視します.
- 14-59行目: 初期化処理.
- 61-102行目: Pre-LN構成の推論処理.
- 104-144行目: 標準構成の推論処理.
- 146-176行目: 推論処理
- 155-167行目: MHSA用,および MHCA用のマスキング配列を作成
- 169-174行目: `norm_first` の値によって推論処理を切り替え
4.2 Transformer decoder block
次のコードで Decoder 処理ブロックを実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | |
【コード解説】
- 引数
- decoder_layer: インスタンス化済みのTransformerDecoderLayerオブジェクト.
このオブジェクトは内部で `num_layers` 分コピーされて,カスケード接続されます.
- out_channels: 出力次元数.
通常は認識対象ラベルの数に合わせます.
- num_layers: decoder層の数を指定
- dim_model: 入力特徴量の次元数
- dropout_pe: PE層で使用するDropout層の欠落率
- norm_type_tail: Decoder ブロック末尾の正規化層種別を指定 [batch/layer]
- norm_eps: LN層内で0除算を避けるための定数
- norm_first: この変数がTrueで,かつ,`add_tailnorm`がTrueの場合は末尾に
LN層を追加
- add_bias: Trueの場合,末尾のLN層にバイアス項を適用する
- add_tailnorm: この変数がTrueで,かつ,`norm_first`がTrueの場合は末尾に
LN層を追加
- 14-35行目: 初期化処理
基本的には各層をインスタンス化するだけですが,35行目で Embedding層と出力層の
学習パラメータを初期化しています.
- 37-47行目: 学習パラメータ初期化処理
- 49-70行目: 推論処理
第1.4項で説明したとおり,nn.Embedding 層 (と出力層) のパラメータ初期化を reset_parameter() で行っている点に注意してください.
4.3 認識モデル
第1.1項で説明した認識モデル全体を次のコードで実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 | |
【コード解説】
- 引数
- in_channels: 入力特徴量の次元数
- inter_channels: 内部特徴量の次元数.
Encoder と Decoder で共通の値を用います.
- out_channels: 出力特徴量の次元数.
出力対象のラベル数に合わせます.
- padding_val: パディング信号のラベル値.
- activation: 活性化関数の種別を指定 [relu/gelu/swish/silu/mish]
- tren_num_layers: Encoder の層数
- tren_num_heads: Encoder 内部で使用する MHSA層のヘッド数
- tren_dim_ffw: Encoder 内部で使用する PFFN層の内部特徴次元数
- tren_dropout_pe: Encoder 内部で使用する PE層の Dropout層欠落率
- tren_dropout: Encoder 内部で使用する各 encoder層の Dropout層欠落率
- tren_norm_type_sattn: Encoder 内部で使用する MHSA層の正規化層種別を指定 [batch/layer]
- tren_norm_type_ffw: Encoder 内部で使用する PFFN層の正規化層種別を指定 [batch/layer]
- tren_norm_type_tail: Encoder ブロック末尾の正規化層種別を指定 [batch/layer]
- tren_norm_eps: Encoder 内部で使用するLN層の,0除算を避けるための定数
- tren_norm_first: Trueの場合,Pre-LN構成でencoder層を作成
- tren_add_bias: Trueの場合,線形変換層とLN層でバイアス項を適用.
ただし,LN層がバイアス項に対応していない場合 (古いPyTorch) は無視します.
- tren_add_tailnorm: この変数がTrueで,かつ,`tren_norm_first`がTrueの場合は末尾に
LN層を追加
- trde_num_layers: Decoder の層数
- trde_num_heads: Decoder 内部で使用する MHSA層と MHCA層のヘッド数
- trde_dim_ffw: Decoder 内部で使用する PFFN層の内部特徴次元数
- trde_dropout_pe: Decoder 内部で使用する PE層の Dropout層欠落率
- trde_dropout: Decoder 内部で使用する各 encoder層の Dropout層欠落率
- trde_norm_type_sattn: Decoder 内部で使用する MHSA層の正規化層種別を指定 [batch/layer]
- trde_norm_type_cattn: Decoder 内部で使用する MHCA層の正規化層種別を指定 [batch/layer]
- trde_norm_type_ffw: Decoder 内部で使用する PFFN層の正規化層種別を指定 [batch/layer]
- trde_norm_type_tail: Decoder ブロック末尾の正規化層種別を指定 [batch/layer]
- trde_norm_eps: Decoder 内部で使用するLN層の,0除算を避けるための定数
- trde_norm_first: Trueの場合,Pre-LN構成でencoder層を作成
- trde_add_bias: Trueの場合,線形変換層とLN層でバイアス項を適用.
ただし,LN層がバイアス項に対応していない場合 (古いPyTorch) は無視します.
- tren_add_tailnorm: この変数がTrueで,かつ,`tren_norm_first`がTrueの場合は末尾に
LN層を追加
- 33-86行目: 初期化処理
- 88-117行目: 学習時推論処理
- 119-174行目: テスト時推論処理
- 130-139行目: 特徴抽出と Encoder の適用
- 142-144行目: Decoderの入力ラベルを`<sos>`で初期化.
- 147-170行目: 推論メインループ.
`max_seqlen` でループを打ち切っている点に注意してください.変則的な入力が
与えられた場合や,モデルの学習が十分でない場合は`<eos>`が出力されず,
推論が中々終わらないケースがあります.
- 156-162行目: 時間軸に沿って応答値を積み上げていきます.
- 164-165行目: 応答値からラベル値へ変換し,次の Decoder への入力としています.
過去の推論結果と結合して,次の Decoder への入力としている点に注意してください.
- 169-170行目: `<eos>`が出力された場合は,推論処理を終了します.
5. 動作チェック
処理の実装ができましたので,動作確認をしていきます.
次のコードでデータセットから HDF5 ファイルと JSON ファイルのパスを読み込みます.
1 2 3 4 5 6 7 8 | |
gafs_dataset_very_small/character_to_prediction_index.json
[PosixPath('gafs_dataset_very_small/10.hdf5'), ..., PosixPath('gafs_dataset_very_small/68.hdf5')]
次のコードで辞書ファイルをロードして,認識対象のラベル数を格納します.
元々の認識対象に加えて,<sos>, <eos>, <pad> を加えている点に注意してください.
<pad> はパディング信号を示します.
1 2 3 4 5 6 7 8 9 10 11 | |
次のコードで前処理を定義します.
Colab 上のスクリプトは動作の流れを示すのが主目的なので,入力側のデータ拡張は最低限にして,ラベル挿入処理を前処理に加えています.
ラベル挿入処理に関しては,Encoder-Decoder 解説記事の第4.1項をご参照ください.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
次のコードで,前処理を適用した HDF5Dataset と DataLoader をインスタンス化し,データを取り出します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
torch.Size([2, 2, 409, 130])
tensor([[59, 10, 24, 24, 20, 12, 19, 17, 22, 16, 12, 23, 19, 22, 16, 20, 60, 61,
61, 61, 61, 61, 61, 61],
[59, 10, 19, 16, 12, 21, 24, 12, 24, 17, 20, 12, 16, 15, 12, 20, 23, 12,
24, 19, 16, 22, 24, 60]])
出力側のラベル系列に注目してください.
<sos>: 59 で始まり,指文字のラベルが続いた後 <eos>: 60 で終了します.
ラベル長が短いデータは,長いデータに合わせて <pad>: 61 で穴埋めされます.
次のコードでモデルをインスタンス化して,動作チェックをします.
追跡点抽出の結果,入力追跡点数は 130 で,各追跡点は XY 座標値を持っていますので,入力次元数は 260 になります.
出力次元数はラベルの種類数なので 62 です.
なお,第2節で説明した実験では,内部特徴量は \(80\) としています.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
TransformerCSLR(
(linear): Linear(in_features=260, out_features=64, bias=True)
(activation): ReLU()
(tr_encoder): TransformerEncoder(
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_sattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(norm_ffw): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(norm_tail): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(tr_decoder): TransformerDecoder(
(emb_layer): Embedding(62, 64, padding_idx=61)
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_sattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_cattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(norm_ffw): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(norm_tail): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(head): Linear(in_features=64, out_features=62, bias=True)
)
)
torch.Size([2, 24, 62])
6. 学習と評価の実行
6.1 共通設定
では,実際に学習・評価を行います.
まずは,実験全体で共通して用いる設定値を次のコードで実装します.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Using 2 cores for data loading.
Using cuda for computation.
孤立手話単語認識の場合とほとんど同じですが,テスト推論時の最長ループ数 max_seqlen を設定しています.
次のコードで学習・バリデーション・評価処理それぞれのための DataLoader クラスを作成します.
1 2 3 4 5 6 7 8 9 10 11 | |
6.2 学習・評価の実行
次のコードでモデルをインスタンス化します.
今回は時系列認識のためにカスタムした,LabelSmoothingCrossEntropyLoss をロス関数として使用します.
LabelSmoothingCrossEntropyLoss については Loss計算に関する補足記事で説明していますので,併せてご一読いただけたらうれしいです.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
TransformerCSLR(
(linear): Linear(in_features=260, out_features=64, bias=True)
(activation): ReLU()
(tr_encoder): TransformerEncoder(
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_sattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(norm_ffw): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(norm_tail): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(tr_decoder): TransformerDecoder(
(emb_layer): Embedding(62, 64, padding_idx=61)
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(layers): ModuleList(
(0-1): 2 x TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_sattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(w_key): Linear(in_features=64, out_features=64, bias=True)
(w_value): Linear(in_features=64, out_features=64, bias=True)
(w_query): Linear(in_features=64, out_features=64, bias=True)
(w_out): Linear(in_features=64, out_features=64, bias=True)
(dropout_attn): Dropout(p=0.1, inplace=False)
)
(norm_cattn): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(ffw): PositionwiseFeedForward(
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(activation): ReLU()
)
(norm_ffw): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(norm_tail): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(head): Linear(in_features=64, out_features=62, bias=True)
)
)
次のコードで学習・評価処理を行います.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
Start training.
--------------------------------------------------------------------------------
Epoch 1
Start training.
loss:4.439333 [ 0/ 2513]
Done. Time:9.448199940999984
Training performance:
Avg loss:3.754940
Start validation.
Done. Time:0.9230936449999945
Validation performance:
Avg loss:3.481351
Start test.
Done. Time:45.93940524999999
Test performance:
Avg WER:112.0%
--------------------------------------------------------------------------------
...
--------------------------------------------------------------------------------
Epoch 50
Start training.
loss:2.355552 [ 0/ 2513]
Done. Time:8.153878860000077
Training performance:
Avg loss:2.408425
Start validation.
Done. Time:0.9502329120000468
Validation performance:
Avg loss:2.546397
Start test.
Done. Time:52.02590661000022
Test performance:
Avg WER:79.4%
Minimum validation loss:2.546396642923355 at 50 epoch.
Minimum WER:78.10894972801826 at 47 epoch.
冒頭で説明したとおり,Colab 上で説明用に使っているデータセットは容量が少なくて学習が安定しません.
性能評価は公式から全データセットをダウンロードして行うことをお勧めします.
今回は Transformer Encoder-Decoder を用いた連続指文字認識モデルを紹介しましたが,如何でしたでしょうか?
今回の記事も実験にとにかく時間がかかりましたね (自分のミスで招いたところがほとんどですが (^^;)).
あまりマニアックな知識がなくても理解できるように,今まで実装上の細かなテクニックはなるべく避けるようにしていました.
ですが,モデルとタスクが複雑化するにつれて段々とキツくなってきましたね.
今後は (やり過ぎない範囲で (^^;)) 実装上の工夫や便利なフレームワークなども紹介していけたら良いなと思っています.
今回紹介した話が,これから手話認識や深層学習を勉強してみようとお考えの方に何か参考になれば幸いです.





